
Время на прочтение4 мин
Количество просмотров99K
Zabbix + Iostat: мониторинг дисковой подсистемы.

Зачем?
Дисковая подсистема одна из важных подсистем сервера и от уровня нагрузки на дисковую подсистему зачастую зависит очень многое, например скорость отдачи контента или то как быстро будет отвечать база данных. Это в большей степени относится к почтовым или файловым серверам, серверам БД. Вобщем, показатели дисковой производительности отслеживать нужно. На основании графиков производительности дисковой подсистемы мы можем принять решение о необходимости наращивания мощностей задолго до того как петух клюнет. Да и вобще полезно поглядывать от релиза к релизу как работа разработчиков сказывается на уровне нагрузки.
Под катом, о мониторинге и о том как настроить.
Зависимости:
Мониторинг реализован через zabbix агента и две утилиты: awk и iostat (пакет sysstat). Если awk идет в дистрибутивах по умолчанию, то iostat требуется установить с пакетом sysstat (тут отдельное спасибо Sebastien Godard и сотоварищи).
Известные ограничения:
Для мониторинга нужен sysstat начиная с версии 9.1.2, т.к. там есть очень важное изменение: «Added r_await and w_await fields to iostat’s extended statistics». Так что следует быть внимательным, в некоторых дистрибутивах, например в CentOS немного «стабильная» и менее фичастая версия sysstat.
Если же отталкиваться от версии zabbix (2.0 или 2.2) то тут вопрос не принципиален, работает на обоих версиях. На 1.8 не заработает т.к. используется Low level discovery.
Возможности (чисто субъективно, по мере убывания полезности):
- Low level discovery (далее просто LLD) для автоматического обнаружения блочных устройств на наблюдаемом узле;
- утилизация блочного устройства в % — удобная метрика для отслеживания общей нагрузки на устройстве;
- latency или отзывчивость — доступна как общая отзывчивость, так и отзывчивость на операциях чтения/записи;
- величина очереди (в запросах) и средний размер запроса (в секторах) — позволяет оценить характер нагрузки и степень загруженности устройства;
- текущая скорость чтения/записи на устройство в человекопонятных килобайтах;
- количество запросов чтения/записи (в секунду) объединенных при постановке в очередь на выполнение;
- iops — величина операций чтения/записи в секунду;
- усредненное время обслуживания запросов (svctm). Вообще она deprecated, разработчики обещают ее давно спилить, но все никак руки не доходят.
Вобщем как видно, здесь доступны все те метрики которые есть в iostat (кто незнаком с этой утилитой настоятельно рекомендую заглянуть в man iostat).
Доступные графики:
Графики рисуются per-device, LLD обнаруживает устройства которые попадают под регулярное выражение «(xvd|sd|hd|vd)[a-z]», так что если ваши диски имеют другие имена, можно легко внести соответствующие изменения. Такая регулярка сделана чтобы обнаруживать устройства которые будут родительскими по отношению к прочим разделам, LVM томам, MDRAID массивам и т.п. Вобщем чтобы не собирать лишнего. Немного отвлеклись, итак список графиков:
- Disk await — отзывчивость устройства (r_await, w_await);
- Disk merges — операции слияния в очереди (rrqm/s, wrqm/s);
- Disk queue — состояние очереди (avgrq-sz, avgqu-sz);
- Disk read and write — текущие значения чтения/записи на устройство (rkB/s, wkB/s);
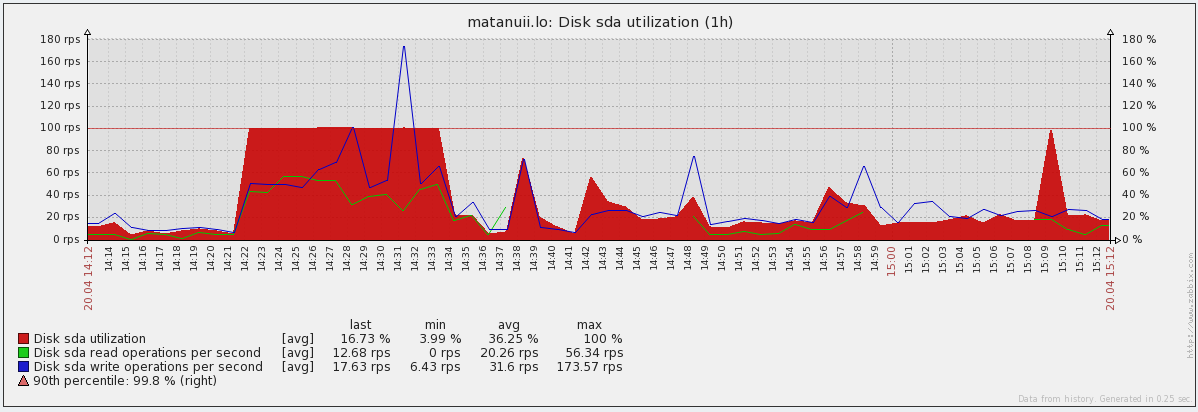
- Disk utilization — утилизация диска и значение IOPS (%util, r/s, w/s) — позволяет неплохо отслеживать скачки в утилизации и чем, чтением или записью они были вызваны.
Аналоги и отличия:
В заббиксе есть коробочные варианты для похожего мониторинга, это ключи vfs.dev.read и vfs.dev.write. Они хороши и прекрасно работают, но менее информативны чем iostat. Например в iostat есть такие метрики как latency и utilization.
Также есть аналогичный шаблон от Michael Noman на мой взгляд отличие только одно, она заточена на старые версии iostat, ну и + небольшие синтаксические изменения.
Где взять:
Итак, мониторинг состоит из файла конфигурации для агента, двух скриптов для сбора/получения данных и шаблон для веб-интерфейса. Все это доступно в репозитории на Github, поэтому любым доступным способом (git clone, wget, curl, etc…) скачиваем их на машины которые хотим замониторить и переходим к следующему пункту.
Как настроить:
- iostat.conf — содержимое этого файла следует поместить в файл конфигурации zabbix агента, либо положить в каталог конфигурации который указан в Include опции основной конфигурации агента. Вобщем зависит от политики партии. Я использую второй вариант, для кастомных конфигов у меня отдельная директория.
- scripts/iostat-collect.sh и scripts/iostat-parse.sh — эта два рабочих скрипта следует скопировать в /usr/libexec/zabbix-extensions/scripts/. Тут также можно использовать удобное вам размещение, однако в таком случае не забудьте поправить пути в параметрах определенных в iostat.conf. Не забудьте проверить что они исполняемы (mode=755).
Теперь все готово, запускаем агента и переходим на сервер мониторинга и выполняем команду (не забываем подменить agent_ip):
# zabbix_get -s agent_ip -k iostat.discovery
Таким образом, проверяем с сервера мониторинга что iostat.conf подгрузился и отдает информацию, заодно смотрим что LLD работает. В качестве ответа вернется JSON с именами обнаруженных устройств. Если ответа не пришло, значит что-то сделали не так.
Также есть такой момент, что zabbix server не дожидается выполнения некоторых item’ов со стороны агентов (iostat.collect). Для этого следует увеличить значения Timeout.
Как настроить в web интейрфейс:
Теперь остался шаблон iostat-disk-utilization-template.xml. Через веб интерфейс импортируем его в раздел шаблонов и назначем на наш хост. Тут все просто. Теперь остается ждать примерно один час, такое время установлено в LLD правиле (тоже настраивается). Или можно поглядывать в Latest Data наблюдаемого хоста, в раздел Iostat. Как только там появились значения, можно перейти в раздел графиков и понаблюдать за первыми данными.
И напоследок тройка скринов графиков c локалхоста))):
Непосредственно данные в Latest Data:
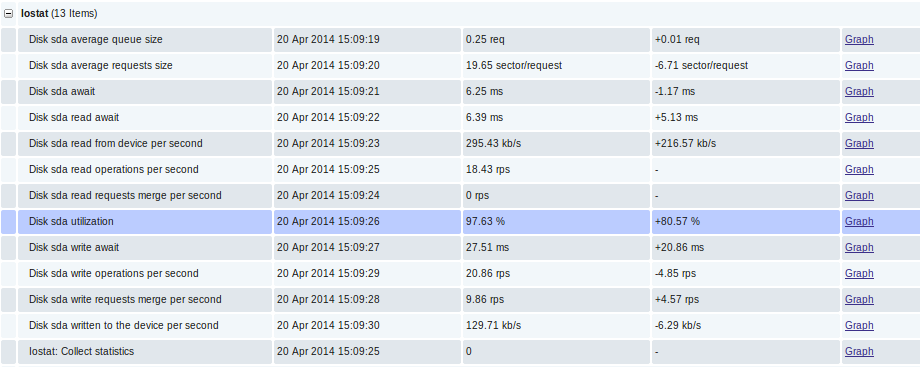
Графики отзывчивости (Latency):
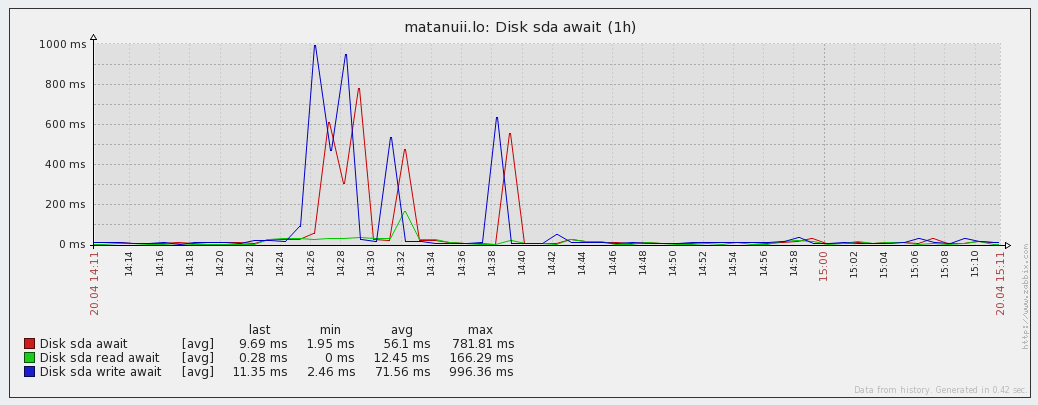
График утилизации и IOPS:
Вот и собственно и все, спасибо за внимание.
Ну и по традиции, пользуясь случаем передаю привет Федорову Сергею (Алексеевичу) 
Skip to content
Navigation Menu
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
Appearance settings

Прошлый раз мы рассмотрели мониторинг в zabbix Linux IOPS при помощи iostat.
Сегодня мы попробуем сделать тоже самое, но уже в windows окружении.
Windows в фоновом режиме самостоятельно обсчитывает определенный набор метрик, делается это через «Perfomance Monitor» доступ к которому в zabbix реализуется через функцию «perf_counter».
На вход perf_counter получает «имя» счетчика, и это первый подводный камень.
В Интернете можно найти несколько вариантов обозначения одного и того же счетчика, например:
perf_counter[\PhysicalDisk(_Total)\Disk Reads/sec] perf_counter[\Физический диск(_Total)\Обращений чтения с диска/с] perf_counter[\234(_Total)\214]
Несмотря на различия, это действительно один и тот же счетчик.
Первый два характерны для разных локаций windows и использовать их в мониторинге мы не будем, т.к. под русской windows не будут работать английские счетчики и наоборот.
Третий вариант стоит назвать универсальным, т.к. он работает везде, но «overhead» в интуитивной непонятности обозначений.
Несколько вариантов получить счетчики:
typeperf -qx lodctr /s:perfcount.txt
В «lodctr» мы видим сопоставление цифр и названий счетчиков:
234 - PhysicalDisk 236 - LogicalDisk

Или в виде удобной таблицы: Techwiki:Performance Counter Indexes
В качестве примера, я сделал шаблон для «Disk I/O Operations» и «File I/O Operations» диска «Total». Особенность шаблона, что он не требует никаких изменений конфигурации zabbix на клиентах.
https://github.com/spions/zabbix/tree/master/zabbix_Windows_IOPS
Disk I/O Operations

График показывает общее количество операций ввода\вывода, обработанных (завершенных) диском в течении 1 секунды (Input/Output Operations Per Second, IOPS). Этот счетчик позволяет примерно оценить, насколько нагрузка на диски близка к предельной.
File I/O Operations

Если нужна расшифровка по всем дискам, то уже потребуется изменение конфигурации zabbix, путем добавления нового UserParameter: объявляем переменную windowsdisk.discovery с запуском powershell скрипта:
UserParameter=windowsdisk.discovery, powershell -NoProfile -ExecutionPolicy Bypass -File c:\get_disks.ps1
get_disks.ps1:
https://github.com/spions/zabbix/blob/master/zabbix_Windows_IOPS/files/get_disks.ps1
$drives = Get-WmiObject win32_PerfFormattedData_PerfDisk_PhysicalDisk | ?{$_.name -ne "_Total"} | Select Name
$idx = 1
write-host "{"
write-host " `"data`":[`n"
foreach ($perfDrives in $drives)
{
if ($idx -lt $drives.Count)
{
$line= "{ `"{#DISKNUMLET}`" : `"" + $perfDrives.Name + "`" },"
write-host $line
}
elseif ($idx -ge $drives.Count)
{
$line= "{ `"{#DISKNUMLET}`" : `"" + $perfDrives.Name + "`" }"
write-host $line
}
$idx++;
}
write-host
write-host " ]"
write-host "}"
Результатом будет json с количеством дисков:
{
"data":[
{ "{#DISKNUMLET}" : "0 C:" }
]
}
На основе данного discovery можно снимать необходимое вам количество метрик и строить графики, но это тема для отдельного поста.
Вы можете оставить комментарий ниже.
Для того, чтобы при помощи активного агента Zabbix следить за дисковым пространством компьютера, как оказалось, не нужно писать скриптов. Совсем. 🙂 Все уже умеет делать активный Zabbix-агент «из коробки». Достаточно создать шаблон и назначить его компьютеру. Всё.
А теперь по порядку.
Дано.
Сферический компьютер в вакууме. Нужно следить за заполненностью системного диска Windows. Предположим, что у нас всё стандартно, поэтому в качестве буквы системного диска используется «C:».
Решение.
При помощи активного агента Zabbix будем собирать 4 параметра диска «C:»:
- общий размер диска
- размер занятого места
- размер свободного места
- процент свободного места.
На основании этих параметров создадим 4 триггера:
- Предупреждение. Свободно менее 20%
- Средняя важность. Свободно менее 10%
- Высокая важность. Свободно менее 1 Гб.
- Чрезвычайная важность. Свободно менее 100 Мб.
И создадим 2 графика:
- Размер свободного места
- Размер свободного места в процентах.
Создаём шаблон.
Имя шаблона: Active Computer — SystemDrive
Группа данных: Filesystems
Элементы данных:
- SystemDriveSizeFree — vfs.fs.size[«c:»,free]
- SystemDriveSizePFree — vfs.fs.size[«c:»,pfree]
- SystemDriveSizeTotal — vfs.fs.size[«c:»,total]
- SystemDriveSizeUsed — vfs.fs.size[«c:»,used]
Триггеры:
- Предупреждение. Меньше 20% свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,pfree].last()}<20
- Средняя .Меньше 10% свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,pfree].last()}<10
- Высокая. Меньше 1ГБ свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,free].last()}<1073741824
- Чрезвычайная. Меньше 100 Мб свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,free].last()}<104857600
Теперь то же самое, но в картинках.














Файл с экспортированным шаблоном можно скачать тут: zbx_export_templates_Active_Computer_SystemDrive.xml
Назначаем шаблон компьютеру
И начинаем получать данные… 🙂

Ура!!!
Всё работает.
A few years ago we moved from Nagios to Zabbix for our server monitoring needs. I wasn’t a big fan of Nagios, finding it a pain to manage with its myriad configuration files. It’s probably gotten better since I last toyed with it but since we moved to Zabbix I haven’t had much reason to look at Nagios again.
I also try to use SNMP monitoring for everything. SNMP is widely supported – all sorts of hardware has SNMP support, and with the net-snmp package you can pretty easily create your own SNMP-monitorable stuff on Linux. Since almost all of our stuff runs on Linux this has worked out pretty well, but our Exchange server is probably going to be running on Windows for the foreseeable future. Windows has SNMP support, it’s just not on by default. However, even when it’s enabled it doesn’t have the simple “dskPercent” monitoring I’ve come to know and love with net-snmp on Linux, which simply tells you how full a given disk is as a percent. This makes it easy to set alerts when a disk reaches 80% full.
On Windows I found these objects that can be used to get something similar:
[evan@monitoring02 14:41:24 ~]$ snmpwalk -v 2c -c community 192.168.1.20 | grep -i storage HOST-RESOURCES-MIB::hrStorageIndex.1 = INTEGER: 1 HOST-RESOURCES-MIB::hrStorageIndex.2 = INTEGER: 2 HOST-RESOURCES-MIB::hrStorageIndex.3 = INTEGER: 3 HOST-RESOURCES-MIB::hrStorageIndex.4 = INTEGER: 4 HOST-RESOURCES-MIB::hrStorageIndex.5 = INTEGER: 5 HOST-RESOURCES-MIB::hrStorageIndex.6 = INTEGER: 6 HOST-RESOURCES-MIB::hrStorageType.1 = OID: HOST-RESOURCES-TYPES::hrStorageRemovableDisk HOST-RESOURCES-MIB::hrStorageType.2 = OID: HOST-RESOURCES-TYPES::hrStorageFixedDisk HOST-RESOURCES-MIB::hrStorageType.3 = OID: HOST-RESOURCES-TYPES::hrStorageCompactDisc HOST-RESOURCES-MIB::hrStorageType.4 = OID: HOST-RESOURCES-TYPES::hrStorageFixedDisk HOST-RESOURCES-MIB::hrStorageType.5 = OID: HOST-RESOURCES-TYPES::hrStorageVirtualMemory HOST-RESOURCES-MIB::hrStorageType.6 = OID: HOST-RESOURCES-TYPES::hrStorageRam HOST-RESOURCES-MIB::hrStorageDescr.1 = STRING: A:\ HOST-RESOURCES-MIB::hrStorageDescr.2 = STRING: C:\ Label: Serial Number b78d19 HOST-RESOURCES-MIB::hrStorageDescr.3 = STRING: D:\ Label:EXCH201064 Serial Number xxxxxxxx HOST-RESOURCES-MIB::hrStorageDescr.4 = STRING: E:\ Label:Exchange2010 Serial Number xxxxxxxx HOST-RESOURCES-MIB::hrStorageDescr.5 = STRING: Virtual Memory HOST-RESOURCES-MIB::hrStorageDescr.6 = STRING: Physical Memory HOST-RESOURCES-MIB::hrStorageAllocationUnits.1 = INTEGER: 0 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.2 = INTEGER: 4096 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.3 = INTEGER: 2048 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.4 = INTEGER: 4096 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.5 = INTEGER: 65536 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.6 = INTEGER: 65536 Bytes HOST-RESOURCES-MIB::hrStorageSize.1 = INTEGER: 0 HOST-RESOURCES-MIB::hrStorageSize.2 = INTEGER: 10459647 HOST-RESOURCES-MIB::hrStorageSize.3 = INTEGER: 546570 HOST-RESOURCES-MIB::hrStorageSize.4 = INTEGER: 104824319 HOST-RESOURCES-MIB::hrStorageSize.5 = INTEGER: 393172 HOST-RESOURCES-MIB::hrStorageSize.6 = INTEGER: 196600 HOST-RESOURCES-MIB::hrStorageUsed.1 = INTEGER: 0 HOST-RESOURCES-MIB::hrStorageUsed.2 = INTEGER: 5885720 HOST-RESOURCES-MIB::hrStorageUsed.3 = INTEGER: 546570 HOST-RESOURCES-MIB::hrStorageUsed.4 = INTEGER: 44650892 HOST-RESOURCES-MIB::hrStorageUsed.5 = INTEGER: 166057 HOST-RESOURCES-MIB::hrStorageUsed.6 = INTEGER: 152902
I thought initially that the hrStorageUsed and hrStorageSize values were being reported in bytes, but according to this MSDN article, the units are reported in “allocation units,” which I assume are being reported under hrStorageAllocationUnits, so you just need to multiply the values by the allocation units.
In Zabbix, I check hrStorageUsed every 15 minutes as “disk_1_used”. I check hrStorageSize every 2 hours (since the actual size of the disk/partition isn’t likely to change that often) as “disk_1_size”. To calculate the percentage, I created a “Calculated” item with this formula:
100*(last("disk_1_used") / last("disk_1_size"))

The values for disk_1_used and disk_1_size are in Storage Allocation Units, but since this is a percentage that doesn’t matter. However, I do also like to get an idea of the actual disk space being consumed; luckily this is also relatively easy to obtain in Zabbix using Calculated items. I monitor hrStorageAllocationUnits as “disk_1_allocunit” (every 7200 seconds since this too is unlikely to change much) and then the formula for the calculated used disk space is simply:
last("disk_1_used") * last("disk_1_allocunit")
")
Once all the work is done, here’s what the result looks like:
When I log in to the actual machine (my vCenter VM in this case) and check disk usage, the numbers match what Zabbix’s calculated values show, though Zabbix seems to be reporting values in “mebibytes” rather than “megabytes”:
I created a template in Zabbix which monitors these data for disks 1-5 and then applied it to all Windows servers; now I just need to apply some alert triggers and mission accomplished.