
Время на прочтение4 мин
Количество просмотров32K
Привет, Хабр! Уже много лет я читаю замечательные посты, и, кажется, наконец нашел чем сам могу поделиться с сообществом.
Сегодня я хотел бы рассказать про технологию создания программного гибридного локального диска на основе SSD и HDD. Впервые я заинтересовался этой технологией когда купил себе новый процессор от Ryzen и прочитал статью про AMD StoreMI, но к сожалению поддержка данного продукта прекратилась, а покупать FuzeDrive или PrimoCache не хотелось.
upd. оказывается AMD выпустили вторую версию StoreMI, хотя еще недавно заявляли что прекращают поддержку. Напомню, что StoreMI работает только при наличии материнской платы с чипсетом AMD X570, B550, 400 серии, X399 или TRX40.
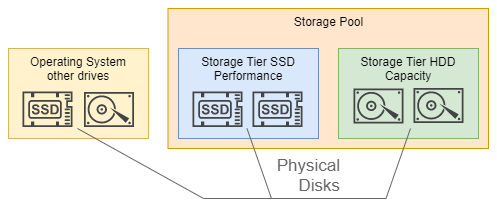
В серверных версиях windows существует весьма интересная технология Tiered Storage Spaces, которая позволяет легко объединять один или несколько SSD и HDD в общий пул — логический диск, на котором часто используемые “горячие” данные будут незаметно для пользователя переноситься на SSD, а “холодные” данные, к которым пользователь обращается не так часто, будут при этом храниться на HDD. Про настройку данной технологии на серверных продуктах можно почитать тут по ссылке, также уже существует несколько статей на Хабре. Но, как оказалось, данная технология присутствует также и на настольной версии windows, правда настраивается она только через командную строку так как нет GUI. Для упрощения этого процесса существует репозиторий со скриптами, которые позволяют автоматизировать процесс создания tier storage.
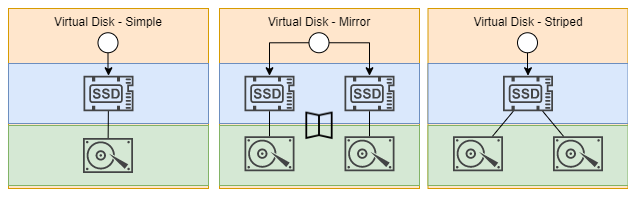
Для хранения важных данных не рекомендуется использовать конфигурации windows storage spaces с выключенным mirroring. Mirroring позволяет создать массив RAID c функцией коррекции ошибок, которая должна помочь сохранить данные в случае поломки одного из дисков, но для этого необходимы дополнительные диски, объем которых не получится использовать для хранения данных.
Перейдем к делу
Для начала советую запустить PowerShell от имени администратора и использовать команду
Get-PhysicalDiskПараметр CanPool должен соответствовать Trueоколо всех ваших SSD и HDD, которые вы хотите добавить в пул. Если по запросу команды Get-PhysicalDisk у одного из ваших накопителей, которые вы хотите добавить в пул будет состояние False, то необходимо при помощи утилиты diskpart запущенной от имени администратора выполнить команды:
list disk #выбрать номер нужного диска, для примера диск 2
select disk 2
clearА затем в Powershell запущенной от имени администратора выполнить команду:
Reset-PhysicalDisk ST2000DM008-2FR102 где ST2000DM008-2FR102 — это параметр friendly name диска, который вы хотите вернуть в состояние True. Обратите внимание, что диски, у которых значение CanPoolравно True будут отформатированы в процессе выполнения скрипта, и, если вы не хотите добавлять их в пул, то необходимо заранее отсоединить эти диски, либо переписать скрипт.
Затем просто клонируйте репозиторий, и запустите запустите скрипт new-storage-space.ps1 Во время выполнения закройте окна, которые будут предлагать вам отформатировать диск, и ждите завершения скрипта.
По поводу того, что будет, если один из дисков пула отвалится. Я пытался просто отключать SSD на выключенном компьютере и, к сожалению, до тех пор пока я его не присоединил SSD обратно и не перезагрузил компьютер, локальный диск не был виден в системе (думал может хотя бы данные, которые были на HDD отображаться будут, но нет).
А что там по скорости?
Автор репозитория указал следующие скорости при тестировании системы:

Также интересным мне показалось сравнение из этого видео на youtube.
Я сам не производил тестирования на чтение, но сравнивал скорость записи на чистый 2 Тб HDD Seagate BarraCuda 7200 rpm и 256 MB cache, и tier storage space из этого же HDD диска и SSD Crucial BX500 на 240 Гб.
При копировании больших файлов (установленный stalker anomaly, который почти полностью состоит из больших файлов .db размером примерно в 1 Гб) storage tier изначально копировал на скорости чуть более 400 Мб/сек, но затем, скорость копирования опускалась до 110 Мб/сек, что даже меньше чем скорость записи на HDD без storage tier (160 Мб/сек на тех же файлах).
К сожалению, в тот момент когда я производил тесты я не думал что буду писать статью и не догадался использовать snipping tool а просто делал фото на телефон.

Зато, при копировании порядка 10 Гб стандартных фоток (размер одной примерно 4-5 Мб) storage tier практически стабильно имел скорость порядка 260 Мб/сек против скачущих 180 Мб/сек у HDD.
Для того чтобы посмотреть какой процент данных на самом деле сейчас находится именно на SSD диске нужно в PowerShell с правами администратора запустить:
defrag D: /g /h /#Наиболее интересными для нас тут являются параметры Percent of total I/Os serviced from the Performance tier — процент данных, которые при чтении были считаны именно с SSD. Также в таблице можно увидеть зависимость процента данных, которые будут взяты с высокопроизводительного накопителя от минимальной требуемой емкости SSD диска.

Для создания задачи автоматической оптимизации используется команда
Get-ScheduledTask -TaskName "Storage Tiers Optimization" | Start-ScheduledTaskМодификация скрипта
После произведенных тестов мне захотелось изменить несколько вещей. Первое — отдельно изменять процент неиспользуемого места на дисках, так как даже 1 процент от 2 Тб диска это 20 Гб. (объяснение почему нельзя использовать весь диск можно найти тут). По итогу экспериментальным путем при моих параметрах удалось добиться всего 0.13 процента неиспользуемого места на жестком диске.
Во-вторых, я пытался изменить размер параметра WriteCacheSize для увеличения скорости записи данных на tiered storage, но к сожалению даже установив размер в 20 Гб, скорость записи совершенно не отличалась от дефолтного параметра AutoWriteCacheSize (при котором размер WriteCacheSize равен 1 Гб).
Также я нашел информацию, что можно использовать параметр представленный ниже для увеличения скорости, но это может быть небезопасно с точки зрения хранения данных.
Set-StoragePool -FriendlyName "SSHD Storage Pool" -IsPowerProtected $TrueВсе мои изменения для удобства я залил в свой репозиторий на github.
Выводы
Как я уже отметил выше, не стоит хранить важные данные, если вы используете схожую с моей конфигурацию 1 SSD 1 HDD (без использования Mirroring). Но для хранения не особо нужных тестовых виртуальных машин, игр, фильмов, и другой локальной файловой помойки такое решение подходит отлично. Загрузка игр заметно ускоряется, и обычно со второго запуска скорость на глаз не отличима от запуска с SSD.

SSD-диски все еще дороги. Цена на них постепенно понижается, но на единицу хранения они пока еще не могут конкурировать с традиционными HDD. Последние, кстати, вовсе не собираются сдавать свои позиции. И дело не только во все увеличивающихся объемах хранения и снижающейся стоимостью записи на HDD. Традиционные HDD обеспечивают куда большую надежность хранения данных на протяжении длительного времени и существенно большую износостойкость в плане записи. И эти свойства HDD появились не вчера, их планомерно развивали в течение десятилетий. К надежности хранения данных на HDD можно привести множество примеров, когда в различных НИИ и замшелых банках все еще используются жесткие диски выпущенные десятки лет тому назад. И при этом они полностью сохранили свою работоспособность. Кстати, ленточные накопители тоже остались у дел, в тех же банках, финансовых компаниях, замшелых НИИ. Магнитные ленты отлично выполняют функции по архивному хранению информации, например, резервных копий и по самой минимальной стоимости при высочайшей надежности.
Но есть у HDD и неоспоримые недостатки. Это все, что связано со временем доступа и вообще скоростью чтения и записи данных. Конечно, HDD почти что космические ракеты, если сравнить их с решениями на магнитной ленте, но скорости HDD, в нынешних реалиях, все равно недостаточно. По сути, это самый медленный компонент современного ПК. Именно по этой причине на свет появились SSD. Они лишены механической части и соответственно недостатков, связанных со временем доступа и скоростями чтения/записи. В SSD все эти операции происходят «мгновенно» и с максимально доступной производительностью.
А можно ли совместить достоинства HDD и SSD дабы нивелировать их недостатки? Как оказывается можно. Еще до появления SSD обычные HDD уже оснащались крупными буферами из оперативной памяти для ускорения операций чтения-записи. Данная технология помогала лишь отчасти, в основном для операций связанных с записью данных, либо на очень медленных компьютерах, где интерфейс не мог переварить поставляемый жестким диском объем данных. Чуть позже появились комбинации, когда HDD дооснащался еще и небольшим встроенным SSD. SSD-часть в этом случае использовалась как SSD-кэш. Большой популярности подобные решения не нашли, так как объемы SSD встраивались небольшие, а износу они подвергались существенному. Но производители пошли дальше.
На сцену вышла концепция, декларирующая ранжирование данных на дисковом массиве по важности быстрого доступа к ним. Ведь какие-то фотографии с позапрошлогоднего отпуска, можно вполне себе хранить хоть на ленте, а вот файл динамичной игры должен подгружать как можно быстрее. В этой стезе засветилась корпорация Intel, разработавшая совместно с Micron новый вид памяти для твердотельных дисков. Для конечного потребителя новинка предстала под торговой маркой Optane и предназначалась как раз для ускорения операций ввода-вывода традиционных HDD. Иначе работала как «умный» SSD-кэш. Да, кстати, объемы Optane-дисков, как правило, были небольшими, а стоимость соответствовала амбициям электронных гигантов.
Но технологии не стоят на месте, а неумолимо приближаются к технологической сингулярности. Усилиями многих производителей SSD-диски становятся все дешевле и быстрее. И вот в некоторых компьютерах есть только просто SSD-диск и больше ничего. Но, а в мощных рабочих станциях, игровых ПК, да и в большинстве ПК, что стоят на производствах, в офисах и просто по домам разнокалиберных граждан, по-прежнему присутствуют HDD. И вроде бы компьютеры не старые, вполне рабочие, но дисковая подсистема основанная на HDD оставляет желать лучшего, а выкинуть вполне еще рабочий HDD на терабайт, ну просто, рука не поднимается. Но и тут есть решение. Можно использовать технологию по созданию автоматических tiered drives (или иерархичных дисков, лучшего русскоязычного термина я не подобрал). В основе технологии tiered drives лежит объединение быстрых, но небольших SSD-дисков, и медленных, но надежных и объемных HDD-дисков, в один виртуальный пул, тем самым устраняя недостатки каждой из технологий хранения данных.
Автоматичность в случае с tiered drivers означает, что система сама, самостоятельно, без всякого AI, SMS и регистраций, будет определять, какие данные следует помещать на быструю часть (SSD), а какие разумнее оставить на HDD. В некоторых реализациях можно дополнительно «привязывать» те или иные файлы к быстрой части виртуального пула или медленного. Кроме того, некоторые производители дополнительно оснащают свои программные решения по организации tiered drives еще и дополнительным кэшем в оперативной памяти, для еще большей производительности. Но, прежде чем перейти к разбору программным продуктов «без SMS и регистраций», необходимо разобраться в отличиях между SSD-cache, RAID-массивами и tiered drives.
SSD-cache – простой механизм по прозрачному кэшированию данных на быстром SSD-диске перед их записью на медленный HDD-диск, либо аналогичное кэширование данных при чтении. Все зависит от реализации. Технология интересная, но особого признания не нашла в силу очень узкой специализации. Небольшое количество данных она запишет быстро, а вот с чем покрупнее никакого преимущества уже не будет.
RAID-массив — механизм объединения нескольких физических дисков в единый пул. Способ объединения зависит от потребности, но в основном используется в промышленных системах хранения данных, где требуется высокая надежность хранения и низкий процент отказов с нулевым простоем. Как правило в массив объединяются одинаковые по характеристикам диски.
Tiered drive — механизм разделения данных на требующих и не требующих быстрого доступа с соответствующим местом хранения на SSD или HDD.
AMD StoreMI
Мое первое знакомство с tiered drives началось с AMD StoreMI. Еще с первой версии, перелицованной enmotus FuzeDrive. Перейдя с Intel на платформу AMD, я с удовольствием обнаружил, что весь мой парк старых HDD можно безболезненно использовать с моим новым ПК, а заодно и ускорить их до самого доступного максимума при помощи освободившихся SATA SSD (а основными рабочими дисками у меня стали NVME PCI накопители).
Первая версия StoreMI имела существенные ограничения, так, например, можно было использовать для создания tiered drive SSD размером не более 256 Гб. Хорошо, что у меня был именно такой диск. Система tiered drive собралась оперативно, скорость работы с HDD выросла до адекватных показаний, все бегало и приятно урчало. Но локальный праздник жизни был омрачен двумя факторами:
- Система падала из-за StoreMI при высокой нагрузке. Например, при копировании данных с HDD на tiered drive от StoreMI.
- Спустя некоторое время AMD убрала StoreMI первой версии из открытого доступа, а никакой замены не предложила. Другими словами, если вам потребовалось восстановить систему, в которой присутствует tiered drive StoreMI, то все данные вы потеряете на этом диске, так как подключиться к нему никак.
В качестве дополнительного удобства я несколько раз получал заблокированный tiered drive, так как StoreMI не могла проверить свою лицензию. Ну и полностью отсутствующая поддержка по продукту означала, что использовать его можно только на свой страх и риск. Из плюсов, что были в первой версии StoreMI, можно отметить лишь наличие дополнительно кэша в оперативной памяти, что несколько ускоряло работу всей связки.
Чуть позже AMD выпустила вторую версию StoreMI уже без всяких ограничений на объемы дисков и прочей ереси в виде лицензий. Вторая версия оказалась несовместимой с первой. Провести апгрейд — нельзя. По всей видимости это связано с тем, что вторая версия StoreMI уже была написана без специалистов enmotus. Интерфейс хоть и стал чуть более лицеприятным, но все также отдавал Delphi.
Вторую версию StoreMI я установил на свой второй компьютер, первую установить я на него не успел, апгрейд закончился позже, чем появилась обновленная StoreMI. Установку удалось завершить далеко не с первой попытки. Пришлось ждать около полугода, пока появятся исправления и StoreMI наконец-то заработает и на моем втором ПК.
Вообще, драйвера дисковых подсистем штука до крайности важная. Они не должны содержать никаких ошибок, а их код должен быть «вылизан» программистами и тестировщиками до последнего байта. Ведь малейшая, даже самая крохотная ошибка в программном обеспечении дисковой подсистемы способна привести к краху ценных данных. Ваших данных. И именно по этой причине, мы меняем программное обеспечение как перчатки, но все еще продолжаем работать с файловыми системами, разработанными в прошлом веке. Лучше оставаться на проверенной системе, хоть и чуть медленнее, чем терять свои данные.
Но вернемся к StoreMI второй версии. Через некоторое время использования я с удивлением заметил, что некоторые фотографии, которые я синхронизирую с компьютером оказываются испорченными. Хотя на всех других устройствах они открываются и читаются без особых проблем. Фотографии, как не трудно догадаться, хранятся как раз на диске StoreMI. Дабы отвести напрасные мысли о ненадежности второй версии StoreMI, я решил переустановить Windows.
Но, после первой же перезагрузки после установки второй версии StoreMI (и даже без создания tiered drive) моя установка Windows становилась полностью неработоспособной. UEFI (BIOS) напрочь отказывался видеть загрузочный диск, а инсталляционная утилита Windows не обнаруживала никаких признаков установленной операционки для восстановления. Проведя подряд 7 переустановок операционной системы, я окончательно убедился, что проблема как раз в StoreMI от AMD.
В общем, пришлось идти, искать альтернативу. Ведь к хорошему быстро привыкаешь.
enmotus FuzeDrive
Естественным первым порывом стало желание посмотреть на родную утилиту для организации tiered drives от производителя первой версии StoreMI. Ведь она худо, но все же продолжала работать, тянуть мой домашний комп.
Неоспоримым преимуществом FuzeDrive является наличие RAM-кэша, который дополнительно ускоряет операции записи в системе. Данные сначала записываются в быструю оперативную память, а потом уже отправляются на tiered-диск по мере возможности. Но мой опыт работы с первой версией StoreMI, проблемы с лицензией и аварийные остановки операционные системы при высокой нагрузке на дисковую подсистему несколько охладили мой пыл в отношении FuzeDrive. Пошли искать альтернативу дальше.
ROMEX PrimoCache
Альтернативой FuzeDrive для Windows можно считать PrimoCache от ROMEX. Утилита PrimoCache — применяется как продвинутое решение для кэширования данных при чтении или записи с медленных устройств. В качестве быстрых устройств, используемых для кэширования, в PrimoCache можно применять ОЗУ, SSD-диск и даже Flash-диски. Кстати, в Windows уже есть технология по ускорению медленных накопителей за счет использования кэширования на USB Flash-дисках. Но решение ReadyBoost, опять же, не стало популярным. Ускорение за счет USB-флешки медленного HDD, установленного в медленном компьютере, обычно приводило к еще большим тормозам, так как на обработку данных с Flash-дисков тратились дополнительные ресурсы, которых и так было мало.
Но вернемся к PromiCache. Тут следует учитывать, что это именно кэш, т.к. данные всегда проходят через «быстрое» устройство.
Благодаря такому активному кэшированию при помощи PrimoCache можно получать фантастические скорости общения с жестким диском. Еще одним преимуществом PrimoCache можно считать отсутствие необходимости в переносе данных с «медленного» носителя перед включением его кэширования. Т.е. установка утилиты — максимально безопасна. Кстати, PrimoCache можно скачать на попробовать, в приложении присутствует «триальный» период.
К сожалению, никакой функции по ранжированию данных по иерархии хранения в PrimoCache нет, поэтому ее не следует рассматривать как прямого конкурента StoreMI или FuzeDrive.
При дальнейшем исследовании можно обнаружить, что на рынке присутствует некоторое количество RAM-cache утилит, предоставляющих примерно один и тот же сервис под разными названиями. Не будем их всех перечислять, а перейдем сразу к герою настоящей статьи, а именно…
Служба Storage Spaces появилась в Windows Server 2012 как способ объединения физических дисков в единые пулы, на основе которых могут быть организованы виртуальные диски. Данная же технология мигрировала с Windows Server 2012 и на Windows 8.
Изначально в Storage Spaces были доступны следующие варианты объединения:
- Simple — дисковое пространство всех дисков объединяется в одно.
- Two-way mirror — обычное зеркалирование данных по дискам, всего хранится две копии.
-
Three-way mirror — усиленное зеркалирование данных по дискам, всего хранится три копии.
Получался эдакий аналог программного RAID встроенного в операционную систему. Позже, с выходом Windows Server 2012 R2 появились дополнительные виды объединения дисков:
- Parity — хранение данных с избыточной информацией необходимой для восстановления. Данные «размазываются» сразу по нескольким дискам и в случае выхода из строя части дисков, данные все равно можно будет восстановить благодаря избыточности.
- Tiered — как раз интересующий нас случай с поддержкой иерархического хранения и сегрегации данных на быстрые и медленные носители.
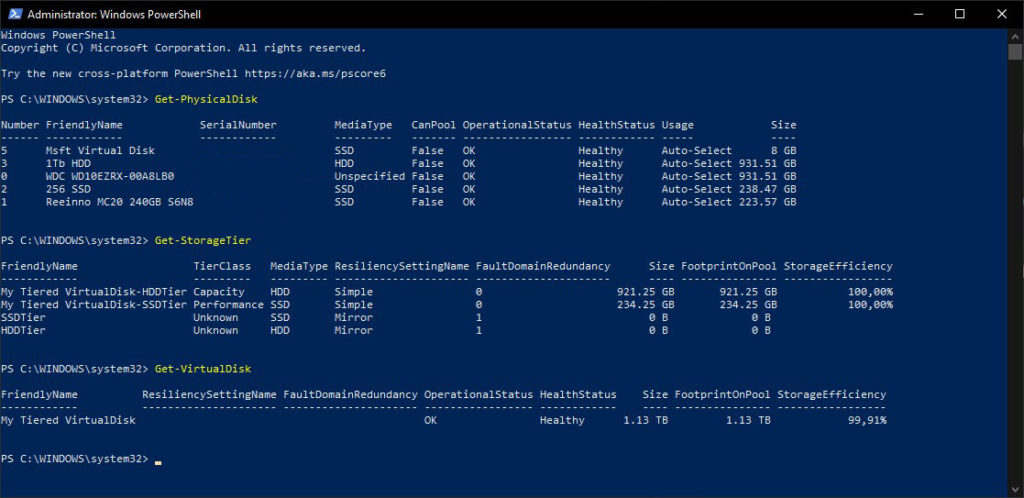
Состояние дисковой подсистемы после создания Tiered Drive из двух дисков
Последняя редакция также была перенесена в десктопные решения. Создание и управление пулами дисков и виртуальными дисками под Windows 10 (Widows 8 рассматривать уже не будем по причине старости) доступно через апплет (оснастку) Storage Spaces, либо через команды в среде Windows PowerShell. К сожалению, в оснастке Storage Spaces доступны все варианты создания объединения, за исключением Tiered. Он доступен только через команды в PowerShell.
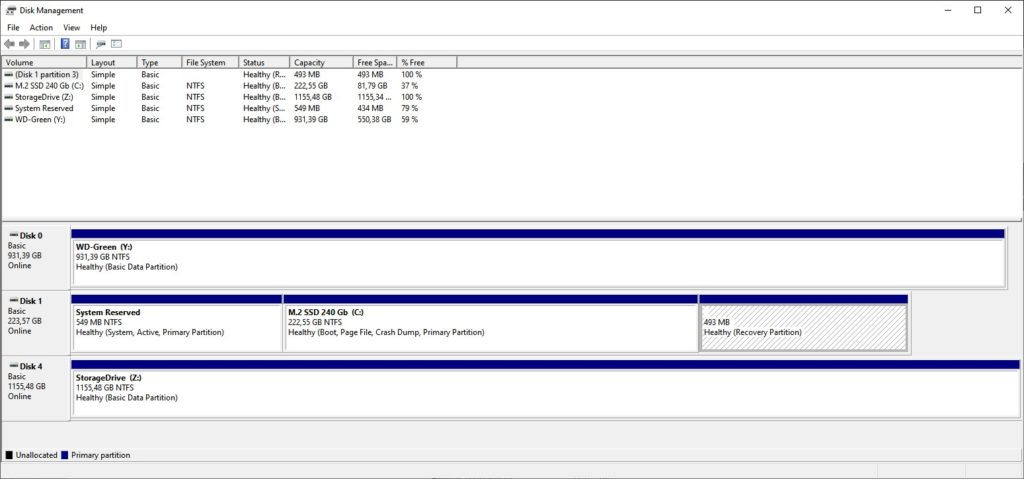
Как выглядит созданный виртуальный диск в оснастке Disk Management
Как работает механизм сегрегации данных в tiered варианте объединения? Новые данные обычно записываются на HDD, а затем, если к ним часто и много обращаются, то перемещаются уже на SSD. Если же системе требуется записать большое количество небольших и случайных изменений данных, то такие изменения записываются в первую очередь на SSD (используется механизм кэширования на SSD), с последующим перенесением на HDD если это необходимо. Все перемещения между слоями (иерархиями) дисков происходят либо автоматически (если такая опция была выбрана при создании пула дисков), либо во время обслуживания виртуального диска (та самая дефрагментация), либо командами через PowerShell.
Можно ли добавлять диски к пулу после его создания? Да, можно. Причем проделать эту процедуру можно уже в оснастке Storage Spaces. В целом Windows позволяет добавлять в пул более, чем достаточное количество дисков. Общее пространство можно разделять между различными виртуальными дисками. Виртуальные диски можно делать даже больше, чем есть физического места для хранения. В случае исчерпания свободного места на диске он переводится в режим Read Only до тех пор, пока не будет добавлен новый диск в пул дисков.
При использовании хранения данных одновременно на нескольких дисках увеличивается вероятность потери данных по причине выхода из строя накопителя или сразу нескольких. Опытные системные администраторы сразу же упомя́нут, что ценные данные вообще-то нужно периодически резервировать на сменных носителях (те самые магнитные ленты) и хранить их в отдельном помещении или лучше здании (городе, стране и т.п.). Но можно попробовать поднять надежность хранения данных и в случае использования tiered disk при использовании Storage spaces. Во-первых, совершенно никто не мешает организовать аппаратное зеркалирование на уровне UEFI (BIOS) и включать в пул дисков уже зеркалированные диски. Во-вторых, согласно документации от Microsoft, создав пул из hdd и sdd (и соответственно tiered drive) у нас есть возможность создавать на его основе и так называемые вложенные (nested) виды объединения, которые уже могут зеркалироваться или иметь избыточность. Однако, данное действие имеет смысл только при наличии действительно достаточного количества физических дисков для организации зеркалирования или избыточности.
Кстати, даже при использовании обычного tiered объединения некоторые диски можно исключать из пула для их замены (однако, для их замены они должны быть настроены в системе как извлекаемые (hot swap)).
Итак, для добавления своего tiered пула в Windows 10 можно воспользоваться либо командами в PowerShell (в документации Microsoft достаточно подробно описана пошаговая процедура создания tiered drive через PowerShell), либо воспользоваться скриптами win10-storage-spaces от freemansoft специально предназначенными для автоматизации создания Tiered Storage.
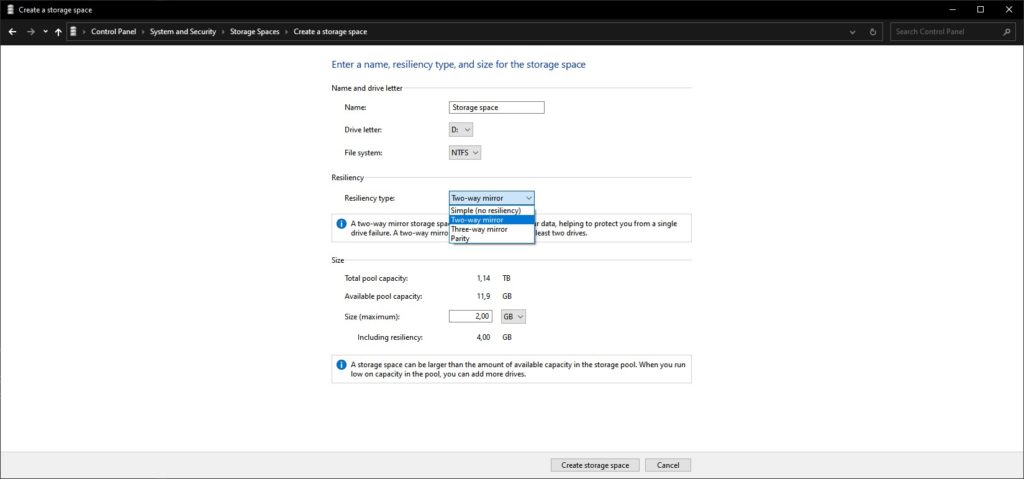
Возможность создания Nested Drives на свободном месте Storage Spaces
Процедура использования скриптов достаточно проста, требуется подредактировать скрипт создания пула, изменить наименование пула и виртуального диска, подумать над буквой, которая будет назначена виртуальному диску. Затем освободить диски от разделов и запустить скрипт создания. Он автоматически добавит в пул все свободные от разделов диски, исправит неверные или отсутствующие идентификаторы у HDD-дисков, создаст один виртуальный диск по всему размеру всех подключенных дисков.
Если вдруг, по каким-то причинам, касающимся безопасности, скрипт не будет исполняться, то необходимо изменить настройки безопасности для скриптов и запустить процедуру заново.
После создания пула им уже можно управлять через оснастку Storage Spaces. Например, в пул можно добавить еще дисков. Однако, если изначально у нас создавался tiered пул на двух дисках (т.е. сформирован Simple пул), то его нельзя будет переконвертировать в Two-way Mirror пул, хотя можно будет организовать Nested Two-way Mirror диск при создании нового виртуального диска.
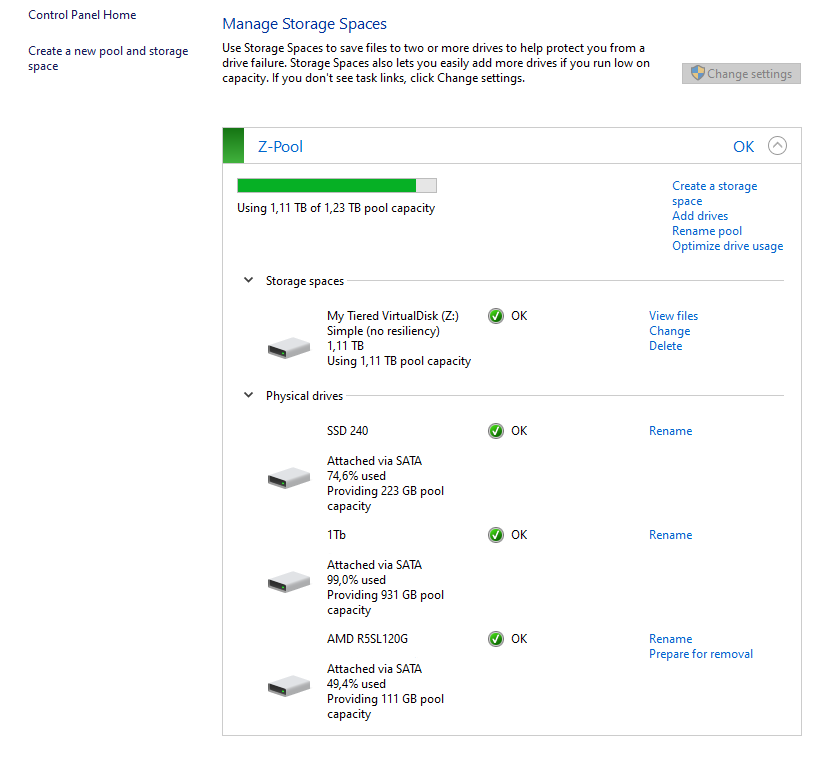
Storage Spaces после добавления в пул еше одного SSD и проведения оптимизации
При добавлении нового физического диска в пул система сразу предлагает провести оптимизацию. Я добавил к системе еще один 120 Гб SSD-диск (к уже добавленному 240 Гб SSD и 1 Тб HDD) и после оптимизации я получил загрузку в 74% 240 Гб SSD и 50% от 120 Гб SSD. Таким образом, на обоих SSD осталось примерно поровну не назначенного в пул места. И именно это место я могу использовать в качестве пространства для создания нового Storage Space (по сути, это и есть виртуальный диск).
После добавления нового диска и оптимизации можно провести изменение размера виртуального диска. Осуществить эту операцию через оснастку Storage Spaces нельзя, система возвращает ошибку. Дело в том, что легкого способа увеличить размер виртуального диска не существует. Проблема кроется в том, как организуются пулы в Storage Spaces. Все дело в так называемом Number of Columns, а именно в количестве физических дисков, на которых физически располагается виртуальный диск. И для успешного изменения размера виртуального диска необходимо добавить в пул количество диско равное Number of Columns. Звучит немного странно, но таковы ограничения. Однако, в моем случае, Tiered disk создался с пустым количеством Columns, т.к. у меня, при создании пула был только один SSD и один HDD. В общем и целом, мне не удалось увеличить размер общего пула после добавления дополнительного SSD-диска в пул. Тем не менее, оба диска работают в пуле совместно. О проблемах с увеличением или уменьшением места в Storage Pool сообщают пользователи и серверных операционных систем. Не помогает в том числе и ручное создание пулов с несколькими разнокалиберными дисками. Так что экспериментировать со Storage Spaces еще есть куда.
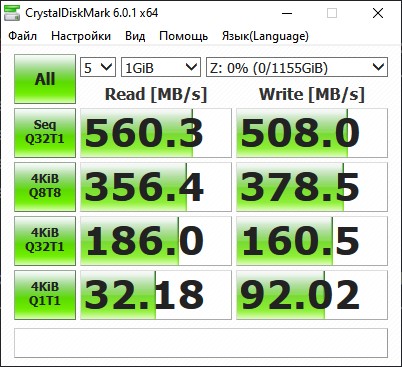
Данные по работе виртуального диска (отображается производительность моего SSD-диска)
Для измерения полученного результата можно воспользоваться как обычными средствами типа Crystal Disk Mark или же использоваться специализированное средство от Microsoft DiskSpd. Disk Mark, как и положено будет давать результаты с SSD-диска, так как он первым воспринимает удар синтетической цифровой стихии, а DiskSpd дает более интересный результат, но его нужно еще правильно интерпретировать.
Полезные ссылки:
- Intel Optane
- RAID
- AMD StoreMI
- enmotus FuzeDrive
- Delphi
- ROMEX PrimoCache
- Статья на Habr об использовании Storage Spaces
- Storage Spaces на Microsoft Docs
- Описание утилиты DiskSpd и ее репозиторий на GitHub
- Использование DiskSpd
- Скрипты win10-storage-spaces
- Страница на GitHub Joe Freeman-а, автора скриптов по автоматизации
- Оригинальная запись блога Nils Schimmelmann-а, который провел изыскания по включение tiered pool в Win10
- Настройка политики запуска скриптов в PowerShell
- Использование tiering на LVM под Linux при помощи LVM-Cache
- Storage Spaces: Understanding Storage Pool Expansion
- Cannot Extend Simple Virtual Disk in Windows Server 2012 R2
- Storage Spaces: Understanding Storage Pool Expansion
- ReadyBoost
Storage spaces is the mechanism or technology that enables you to virtualize storage by grouping disks into storage pools, and then creating virtual disks called storage spaces from the available capacity in the storage pools.
Let’s say that we have a server that’s got a couple of 1 TB hard drives, and let’s say for the sake of redundancy we decide that we’re going to mirror these disks. So we create a RAID 1 mirror on these physical disks, and then we create a volume in Windows on top of that mirror and every time data is written to this volume, it actually gets written to both disks. Now if one of the physical disks fails, we can continue operating, since the other disk will have a copy of the data. However, someone will need to replace the failed disk in the mirror so it can become healthy again. So there’s some manual work and administrative intervention required. The other downside with this setup is that there’s limited flexibility. Once we mirror these two volumes, our total available capacity is going to be fixed at 1 TB, so if we create a volume that uses all that space, we don’t have easy options for extending it later, at least not without a lot of manual work. So Storage Spaces removes some of these limitations when we’re working with local or direct-attached storage; it gives us some flexibility, because we can over-provision our volume sizes and add more physical disks later. And there’s also more flexibility in terms of resiliency and recovering from failed disks. So as an alternative, let’s say that we’ve got a Windows Server 2016 machine, it has a number of local disks. These could be internal disks inside the server, or they could be from direct-attached storage. But instead of implementing a traditional RAID setup, we can instead pool all the physical disks together within the operating system, and from there we can create a storage space, also referred to as a virtual disk, using some or all of the storage in the pool. Physical disks size don’t have to be identical; they can be different sizes and they can even be different types. So we could have a mixture of SATA, SAS, SSD-based disks, or even USB disks. Now when we created a virtual disk using the storage in the pool, we’re creating a flexible storage space. Keep in mind that the virtual disk terminology used here is different than VHDX. These are not VHDX files. So the naming is a little bit confusing, so just remember that when you’re working with Storage Spaces, virtual disks are a different concept.
I have set up six different disks that we’ll be connecting to for the purposes of creating a storage spaces and tiered storage. The four disks on the left side are 278 GB disks. I’ve also 2 additional disks, of 557 GB in size.

One of the very first tasks we’ll do is we’ll take two of these 278 GB disks and connect them together, squoosh their contents together to create a single storage space that we could either host files on or make available on the network.

Let’s get started. Open Server Manager –> File and Storage Services –> Disks
If I take a look at the available disks that are connected up into this server we can see all six of these that are currently attached. You can see that they’re in an unknown state; they haven’t been partitioned or formatted.

In order for us to use storage spaces, to configure it, we’ll begin by creating what is called a storage pool.
- Storage pools. A collection of physical disks that enable you to aggregate disks, expand capacity in a flexible manner, and delegate administration.
- Storage spaces. Virtual disks created from free space in a storage pool. Storage spaces have such attributes as resiliency level, storage tiers, fixed provisioning, and precise administrative control.
So on the left-hand side I’m going to go to Storage Pools, and you can see by default we have this concept of a primordial pool, and that means all available disks that we can use to create storage pools. We can see all disks under physical disks.

Right-Click on empty space (or click on tasks –> New Storage Pool) and select New Storage Pool

New Storage Pool Wizard will pop-up. Click Next.
On Specify a storage pool name and subsystem page, here we need to give it a name so in my case it will be StoragePool1, once done click Next.

On Select physical disks for the storage pool page, here are the disks that we can add to the pool. I will select two 278 GB disks. Now here’s where things start to get really cool. So, when I configure these disks, one of the things I can do is determine how I actually want the disks to be available or to be configured when I’m creating this storage pool. So, by default I have these two disks currently set up here as automatic for their allocation, but I could if I want configure one of them to be, for example, a hot spare instead of an automatic disk (hot spares can be used to automatically replace failed disks in the storage pool that’s being used by a storage space) or I could set it up to be a manual disk instead of an automatic disk. By having two of these set to automatic, that allows me actually to create a little later on a storage space that supports one of the RAID levels, like RAID 1 with mirroring.


Now we’re not going to configure that here because we’ll take care of that when we begin creating the volume that’s on the storage space, but remember, I’ve got a couple of these disks in here because I want to create a mirrored, which will be a highly available storage space, when I get to the next step in the process. Click Next
On Confirmation page, click Create

Once the process is complete, we can take a look back here under Storage Pool and see the storage pool that we’ve created with its 556GB of capacity and nearly 555 GB of free space. With this storage pool, we’ve created the next thing we need to do is actually to create a disk, a virtual disk, out of the storage pool. This virtual disk here is more or less like the actual disks that you’ve been dealing with in the past in previous operating systems when you’ve been connecting to them through the disk management console. Now one important thing to recognize here is that a virtual disk also exists as kind of an additional layer of abstraction between the storage pool, the actual disks we’re working with, and the volumes that we’ll ultimately make available from the storage of Windows files. So, as you’ll see here, we can create multiple virtual disks that exist in a storage pool and then create multiple volumes that exist in each virtual disk. Let’s create new virtual disk by right-clicking on our storage pool and selecting new virtual disk

When we create a new virtual disk, we have to identify which storage pool we want to use. This will be the 556 GB storage pool we created. Click OK

On Before you begin page, click next
On Specify the virtual disk name, give your virtual disk a name. (Remember, virtual disks and Storage Spaces are different than the VHDX files)
Notice the setting here where it says Create storage tiers on this virtual disk. So if I had both magnetic and SSD-based disks in the storage pool, I could make use of storage tiers here. Click Next

Specify enclosure resiliency page, Enclosure Awareness gives you some resiliency if you have storage failures. So notice the note at the bottom telling you that you need to have at least three enclosures and the physical disks in those enclosures must be set for automatic allocation in the storage pool. So in that scenario, you’d have multiple enclosures connected via direct-attached storage, and then you’d have some resiliency there and the means to recover from some kind of hardware failure. Well let’s go ahead and hit Next.

Select the storage layout page, Here we determine what the storage layout will be. Now, that can be no high availability at all, here is the Simple layout, where we essentially stripe the data across those physical disks. This would be equivalent to a RAID 0 configuration. If I have at least two disks or even as many as five disks, I could choose the Mirror configuration. I need two disks to support the loss of a single disk at a time and five disks to protect from two simultaneous disk failures. The Mirror is equivalent to RAID 1. Last in the list is Parity— the Parity is equivalent to a RAID 5, where if I have at least three disks, that would allow me to protect me from a single disk failure, whereas seven disks would protect me from two disk failures. The Parity option here offers some different performance characteristics with different consumption characteristics as well. I will choose Mirror here because I have a couple of disks that I want to stripe this content across, once done click next

Specify the provisioning type page, we need to decide which provisioning type we are going to configure or use.
- Fixed – This provision type means that we’re going to create a virtual disk that cannot exceed the actual storage pool capacity
- Thin – This provision type means that we can create volume and make it much bigger than the storage pool can accommodate and then we can add physical disks later. So with Thin provisioning we can create volume that is much larger than the total size of the storage pool. Over time, if we start to get close to using up the actual total capacity of the storage pool, Windows will give us a warning and we can easily just add more physical disks to the pool, and that’s one of the great things about Storage Spaces.
I’ll choose the thin provisioning and click next

Specify the size of the virtual disk page, for the size I’ll enter 1024 GB and hit Next, and click on Create.

With the virtual disk built notice we’ve got an option at the bottom to create a new volume when the wizard closes, so let’s leave that enabled and click on Close, and that’ll take us into the wizard to create a volume, just like we’ve been using all along. So let’s hit Next on Before you begin page.

The New Volume Wizard goes through a bunch of very similar steps like what we’ve seen already because there are these multiple tiers of storage that we’ll be provisioning out for different reasons. So, we’ll connect up to our server and you can see our disk 7 that we’ve created and that storage spaces disk titled VirtualDisk1. I’ll choose Next,
I will choose the entire size of the volume, so I’ll fill the disk with that volume that we’re creating. Click Next

I will give it a Drive letter here, D is fine, click next

Here we’ll choose the NTFS file system, I’ll go ahead and update the volume lable to Volume1, and we’ll go ahead and create that volume.

On Completion page click close. Click on our storage pool, and down at the bottom on the left-hand side we can see our virtual disk, 1 TB in size. We can also see the physical disks that maps to in the storage pool.

If we ever got to the point where we are getting close to exceeding the actual underlying physical storage limits, we could add more physical disks by right-clicking on storagepool1 and selecting Add Physical Disk

Heading back over to Disks on the left-hand side you can see now a Disk 7, which is our virtual disk; you can see the Bus Type is Storage Spaces and kind of just looking at the bottom windows, we can see the D volume with a 1 TB capacity. Over on the right-hand side, we actually see what it is on the storage pool. We see that there’s 553 GB free. So that’s the process of creating the storage pool and the storage space.

Tiered Storage
Another functionality that’s built into Windows Server is the ability to take our storage spaces and configure them just so that they can support what is called tiered storage. Now up until this point, we have dealt with the creation of a single storage space using 2 disks. These are a pair of HDD disks attached to this machine and they are mirrored together.

SSDs, especially the Enterprise type SSDs that you would want to put into a server can be an order of magnitude more expensive than your traditional hard disks, especially when you’ve got a very large amount of space that you need to host for other kinds of uses, like the storing of Office documents. In these circumstances, you might not want to buy SSDs for storing Office documents, but you still want to make sure that you have good performance for users that are coming in. Tiered storage provides you the ability to accomplish this by taking your hard disks, your traditional hard disks, and connecting them together with your SSD drives to create that single visible storage space. The neat part here is that the Windows storage subsystem can handle making sure that the right documents end up on the SSDs and then documents that are really no longer being used as much can be deprioritized back onto the traditional spinning hard disks to be made available the next time a person needs to make use of them. This use of SSDs as a caching functionality is essentially what we’re attempting to accomplish here with tiered storage.
Now in order for us to be able to use storage tiering, we have to have both SSD and traditional spinning hard drives, which we don’t actually have at this point because all disks that are configured for this storage pool are actually HDD. I will show you really quick just kind of a little hack that you can implement when you’re demoing this at home so that you can create tiered storage without having to go out and buy both SSD and traditional spinning hard drives.
The way in which we actually build tiered storage starts in server manager by creating another storage pool. I have 3 disks left which I will use for Tiered Storage.

I already created new Storage Pool (StoragePool2). As you can see all my disks have Media Type set to Unknown.

So let’s change Media Type to HDD and SSD. To be able to change Unknown to SSD or HDD we need to open powershell and run Set-PhysicalDisk command. You can type in Get-PhysicalDisk first to get a list of all PhysicalDisks. I need to convert Physical Disk 01, 04, 05 and 06, so Physical Disk 04 and 05 will be SSD and Physical Disk 01 and 06 will be HDD.
Set-PhysicalDisk -Friendlyname PhysicalDisk04 -MediaType SSD (This command will reset the mediatype to SSD so that Windows believe that 04 is Solid State Drives. Run this command to convert 05 to SSD and the same command for disk 1 and 6 but change SSD to HDD.

Now let’s go back to Server Manager and then refresh the view. If I’ve done this correctly I should be able to see indeed I’ve reconverted these 4 disks now so that Windows believes they’re the kind of disks that we need in order to do tiered storage.

In order to create that tiered storage, what I need to do is from this storage pool actually create a virtual disk out of the pool. We’ve already seen how this process works when we created Storage Spaces. Right-Click on StoragePool2 and select new Virtual Disk

When we create a new virtual disk, we have to identify which storage pool we want to use. This will be our second storage pool StoragePool2. Click OK

I’ll create a new disk called VirtualDisk2 and in this case I will choose to create the storage tiers on the virtual disk. Click Next

On the Specify enclosure resiliency page, click next
On Select the storage layout page, I’ll choose Mirror. Click Next

I’ll choose fixed disks here because storage tiers do require fixed disk provisioning

Here I have a slightly different option for how I’m going to determine what size is going to be provisioned for both the faster tier, the SSD tier, and then the standard tier, the hard disk, the traditional spinning disks tier. I can choose maximum size for both of these because I’m not really interested in adjusting the size. Click Next and Create

Last step is to create a volume. I’ll skip the process of creating a volume because you’ve already seen how that works back on Storage Spaces part. When we create volume on that storage and provision it out to users, it will allow those users to copy files into that location and not have to worry whether they’re in the cache or whether they’re back on the spinning disk, the Windows subsystem will take care of everything for you.
What we covered
- What is Storage Spaces and How to configure it
- What is Tiered Storage and How to configure it
Thanks for reading!
Cheers,
Nedim
Ever since I rebuilt my homelab during the covid pandemic, I was never happy with the performance I was getting for the hardware that I had. Homelab 2.0 as I dubbed it has changed to something different than I originally designed, moving from VMware vcenter to Hyper-V 2022 being one of the biggest changes! Frustratingly, I have rebuilt this lab about 3 or 4 times now to get things working as well as it should.
The final issue I’m battling is dreadful storage write and read speeds in storage spaces on server 2022.
If you have been using storage spaces in your homelab, you probably had performance issues. Google it and you will see there’s tons of discussion and blogs about this topic online.
Like most things designed for enterprise, things are not always as simple as they seem. When it comes to storage spaces and getting the most out of your hardware, there are some best practices that need to be followed, the problem is they aren’t very well documented by MS and as a result most people have had issues and had to figure it out by themselves. Thankfully, there are other people like me who blog their findings and share knowledge online for others, filling that documentation void.
There’s a severe lack of documentation on a lot of MS storage spaces stuff. for the most part I resorted to going back to basics, doing what we do in vendor support, creating a lab vm and testing things out !
This was accompanied by a LOT of research, I would recommend that you check out the following resources, these guys do a way better job of explaining this than I could:
- https://datacenteroverlords.com/2018/12/17/microsoft-storage-spaces-is-hot-garbage-for-parity-storage/
- https://storagespaceswarstories.com/storage-spaces-and-slow-parity-performance/#more-63
- https://wasteofserver.com/storage-spaces-with-parity-very-slow-writes-solved/
- https://jackharvest.com/index.php/2022/03/10/storage-spaces-parity-on-server-2022-is-finally-good-enough-to-use/
The summary of it is you have to carefully match your interleave, column and allocation unit size:
Allocation Unit size = Parity calculation: ($number_of_columns — 1) * $interleave
Double parity Calculation: ($number_of_columns — 2) * $interleave
Simple Calculation: ($number_of_columns) * $interleave
My original plan was to use SSD caching in my server as I thought that would solve my issues. I bought some SSDs on prime day and set out to configure it. Originally, I thought that storagebus cache would be the best solution, I already run server 2022 and do not have clustering, should be simple right.
In the end I decided against this… the severe lack of documentation and no information about this online make it a dangerous prospect. My original plan was again to lab this feature out and see how it works, but I had so many issues getting this to work in a VM that I decided it was too risky to put data in this configuration without knowing how I would handle drive failures and general DR related scenarios. I am not sure if my failures were due to me trying to do this in a VM or not, but I saw other people online who blogged about it and did have it working in a VM. I was confused to say the least.
New and unproven technology with little info online is a risky data storage solution. Furthermore, when comparing it with the old storage tiers type setup for SSD caching there was no real information about any benefits to using storagebus cache over tiers. Plus, there’s a lot more information out there about storage tiers configuration with PowerShell, so I decided that would be the best option and got to work writing a script in the lab to configure this.
I have provided a script below that you can use to create a tiered storage space and adjust the allocation unit size, columns and interleave sizes to suit your setup.
The beauty of it is that you can create SSD (performance) tier and a HDD (Capacity) tier and set different Resiliency settings, Interleave and Column sizes to suit how many disks you have of each type.
For example in my script below i configure a volume that has 2 HDD’s and 1 SSD, therefore i needed to set different Interleave and Column sizes to match my Allocation unit size of 64K on REFS.
Drop this in a .ps1 file and watch it go:
#start
write-output «
=================================================================
Welcome to the EASYSTOREAGESPACEWITHTIERS script.
By Luke Varley — www.phishandchips.dev
This script will allow you to easily create a Tiered Storage Spaces
Virtual Disk
Read the comments in the script for instructions
#Created with knowledge obtained from
nils.schimmelmann
#Credit: https://nils.schimmelmann.us/post/153541254987/intel-smart-response-technology-vs-windows-10
Joe Freeman
#Credit: https://github.com/freemansoft/win10-storage-spaces
=================================================================
«
#check if elevation is required
if (-Not ([Security.Principal.WindowsPrincipal] [Security.Principal.WindowsIdentity]::GetCurrent()).IsInRole([Security.Principal.WindowsBuiltInRole] ‘Administrator’)) {
if ([int](Get-CimInstance —Class Win32_OperatingSystem | Select-Object —ExpandProperty BuildNumber) -ge 6000) {
write-output «
=================================================================
SCRIPT REQUIRES ELEVATION, PLEASE RUN FROM AN ADMINISTRATIVE
POWERSHELL WINDOW. RUN AS ADMINISTRATOR.
=================================================================
«
Pause
Exit
}
}
Pause
#start
#Pool that will suck in all drives
$StoragePoolName = «VMStoreTiered»
#Tiers in the storage pool
$SSDTierName = «SSDTier-VMStoreTiered»
$HDDTierName = «HDDTier-VMStoreTiered»
#Virtual Disk Name made up of disks in both tiers
$TieredDiskName = «VMStoreTieredVD»
#Set Mirror, Simple, or Parity Resiliency type. Simple = striped. Mirror only works if both can mirror AFIK
#https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2012-R2-and-2012/dn387076(v=ws.11)
$SSDTierResiliency = «Simple»
$HDDTierResiliency = «Simple»
#$ntfs_aus = Parity calculation: ($number_of_columns — 1) * $interleave
# Double parity Calculation: ($number_of_columns — 2) * $interleave
# Simple Calculation: ($number_of_columns) * $interleave
$SSDInterleave = «65536» #in Bytes
$HDDInterleave = «32768» #in Bytes
$AllocationUnitSize = «65536» #in Bytes
#
$NumberOfHDDColumns = «2»
$NumberOfSSDColumns = «1»
#Change to suit — drive later and the label name
$TieredDriveLetter = «H»
$TieredDriveLabel = «VMStoreTiered»
#Override the default sizing here — useful if have two different size SSDs or HDDs — set to smallest of pair
#These must be Equal or smaller than the disk size available in that tier SSD and HDD
#SSD:cache — HDD:data
#set to null so copy/paste to command prompt doesn’t have previous run values
$SSDTierSize = $null
$HDDTierSize = $null
#Drives cannot always be fully allocated — probably broken for drives < 10GB
$UsableSpace = 0.99
#Uncomment and put your HDD type here if it shows up as unspecified with «Get-PhysicalDisk -CanPool $True
# If your HDDs show up as Unspecified instead of HDD
#$UseUnspecifiedDriveIsHDD = «Yes»
#List all disks that can be pooled and output in table format (format-table)
Get-PhysicalDisk —CanPool $True | ft FriendlyName, OperationalStatus, Size, MediaType
#Store all physical disks that can be pooled into a variable, $PhysicalDisks
# This assumes you want all raw / unpartitioned disks to end up in your pool —
# Add a clause like the example with your drive name to stop that drive from being included
# Example » | Where FriendlyName -NE «ATA LITEONIT LCS-256»
if ($UseUnspecifiedDriveIsHDD -ne $null){
$DisksToChange = (Get-PhysicalDisk —CanPool $True | where MediaType -eq Unspecified)
Get-PhysicalDisk —CanPool $True | where MediaType -eq Unspecified | Set-PhysicalDisk —MediaType HDD
# show the type changed
Get-PhysicalDisk —CanPool $True | ft FriendlyName, OperationalStatus, Size, MediaType
}
$PhysicalDisks = (Get-PhysicalDisk —CanPool $True | Where MediaType -NE UnSpecified)
if ($PhysicalDisks -eq $null){
throw «Abort! No physical Disks available»
}
#Create a new Storage Pool using the disks in variable $PhysicalDisks with a name of My Storage Pool
$SubSysName = (Get-StorageSubSystem).FriendlyName
New-StoragePool —PhysicalDisks $PhysicalDisks —StorageSubSystemFriendlyName $SubSysName —FriendlyName $StoragePoolName
#View the disks in the Storage Pool just created
Get-StoragePool —FriendlyName $StoragePoolName | Get-PhysicalDisk | Select FriendlyName, MediaType
#Create two tiers in the Storage Pool created. One for SSD disks and one for HDD disks
$SSDTier = New-StorageTier —StoragePoolFriendlyName $StoragePoolName —FriendlyName $SSDTierName —MediaType SSD —NumberOfColumns $NumberOfSSDColumns —Interleave $SSDInterleave —ResiliencySettingName $SSDTierResiliency
$HDDTier = New-StorageTier —StoragePoolFriendlyName $StoragePoolName —FriendlyName $HDDTierName —MediaType HDD —NumberOfColumns $NumberOfHDDColumns —Interleave $HDDInterleave —ResiliencySettingName $HDDTierResiliency
#Calculate tier sizes within this storage pool
#Can override by setting sizes at top
if ($SSDTierSize -eq $null){
$SSDTierSize = (Get-StorageTierSupportedSize —FriendlyName $SSDTierName —ResiliencySettingName $SSDTierResiliency).TierSizeMax
$SSDTierSize = [int64]($SSDTierSize * $UsableSpace)
}
if ($HDDTierSize -eq $null){
$HDDTierSize = (Get-StorageTierSupportedSize —FriendlyName $HDDTierName —ResiliencySettingName $HDDTierResiliency).TierSizeMax
$HDDTierSize = [int64]($HDDTierSize * $UsableSpace)
}
Write-Output «TierSizes: ( $SSDTierSize , $HDDTierSize )»
# you can end up with different number of columns in SSD — Ex: With Simple 1SSD and 2HDD could end up with SSD-1Col, HDD-2Col
New-VirtualDisk —StoragePoolFriendlyName $StoragePoolName —FriendlyName $TieredDiskName —StorageTiers @($SSDTier, $HDDTier) —StorageTierSizes @($SSDTierSize, $HDDTierSize) —WriteCacheSize 0GB
# initialize the disk, format and mount as a single volume
Write-Output «preparing volume»
Get-VirtualDisk $TieredDiskName | Get-Disk | Initialize-Disk —PartitionStyle GPT
# This will be Partition 2. Storage pool metadata is in Partition 1
Get-VirtualDisk $TieredDiskName | Get-Disk | New-Partition —DriveLetter $TieredDriveLetter —UseMaximumSize
Initialize-Volume —DriveLetter $TieredDriveLetter —FileSystem REFS —AllocationUnitSize $AllocationUnitSize —Confirm:$false —NewFileSystemLabel $TieredDriveLabel
Get-Volume —DriveLetter $TieredDriveLetter
$TieredDriveLetterPath = «$TieredDriveLetter« + «:\»
Write-Output «Setting REFS File integrity on:»
$TieredDriveLetterPath
Set-FileIntegrity $TieredDriveLetterPath —Enable $True
Write-Output «Operation complete»
Storage Spaces в Windows Server 2012 R2
Storage Spaces — технология виртуализации дискового пространства, которая впервые появилась в Microsoft Windows Server 2012. Storage Spaces является дальнейшим развитием механизма управления динамическими дисками в Windows. Основой является широко применяемая в решениях различных вендоров концепция дисковых пулов: отдельные физические диски сервера объединяются в один или несколько пулов, на базе которых создаются тома с различными уровнями производительности и отказоустойчивости. Использование Storage Spaces вместо аппаратного RAID-контроллера имеет ряд преимуществ и недостатков, которые будут подробно рассмотрены ниже.
Термины
- Storage pool (пул хранения) — набор физических дисков. В одном пуле могут находится диски, отличающиеся по объёму, производительности и интерфейсу подключения.
- Virtual disk (виртуальный диск) — термин для определения логический том в Storage Spaces. Для создания виртуального диска используется ёмкость выбранного дискового пула. При этом доступны несколько вариантов отказоустойчивости (их можно комбинировать в пределах одного пула), большинство из которых являются аналогами традиционных RAID-массивов различных уровней.
- Simple (простой) — аналог RAID-0. Поток данных разбивается на страйпы (по умолчанию размером в 256КиБ), которые распределяются по дискам в пуле. Виртуальный диск simple обеспечивает оптимальное использование ёмкости дисков и является самым производительным, но не предполагает никакой отказоустойчивости.
- Mirror (зеркальный): для каждого страйпа в зеркальном виртуальном диске записывается дополнительно одна (двойное зеркало, 2-way mirror) или две (тройное зеркало, 3-way mirror) копии. Аналогом в плане использования ёмкости дисков для двойного зеркала является RAID-10 (или 1E для нечётного числа дисков). Зеркальный ВД защищён от потери одного или двух дисков соответственно.
- Parity (виртуальный диск с контролем чётности): запись страйпов на диски чередуется с записью контрольной суммы. В Windows Server 2012 R2 появились диски с двойной чётностью (dual parity), в которых дополнительно пишется вторая контрольная сумма. Как и аналогичные RAID-5 и RAID-6 ВД с контролем чётности допускают потерю одного или двух дисков соответственно и обеспечивают минимальную потерю дискового пространства (-1 или -2 диска соответственно). Традиционным недостатком любых реализаций томов с контрольными суммами является низкая производительность на запись из-за необходимости модификации всего полного страйпа вместе с контрольными суммами. Отсутствие фиксированного размещения страйпов в Storage Spaces и RAM-кэша на контроллере (используются обычные HBA) усугубляет данную проблему, сравнение производительности ВД single parity и dual parity с RAID-5 и RAID-6 будет ниже.
- В Windows Server 2012 R2 появился функционал enclosure awareness: при размещении страйпов учитывается размещение дисков по различным дисковым полкам (SAS JBOD’ам) для получения отказоустойчивости на уровне дисковых полок. Например, ВД с двойным зеркалированием (2-way mirror), размещенный на трёх дисковых полках, допускает потерю одной дисковой полки целиком.
- Параллельность распределения страйпов в виртуальном диске определяется числом т.н. столбцов (columns). Для получения максимальной производительности число столбцов для виртуальных дисков с уровнем отказоустойчивости simple и parity должно соответствовать количеству физических дисков, но в настройках по умолчанию максимальное число столбцов, например, для simple равно 8. Это связано с особенностями механизма расширения ёмкости пула: для оптимального использования ёмкости число добавляемых дисков должно соответствовать максимальному числу столбцов, которое используется виртуальными дисками, а для зеркальных дисков — числу столбцов * числу копий страйпа (2 для 2-way mirror, 3 для 3-way mirror).
- Storage tiers (ярусное хранение данных). В Windows Server 2012 R2 появилась поддержка 2-ярусного (SSD и HDD) размещения данных на виртуальных дисках Storage Spaces. Приоретизация доступа к быстрому ярусу из SSD возможна путём управления ёмкостью (при создании ВД указываются комбинация объёмов SSD и HDD ярусов) либо на файловом уровне: необходимый файл можно привязать к SSD-ярусу для обеспечения гарантированной производительнности.
- Write-back cache (кэш на запись). Для компенсации низкой производительности на случайную запись небольшая часть SSD в пуле используется для кэширования записи. При этом оставшаяся часть ёмкости SSD может быть использована для ярусного хранения.
Ограничения
Количество дисков и ёмкость:
- До 240 дисков одном пуле (в Windows Server 2012R2, ранее — до 160-ти), но пулов может быть несколько.
- До 80-ти дисков в кластеризованном пуле, до 4-х пулов на кластер.
- До 64-х виртуальных дисков в одном пуле.
- Общая ёмкость пула — до 480ТиБ.
Столбцы и количество дисков в ВД:
| Тип ВД | Минимальное число столбцов | Соотношение столбцы/диски | Минимальное число дисков | Максимальное число столбцов |
| Simple (простой) | 1 | 1:1 | 1 | — |
| Two-way mirror (двойное зеркало) | 1 | 1:2 | 2 | — |
| Three-way mirror (тройное зеркало) | 1 | 1:3 | 5 | — |
| Single parity (одиночная чётность) | 3 | 1:1 | 3 | 8 |
| Dual parity (двойная чётность) | 7 | 1:1 | 7 | 17 |
Прочее
- Виртуальный диск Storage Spaces не может использоваться в качестве загрузочного.
- Для Storage Spaces можно использовать только диски с интерфейсами SAS, SATA и USB. Тома, презентуемые RAID-контроллерами; тома iSCSI, FC и прочие не поддерживаются.
Требования при использовании в кластере
- Нельзя использовать «тонкие» диски, допускается только фиксированное выделение ёмкости (fixed provisioning).
- Минимальное количество дисков для двойного зеркала — 3, для тройного зеркала — 5.
- В кластере можно использовать ВД с Parity, но только начиная с Windows Storage Server 2012 R2
- Используемые диски — только SAS с поддержкой SPC (SCSI persistent reservation). Многие ранние SAS-диски не поддердивают SPC. Аналогичное требование существует и для LSI Syncro CS.
Storage Spaces в кластерах
Одна из самых востребованных возможностей Storage Spaces — использование в failover-кластере Windows. Архитектура решения предельно проста: требуются диски SAS (см. дополнительные требования к дискам и организации томов), SAS JBOD (дисковая полка) с двумя SAS-экспандерами и минимум двумя разъемами для подключения к каждому из экспандеров (для двухузлового кластера). На серверах в качестве контроллеров используются обычные SAS HBA. Мы рекомендуем LSI (любые SAS2 и SAS3 HBA с внешними портами, например LSI 9207-8e), но можно использовать и Adaptec серий 6H и 7H.
Минимальной конфигурация выглядит так: два сервера, в каждом из них двухпортовый SAS HBA с подключением к 2-экспандерному SAS JBOD’у на базе корпуса Supermicro и SAS диски.

Для использования в качестве SAS JBOD’а можно использовать любой корпус Supermicro с двумя экспандерами (E26 или E2C в наименовании для SAS2 и SAS3 соответственно). Каждый экспандер в корпусах Supermicro имеет минимум два разъема x4 SAS (SFF-8087 или SFF-8643), которые можно использовать в качестве входов. При наличии третьего разъема его можно использовать для каскадирования (подключения дополнительных дисковых полок) или для построения топологии с тремя узлами в кластере.
Существуют варианты в одном корпусе, т.н. Cluster-in-a-box (CiB): готовые комплекты SSG-6037B-CIB032 и SSG-2027B-CIB020H на базе Supermicro Storage Bridge Bay с предустановленным Windows Storage Server 2012 R2 Standard, которые отлично подходят для построения отказоустойчивых файловых и/или iSCSI серверов:

Производительность
Решение на базе Storage Spaces может масштабироваться до более чем миллиона IOPS при использовании SSD и зеркальных томов. Но производительность на запись в Parity и Dual Parity по-прежнему оставляет желать лучшего, и такие конфигурации без write-back кэша на SSD подходят лишь для узкого круга задач с преимущественной нагрузкой на чтение.
Всестороннее исследование производительности Storage Spaces в разных конфигурациях было проведено компанией Fujitsu. В нашей тестовой лаборатории мы повторили некоторые из этих тестов, дополнив измерение IOPS и пропускной способности значениями средней и максимальной задержек.
Условия тестирования
- Два процессора E5640
- 8GB RAM
- Системная плата Supermicro X8DTL-iF
- Контроллер Adaptec 6805 (тесты с аппаратным RAID), кэш на чтение включен, кэш на запись включен
- Контроллер LSI 9211-8i (тесты со Storage Spaces, прошивка P19 IT
- Диски HGST HUA723030ALA640 (3ТБ 7200об/мин SATA3): 12шт для тестов RAID-10 vs Storage Spaces 2-way mirror и 13шт для тестов RAID-6 vs Storage Spaces dual parity
- 2шт SSD Intel 710 100ГБ для тестов с tiering’ом и write-back кэшом
- Microsoft Windows Server 2012 R2 Standard
- Для генерации нагрузки применялся FIO версии 2.1.12
Для тестирования использовался скрипт, реализующий серию 60-секундных раундов нагрузки с различными шаблонами и варьированием глубины очереди. Для определения окна установившегося состояния используется та же методика, что и в нашем пакете для тестирования SSD, разработанного в соответсвии со спецификацией SNIA Solid State Storage Performance Test Specification Enterprise v1.1. Для всех замеров использовался тестовый файл объёмом 100ГиБ, кроме тестов с ярусным хранением, где использовался файл объёмом 32ГиБ.
Для наглядности использовались шаблоны аналогичные использованным в тестах от Fujitsu:
| Шаблон | Доступ | Чтение | Запись | Размер блока, КиБ |
| File copy | случайный | 50% | 50% | 64 |
| File server | случайный | 67% | 33% | 64 |
| Database | случайный | 67% | 33% | 8 |
| Streaming | последовательный | 100% | 0% | 64 |
| Restore | последовательный | 0% | 100% | 64 |
Результаты
RAID-10 vs Storage Spaces 2-way mirror
Сравнивались: RAID-10 из 12-ти дисков на контроллере Adaptec 6805, 2-way mirror из 12-ти дисков (6 столбцов), 2-way mirror из 12-ти дисков с 2ГиБ write-back кэшом на двух SSD Intel 710 и ярусным хранением — SSD-tier’ом из тех же объёмом в 40ГБ (40ГБ SSD + 200ГБ HDD).
Шаблоны Database (IOPS), File copy, File Server (пропускная способность). Для шаблона Database используется логарифмическая шкала. По графикам видно, что 2-way mirror заметно уступает в производительности традиционному аппаратному RAID-10: в два с лишним раза на шаблонах Database и File copy, примерно в 1,5 раза на шаблоне File Server. Выравнивание результатов с ростом глубины очереди больше 16-ти нельзя рассматривать с точки зрения практического использования из-за неприемлемого роста задержек (графики ниже). Серьезный рост производительности обеспечивает использование SSD в качесте кэша на запись и быстрого яруса. Всего пара даже устаревших на сегодняшний день Intel 710 поднимает производительность на случайном доступе малыми блоками на порядок. Есть смысл использовать такое сочетание не только для OLTP, но и для нагруженных файловых серверов.

Шаблоны Database, File copy, File Server: средняя задержка. Никаких сюрпризов: Storage Spaces проигрывает, но естественно вырывается вперёд при добавлении SSD.

Шаблоны Database, File copy, File Server: максимальная задержка. При более высокой средней задержке Storage Spaces демонстрирует более стабильные значения — максимумы при небольшой глубине очереди меньше на шаблонах Database и File copy.

Шаблоны Streaming, Restore: пропускная способность. Зеркальный Storage Spaces не уступает аппаратному RAID при последовательном чтении, но существенно уступает при последовательной записи (шаблон Restore). Рост при запредельных значениях глубины очереди (>64) имеет значение только в синтетических тестах из-за большого значения задержки. Использование SSD в данном случае оказывается бесполезным из-за последовательного доступа и соотношения числа HDD и SSD. Обычные HDD, тем более в количестве 12-ти штук, отлично справляются с последовательной нагрузкой и оказываются существенно быстрее пары SSD.

Шаблоны Streaming, Restore: средняя задержка.

Шаблоны Streaming, Restore: максимальная задержка. Появляется хоть какая-то польза от SSD в виде стабилизации значения задержки..

RAID-6 vs Storage Spaces dual parity
Сравнивались: RAID-6 из 13-ти дисков на контроллере Adaptec 6805 и Dual Parity из 13-ти дисков (13 столбцов). К сожалению, у нас не оказалось минимально требуемого для использования в таком пуле количества SSD аналогичных использованным в первой серии тестов — для Dual Parity их нужно минимум три. Но соответствующее сравнение производительности с SSD tier’ом и кэшированием записи есть в вышеупомянутом исследовании Fujitsu.
Шаблоны Database (IOPS), File copy, File Server (пропускная способность). Storage Spaces с Dual Parity существенно отстаёт от аппаратного RAID во всех сценариях со случайным доступом. Это не удивительно с учётом того, что в распоряжении Adaptec 6805 есть 512МБ RAM-кэша, что позволяет существенно оптимизировать неудобный для RAID-6 доступ на случайную запись. Среди тестов, проведённых Fujitsu, есть вариант «RAID-6 8xHDD против Dual Parity 8xHDD + 1ГБ WB кэша на 3xSSD» — на всех трёх шаблонах производительность при добавлении WB-кэша на SSD не уступает аппаратному RAID, причём без использования ярусного хранения.

Шаблоны Database, File copy, File Server: средняя задержка.

Шаблоны Database, File copy, File Server: максимальная задержка. Ситуация аналогична предыдущей серии тестов с зеркальным Storage Spaces. При более высокой средней задержке Storage Spaces демонстрирует более стабильные значения — максимумы при небольшой глубине очереди меньше на шаблонах Database и File copy.

Шаблоны Streaming, Restore: пропускная способность. Dual Parity хорошо справляется с чтением, но с последовательной записью наблюдается давно известная катастрофическая ситуация с отставанием более чем на порядок. Использование даже большого по объёму write-back кэша (можно выделить диски целиком, присвоив диску Usage=Journal) на нескольких SSD может на какое-то время компенсировать относительно кратковременные нагрузки на запись, но при непрерывной записи (например, при использовании в системе видеонаблюдения) кэш рано или поздно будет заполнен.

Шаблоны Streaming, Restore: средняя задержка. Для шаблона Restore используется логарифмическая шкала.

Шаблоны Streaming, Restore: максимальная задержка (логарифмическая шкала).

Преимущества и недостатки Storage Spaces
Преимущества
- Снижение затрат на оборудование.
Для простых проектов с одиночным сервером: SAS HBA или чипсетный контроллер вместо аппаратного RAID-контроллера; возможность использовать недорогие диски SATA, формально не совместимые с аппаратными RAID (например, WD Red) вместо дисков nearline класса.
Для проектов с одиночной неотказоустойчивой СХД и большими требованиями к плотности размщениния дисков можно использовать такие платформы (72 диска в 4U, до 432ТБ сырой ёмкости при использовании 6ТБ дисков):

Для кластерных решений: простые дисковые полки (SAS JBOD’ы) вместо дорогостоящих СХД.
- Высокая производительность. Решение на базе Storage Spaces и SSD легко масштабируется по пропускной способности и IOPS путём добавления дисковых полок и HBA вплоть до нескольких миллионов IOPS и десятков ГБ/с. Сравнительно невысокая производительность обычных HDD может быть компенсирована применением ярусного хранения с размещением «горячих» данных на SSD и/или использованием SSD для кэширования операций записи.
Использование tiering’а (ярусного хранения) в сочетании с кэширование записи на SSD в Storage Spaces в большинстве случаев работает эффективнее, обходится дешевле и имеет большие пределы масштабирования в сравнении с реализацией SSD кэша на аппаратных RAID-контроллерах (например, LSI CacheCade или Adaptec MaxCache).
- Гибкое использование дискового пространства. В Storage Spaces можно комбинировать на одной дисковой группе (в одном пуле) тома с любым уровнем отказоустойчивости, при добавлении в пул SSD — с любым соотношением ёмкости между HDD- и SSD-ярусами и/или ёмкостью write-back кэша.
Для всех видов томов, за исключением использования в кластере, томов с ярусным хранением и томов Dual Parity поддерживается Thin Provisiong (тонкое выделение ресурсов) — это позволяет выделять ёмкость только по мере реального использования.

Недостатки
- Низкая производительность на запись при использовании обычных HDD, особенно в Parity и Dual Parity
Определенный тип нагрузки на запись (случайный доступ небольшими блоками, сосредоточенный в определённой области) может быть легко компенсирован добавлением SSD в качестве быстрого яруса и кэша на запись. Но продолжительную линейную нагрузку на запись компенсировать не получится, так что рекомендовать использование Storage Spaces, например, для видеонаоблюдения нельзя.
Для бюджетных кластерных решений под Windows (с похожей архитектурой на базе SAS JBOD) с высокой нагрузкой на запись мы советуем использовать вместо Storage Spaces специальные RAID-контроллеры LSI Syncro CS.
- Ограниченное масштабирование кластера. Для использования Storage Spaces в кластере необходим совместный доступ к дискам через дисковую полку с двумя SAS-экспандерами (SAS JBOD). SAS JBOD не является отдельной самостоятельной СХД, поэтому кластер с использованием Storage Spaces может состоять максимум из 4-х узлов (необходим специальный SAS JBOD с 4-мя входами на каждый экспандер), а в типовых конфигурациях с SAS JBOD Supermicro — максимом из 3-х узлов (или 2-х при необходимости подключать дополнительные JBOD’ы каскадом).
Советы по оптимальному использованию Storage Spaces
- При использовании в кластере используйте только SAS HDD и SSD, избегайте использования SATA дисков с дополнительными интерпозерами.
- При создании виртульных дисков учитывайте число т.н. столбцов. Данный параметр может очень сильно влиять на производительность. Нестандартное число столбцов можно задать только при использовании PowerShell. Использование большего числа столбцов повышает производительность, но накладывает ограничение на добавление дисков в пул.
Пример (виртуальный диск Dual Parity, 13 столбцов, 1000ГиБ, Fixed Provisioning):
New-VirtualDisk -StoragePoolFriendlyName Pool1 -FriendlyName VD02 -ResiliencySettingName Parity -NumberOfColumns 13 -PhysicalDiskRedundancy 2 -Size 1000GB -ProvisioningType Fixed
- Избегайте использования виртуальных дисков Parity и Dual Parity при наличии большой нагрузки на запись и/или случайного доступа малыми блоками.
- Одним из самых востребованных на сегодня решений является небольшой 2-узловой кластер для Hyper-V. Из-за конкурентного обращения нескольких ВМ достаточно высокий процент нагрузки на дисковую подсистему будет состоять из случайного доступа. При расчёте дисковой подсистемы планируйте использование зеркальных виртуальных дисков (2-way mirror — стандартное двойное зеркалирование, для особых сценариев можно использовать тройное), производительность Parity и Dual Parity будет достаточно только для архивных данных. Планируйте использование минимум двух SSD для tiering’а и кэширования записи.
- Избегайте добавления дисков с разной производительностью (например, HDD 7200 и 10000 об/мин) в общий пул либо создавайте виртуальные диски только из HDD с одинаковой производительностью, выбирая их вручную в GUI или через параметр
-PhysicalDisksToUseпри создании через PowerShell. Диски SSD должны быть либо вынесены в отдельный пул, либо использоваться совместно с HDD только в качестве быстрого яруса и/или write-back кэша.
Ссылки
- Часто задаваемые вопросы по Storage Spaces
- Обзор Storage Spaces
- Storage Cmdlets in Windows PowerShell
- Пример PowerShell скрипта для создания пула, ярусов и ВД
- Deploy Clustered Storage Spaces
- Корпуса Supermicro с SAS-экспандерами
- White Paper: Fujitsu Server PRIMERGY Windows Server 2012 R2 Storage Spaces Performance
- Storage Spaces — Designing for Performance