
Windows Speech Recognition (WSR) is speech recognition developed by Microsoft for Windows Vista that enables voice commands to control the desktop user interface, dictate text in electronic documents and email, navigate websites, perform keyboard shortcuts, and operate the mouse cursor. It supports custom macros to perform additional or supplementary tasks.
Windows Speech Recognition
|
The tutorial for Windows Speech Recognition in Windows Vista depicting the selection of text in WordPad for deletion. |
|
| Developer(s) | Microsoft |
|---|---|
| Initial release | November 30, 2006; 18 years ago |
| Operating system | Windows Vista and later |
| Type | Speech recognition |
WSR is a locally processed speech recognition platform; it does not rely on cloud computing for accuracy, dictation, or recognition, but adapts based on contexts, grammars, speech samples, training sessions, and vocabularies. It provides a personal dictionary that allows users to include or exclude words or expressions from dictation and to record pronunciations to increase recognition accuracy. Custom language models are also supported.
With Windows Vista, WSR was developed to be part of Windows, as speech recognition was previously exclusive to applications such as Windows Media Player. It is present in Windows 7, Windows 8, Windows 8.1, Windows RT, Windows 10, and Windows 11.
Microsoft was involved in speech recognition and speech synthesis research for many years before WSR. In 1993, Microsoft hired Xuedong Huang from Carnegie Mellon University to lead its speech development efforts; the company’s research led to the development of the Speech API (SAPI) introduced in 1994.[1] Speech recognition had also been used in previous Microsoft products. Office XP and Office 2003 provided speech recognition capabilities among Internet Explorer and Microsoft Office applications;[2] it also enabled limited speech functionality in Windows 98, Windows Me, Windows NT 4.0, and Windows 2000.[3] Windows XP Tablet PC Edition 2002 included speech recognition capabilities with the Tablet PC Input Panel,[4][5] and Microsoft Plus! for Windows XP enabled voice commands for Windows Media Player.[6] However, these all required installation of speech recognition as a separate component; before Windows Vista, Windows did not include integrated or extensive speech recognition.[5] Office 2007 and later versions rely on WSR for speech recognition services.[7]
At WinHEC 2002 Microsoft announced that Windows Vista (codenamed «Longhorn») would include advances in speech recognition and in features such as microphone array support[8] as part of an effort to «provide a consistent quality audio infrastructure for natural (continuous) speech recognition and (discrete) command and control.»[9] Bill Gates stated during PDC 2003 that Microsoft would «build speech capabilities into the system — a big advance for that in ‘Longhorn,’ in both recognition and synthesis, real-time»;[10][11] and pre-release builds during the development of Windows Vista included a speech engine with training features.[12] A PDC 2003 developer presentation stated Windows Vista would also include a user interface for microphone feedback and control, and user configuration and training features.[13] Microsoft clarified the extent to which speech recognition would be integrated when it stated in a pre-release software development kit that «the common speech scenarios, like speech-enabling menus and buttons, will be enabled system-wide.»[14]
During WinHEC 2004 Microsoft included WSR as part of a strategy to improve productivity on mobile PCs.[15][16] Microsoft later emphasized accessibility, new mobility scenarios, support for additional languages, and improvements to the speech user experience at WinHEC 2005. Unlike the speech support included in Windows XP, which was integrated with the Tablet PC Input Panel and required switching between separate Commanding and Dictation modes, Windows Vista would introduce a dedicated interface for speech input on the desktop and would unify the separate speech modes;[17] users previously could not speak a command after dictating or vice versa without first switching between these two modes.[18] Windows Vista Beta 1 included integrated speech recognition.[19] To incentivize company employees to analyze WSR for software glitches and to provide feedback, Microsoft offered an opportunity for its testers to win a Premium model of the Xbox 360.[20]
During a demonstration by Microsoft on July 27, 2006—before Windows Vista’s release to manufacturing (RTM)—a notable incident involving WSR occurred that resulted in an unintended output of «Dear aunt, let’s set so double the killer delete select all» when several attempts to dictate led to consecutive output errors;[21][22] the incident was a subject of significant derision among analysts and journalists in the audience,[23][24] despite another demonstration for application management and navigation being successful.[21] Microsoft revealed these issues were due to an audio gain glitch that caused the recognizer to distort commands and dictations; the glitch was fixed before Windows Vista’s release.[25]
Reports from early 2007 indicated that WSR is vulnerable to attackers using speech recognition for malicious operations by playing certain audio commands through a target’s speakers;[26][27] it was the first vulnerability discovered after Windows Vista’s general availability.[28] Microsoft stated that although such an attack is theoretically possible, a number of mitigating factors and prerequisites would limit its effectiveness or prevent it altogether: a target would need the recognizer to be active and configured to properly interpret such commands; microphones and speakers would both need to be enabled and at sufficient volume levels; and an attack would require the computer to perform visible operations and produce audible feedback without users noticing. User Account Control would also prohibit the occurrence of privileged operations.[29]
WSR was updated to use Microsoft UI Automation and its engine now uses the WASAPI audio stack, substantially enhancing its performance and enabling support for echo cancellation, respectively. The document harvester, which can analyze and collect text in email and documents to contextualize user terms has improved performance, and now runs periodically in the background instead of only after recognizer startup. Sleep mode has also seen performance improvements and, to address security issues, the recognizer is turned off by default after users speak «stop listening» instead of being suspended. Windows 7 also introduces an option to submit speech training data to Microsoft to improve future recognizer versions.[30]
A new dictation scratchpad interface functions as a temporary document into which users can dictate or type text for insertion into applications that are not compatible with the Text Services Framework.[30] Windows Vista previously provided an «enable dictation everywhere option» for such applications.[31]
Windows 8.x and Windows RT
edit
WSR can be used to control the Metro user interface in Windows 8, Windows 8.1, and Windows RT with commands to open the Charms bar («Press Windows C»); to dictate or display commands in Metro-style apps («Press Windows Z»); to perform tasks in apps (e.g., «Change to Celsius» in MSN Weather); and to display all installed apps listed by the Start screen («Apps»).[32][33]
WSR is featured in the Settings application starting with the Windows 10 April 2018 Update (Version 1803); the change first appeared in Insider Preview Build 17083.[34] The April 2018 Update also introduces a new ⊞ Win+Ctrl+S keyboard shortcut to activate WSR.[35]
In Windows 11 version 22H2, a second Microsoft app, Voice Access, was added in addition to WSR.[36][37] In December 2023 Microsoft announced that WSR is deprecated in favor of Voice Access and may be removed in a future build or release of Windows.[38]
Overview and features
edit
WSR allows a user to control applications and the Windows desktop user interface through voice commands.[39] Users can dictate text within documents, email, and forms; control the operating system user interface; perform keyboard shortcuts; and move the mouse cursor.[40] The majority of integrated applications in Windows Vista can be controlled;[39] third-party applications must support the Text Services Framework for dictation.[1] English (U.S.), English (U.K.), French, German, Japanese, Mandarin Chinese, and Spanish are supported languages.[41]
When started for the first time, WSR presents a microphone setup wizard and an optional interactive step-by-step tutorial that users can commence to learn basic commands while adapting the recognizer to their specific voice characteristics;[39] the tutorial is estimated to require approximately 10 minutes to complete.[42] The accuracy of the recognizer increases through regular use, which adapts it to contexts, grammars, patterns, and vocabularies.[41][43] Custom language models for the specific contexts, phonetics, and terminologies of users in particular occupational fields such as legal or medical are also supported.[44] With Windows Search,[45] the recognizer also can optionally harvest text in documents, email, as well as handwritten tablet PC input to contextualize and disambiguate terms to improve accuracy; no information is sent to Microsoft.[43]
WSR is a locally processed speech recognition platform; it does not rely on cloud computing for accuracy, dictation, or recognition.[46] Speech profiles that store information about users are retained locally.[43] Backups and transfers of profiles can be performed via Windows Easy Transfer.[47]
The WSR interface consists of a status area that displays instructions, information about commands (e.g., if a command is not heard by the recognizer), and the status of the recognizer; a voice meter displays visual feedback about volume levels. The status area represents the current state of WSR in a total of three modes, listed below with their respective meanings:
- Listening: The recognizer is active and waiting for user input
- Sleeping: The recognizer will not listen for or respond to commands other than «Start listening»
- Off: The recognizer will not listen or respond to any commands; this mode can be enabled by speaking «Stop listening»
Colors of the recognizer listening mode button denote its various modes of operation: blue when listening; blue-gray when sleeping; gray when turned off; and yellow when the user switches context (e.g., from the desktop to the taskbar) or when a voice command is misinterpreted. The status area can also display custom user information as part of Windows Speech Recognition Macros.[48][49]
An alternates panel disambiguation interface lists items interpreted as being relevant to a user’s spoken word(s); if the word or phrase that a user desired to insert into an application is listed among results, a user can speak the corresponding number of the word or phrase in the results and confirm this choice by speaking «OK» to insert it within the application.[50] The alternates panel also appear when launching applications or speaking commands that refer to more than one item (e.g., speaking «Start Internet Explorer» may list both the web browser and a separate version with add-ons disabled). An ExactMatchOverPartialMatch entry in the Windows Registry can limit commands to items with exact names if there is more than one instance included in results.[51]
Listed below are common WSR commands. Words in italics indicate a word that can be substituted for the desired item (e.g., «direction» in «scroll direction» can be substituted with the word «down«).[40] A «start typing» command enables WSR to interpret all dictation commands as keyboard shortcuts.[50]
- Dictation commands: «New line»; «New paragraph»; «Tab»; «Literal word«; «Numeral number«; «Go to word«; «Go after word«; «No space»; «Go to start of sentence»; «Go to end of sentence»; «Go to start of paragraph»; «Go to end of paragraph»; «Go to start of document» «Go to end of document»; «Go to field name» (e.g., go to address, cc, or subject). Special characters such as a comma are dictated by speaking the name of the special character.[40]
- Navigation commands:
- Keyboard shortcuts: «Press keyboard key«; «Press ⇧ Shift plus a«; «Press capital b.»
- Keys that can be pressed without first giving the press command include: ← Backspace, Delete, End, ↵ Enter, Home, Page Down, Page Up, and Tab ↹.[40]
- Mouse commands: «Click»; «Click that«; «Double-click»; «Double-click that«; «Mark»; «Mark that«; «Right-click»; «Right-click that«; «MouseGrid».[40]
- Window management commands: «Close (alternatively maximize, minimize, or restore) window»; «Close that«; «Close name of open application«; «Switch applications»; «Switch to name of open application«; «Scroll direction«; «Scroll direction in number of pages«; «Show desktop»; «Show Numbers.»[40]
- Speech recognition commands: «Start listening»; «Stop listening»; «Show speech options»; «Open speech dictionary»; «Move speech recognition»; «Minimize speech recognition»; «Restore speech recognition».[40] In the English language, applicable commands can be shown by speaking «What can I say?»[41] Users can also query the recognizer about tasks in Windows by speaking «How do I task name» (e.g., «How do I install a printer?») which opens related help documentation.[52]
MouseGrid enables users to control the mouse cursor by overlaying numbers across nine regions on the screen; these regions gradually narrow as a user speaks the number(s) of the region on which to focus until the desired interface element is reached. Users can then issue commands including «Click number of region,» which moves the mouse cursor to the desired region and then clicks it; and «Mark number of region«, which allows an item (such as a computer icon) in a region to be selected, which can then be clicked with the previous click command. Users also can interact with multiple regions at once.[40]
Applications and interface elements that do not present identifiable commands can still be controlled by asking the system to overlay numbers on top of them through a Show Numbers command. Once active, speaking the overlaid number selects that item so a user can open it or perform other operations.[40] Show Numbers was designed so that users could interact with items that are not readily identifiable.[53]
WSR enables dictation of text in applications and Windows. If a dictation mistake occurs it can be corrected by speaking «Correct word» or «Correct that» and the alternates panel will appear and provide suggestions for correction; these suggestions can be selected by speaking the number corresponding to the number of the suggestion and by speaking «OK.» If the desired item is not listed among suggestions, a user can speak it so that it might appear. Alternatively, users can speak «Spell it» or «I’ll spell it myself» to speak the desired word on letter-by-letter basis; users can use their personal alphabet or the NATO phonetic alphabet (e.g., «N as in November») when spelling.[44]
Multiple words in a sentence can be corrected simultaneously (for example, if a user speaks «dictating» but the recognizer interprets this word as «the thing,» a user can state «correct the thing» to correct both words at once). In the English language over 100,000 words are recognized by default.[44]
A personal dictionary allows users to include or exclude certain words or expressions from dictation.[44] When a user adds a word beginning with a capital letter to the dictionary, a user can specify whether it should always be capitalized or if capitalization depends on the context in which the word is spoken. Users can also record pronunciations for words added to the dictionary to increase recognition accuracy; words written via a stylus on a tablet PC for the Windows handwriting recognition feature are also stored. Information stored within a dictionary is included as part of a user’s speech profile.[43] Users can open the speech dictionary by speaking the «show speech dictionary» command.
WSR supports custom macros through a supplementary application by Microsoft that enables additional natural language commands.[54][55] As an example of this functionality, an email macro released by Microsoft enables a natural language command where a user can speak «send email to contact about subject,» which opens Microsoft Outlook to compose a new message with the designated contact and subject automatically inserted.[56] Microsoft has also released sample macros for the speech dictionary,[57] for Windows Media Player,[58] for Microsoft PowerPoint,[59] for speech synthesis,[60] to switch between multiple microphones,[61] to customize various aspects of audio device configuration such as volume levels,[62] and for general natural language queries such as «What is the weather forecast?»[63] «What time is it?»[60] and «What’s the date?»[60] Responses to these user inquiries are spoken back to the user in the active Microsoft text-to-speech voice installed on the machine.
| Application or item | Sample macro phrases (italics indicate substitutable words) | ||||||
|---|---|---|---|---|---|---|---|
| Microsoft Outlook | Send email | Send email to | Send email to Makoto | Send email to Makoto Yamagishi | Send email to Makoto Yamagishi about | Send email to Makoto Yamagishi about This week’s meeting | Refresh Outlook email contacts |
| Microsoft PowerPoint | Next slide | Previous slide | Next | Previous | Go forward 5 slides | Go back 3 slides | Go to slide 8 |
| Windows Media Player | Next track | Previous song | Play Beethoven | Play something by Mozart | Play the CD that has In the Hall of the Mountain King | Play something written in 1930 | Pause music |
| Microphones in Windows | Microphone | Switch microphone | Microphone Array microphone | Switch to Line | Switch to Microphone Array | Switch to Line microphone | Switch to Microphone Array microphone |
| Volume levels in Windows | Mute the speakers | Unmute the speakers | Turn off the audio | Increase the volume | Increase the volume by 2 times | Decrease the volume by 50 | Set the volume to 66 |
| WSR Speech Dictionary | Export the speech dictionary | Add a pronunciation | Add that [selected text] to the speech dictionary | Block that [selected text] from the speech dictionary | Remove that [selected text] | [Selected text] sounds like… | What does that [selected text] sound like? |
| Speech Synthesis | Read that [selected text] | Read the next 3 paragraphs | Read the previous sentence | Please stop reading | What time is it? | What’s today’s date? | Tell me the weather forecast for Redmond |
Users and developers can create their own macros based on text transcription and substitution; application execution (with support for command-line arguments); keyboard shortcuts; emulation of existing voice commands; or a combination of these items. XML, JScript and VBScript are supported.[50] Macros can be limited to specific applications[64] and rules for macros can be defined programmatically.[56]
For a macro to load, it must be stored in a Speech Macros folder within the active user’s Documents directory. All macros are digitally signed by default if a user certificate is available to ensure that stored commands are not altered or loaded by third-parties; if a certificate is not available, an administrator can create one.[65] Configurable security levels can prohibit unsigned macros from being loaded; to prompt users to sign macros after creation; and to load unsigned macros.[64]
As of 2017 WSR uses Microsoft Speech Recognizer 8.0, the version introduced in Windows Vista. For dictation it was found to be 93.6% accurate without training by Mark Hachman, a Senior Editor of PC World—a rate that is not as accurate as competing software. According to Microsoft, the rate of accuracy when trained is 99%. Hachman opined that Microsoft does not publicly discuss the feature because of the 2006 incident during the development of Windows Vista, with the result being that few users knew that documents could be dictated within Windows before the introduction of Cortana.[42]
- Braina
- List of speech recognition software
- Microsoft Cordless Phone System
- Microsoft Narrator
- Microsoft Voice Command
- Technical features new to Windows Vista
- ^ a b Brown, Robert. «Exploring New Speech Recognition And Synthesis APIs In Windows Vista». MSDN Magazine. Microsoft. Archived from the original on March 7, 2008. Retrieved June 26, 2015.
- ^ «How To Use Speech Recognition in Windows XP». Windows Support. Microsoft. Archived from the original on March 14, 2015. Retrieved May 15, 2020.
- ^ «Description of the speech recognition and handwriting recognition methods in Word 2002». Windows Support. Microsoft. Archived from the original on July 3, 2015. Retrieved March 26, 2018.
- ^ Thurrott, Paul (June 25, 2002). «Windows XP Tablet PC Edition Review». Windows IT Pro. Penton. Archived from the original on July 19, 2011. Retrieved May 15, 2020.
- ^ a b Dresevic, Bodin (2005). «Natural Input On Mobile PC Systems». Microsoft. Archived from the original (PPT) on December 14, 2005. Retrieved May 15, 2020.
- ^ Thurrott, Paul (October 6, 2010). «Plus! for Windows XP Review». Windows IT Pro. Penton. Archived from the original on July 5, 2011. Retrieved May 15, 2020.
- ^ «What happened to speech recognition?». Office Support. Microsoft. Archived from the original on November 10, 2016. Retrieved May 15, 2020.
- ^ Stam, Nick (April 16, 2002). «WinHEC: The Pregame Show». PC Magazine. Ziff Davis Media. Archived from the original on July 3, 2015. Retrieved May 15, 2020.
- ^ Flandern Van, Mike (2002). «Audio Considerations for Voice-Enabled Applications». Windows Hardware Engineering Conference. Microsoft. Archived from the original (EXE) on May 6, 2002. Retrieved March 30, 2018.
- ^ «Bill Gates’ Web Site — Speech Transcript, Microsoft Professional Developers Conference 2003». Microsoft. October 27, 2003. Archived from the original on February 3, 2004. Retrieved May 15, 2020.
- ^ Thurrott, Paul; Furman, Keith (October 26, 2003). «Live from PDC 2003: Day 1, Monday». Windows IT Pro. Penton. Archived from the original on September 11, 2013. Retrieved May 15, 2020.
- ^ Spanbauer, Scott (December 4, 2003). «Your Next OS: Windows 2006?». TechHive. IDG. Retrieved June 25, 2015.
- ^ Gjerstad, Kevin; Chambers, Rob (2003). «Keyboard, Speech, and Pen Input in Your Controls». Professional Developers Conference. Microsoft. Archived from the original (PPT) on December 19, 2012. Retrieved March 30, 2018.
- ^ «Interacting with the Computer using Speech Input and Speech Output». MSDN. Microsoft. 2003. Archived from the original on January 4, 2004. Retrieved June 28, 2015.
- ^ Suokko, Matti (2004). «Windows For Mobile PCs And Tablet PCs — CY05 And Beyond». Microsoft. Archived from the original (PPT) on December 14, 2005. Retrieved May 15, 2020.
- ^ Fish, Darrin (2004). «Windows For Mobile PCs and Tablet PCs — CY04». Microsoft. Archived from the original (PPT) on December 14, 2005. Retrieved May 15, 2020.
- ^ Dresevic, Bodin (2005). «Natural Input on Mobile PC Systems». Microsoft. Archived from the original (PPT) on December 14, 2005. Retrieved May 15, 2020.
- ^ Chambers, Rob (August 1, 2005). «Commanding and Dictation — One mode or two in Windows Vista?». MSDN. Microsoft. Retrieved June 30, 2015.
- ^ Thurrott, Paul (October 6, 2010). «Windows Vista Beta 1 Review (Part 3)». Windows IT Pro. Penton. Archived from the original on August 23, 2014. Retrieved May 15, 2020.
- ^ Levy, Brian (2006). «Microsoft Speech Recognition poster». Archived from the original on October 11, 2006. Retrieved May 15, 2020.
- ^ a b Auchard, Eric (July 28, 2006). «Updated – When good demos go (very, very) bad». Thomson Reuters. Archived from the original on May 21, 2011. Retrieved March 29, 2018.
- ^ «Software glitch foils Microsoft demo». NBC News. August 2, 2006. Archived from the original on March 28, 2018. Retrieved May 15, 2020.
- ^ Montalbano, Elizabeth (July 31, 2006). «Vista voice-recognition feature needs work». InfoWorld. IDG. Archived from the original on August 5, 2006. Retrieved June 26, 2015.
- ^ Montalbano, Elizabeth (July 31, 2006). «Vista’s Voice Recognition Stammers». TechHive. IDG. Archived from the original on July 3, 2015. Retrieved May 15, 2020.
- ^ Chambers, Rob (July 29, 2006). «FAM: Vista SR Demo failure — And now you know the rest of the story …» MSDN. Microsoft. Archived from the original on May 22, 2011. Retrieved May 15, 2020.
- ^ «Vista has speech recognition hole». BBC News. BBC. February 1, 2007. Archived from the original on February 3, 2007. Retrieved May 15, 2020.
- ^ Miller, Paul (February 1, 2007). «Remote ‘exploit’ of Vista Speech reveals fatal flaw». Engadget. AOL. Retrieved June 28, 2015.
- ^ Roberts, Paul (February 1, 2007). «Honeymoon’s Over: First Windows Vista Flaw». PCWorld. IDG. Archived from the original on February 4, 2007. Retrieved June 28, 2015.
- ^ «Issue regarding Windows Vista Speech Recognition». TechNet. Microsoft. January 31, 2007. Archived from the original on May 20, 2016. Retrieved March 31, 2018.
- ^ a b Brown, Eric (January 29, 2009). «What’s new in Windows Speech Recognition?». MSDN. Microsoft. Archived from the original on January 28, 2011. Retrieved May 15, 2020.
- ^ Brown, Eric (October 24, 2007). «Where does dictation work in Windows Speech Recognition?». MSDN. Microsoft. Retrieved March 28, 2018.
- ^ «How to use Speech Recognition». Windows Support. Microsoft. Archived from the original on October 25, 2012. Retrieved December 24, 2018.
- ^ «How to use Speech Recognition in Windows». Windows Support. Microsoft. August 31, 2016. Retrieved December 24, 2018.
- ^ Sarkar, Dona (January 24, 2018). «Announcing Windows 10 Insider Preview Build 17083 for PC». Windows Blogs. Microsoft. Archived from the original on January 24, 2018. Retrieved May 15, 2020.
- ^ «Windows keyboard shortcuts for accessibility». Windows Support. Microsoft. Archived from the original on October 12, 2018. Retrieved January 8, 2019.
- ^ «Set up voice access — Microsoft Support». support.microsoft.com. Retrieved 2022-12-10.
- ^ Hachman, Mark. «New Windows 11 build tests Voice Access, Spotlight backgrounds». PCWorld. Retrieved 2022-12-10.
- ^ Microsoft. «Deprecated features in the Windows client — What’s new in Windows». Retrieved December 7, 2023.
- ^ a b c Phillips, Todd (2007). «Windows Vista Speech Recognition Step-by-Step Guide». MSDN. Microsoft. Retrieved June 30, 2015.
- ^ a b c d e f g h i «Windows Speech Recognition commands». Windows Support. Microsoft. Retrieved May 15, 2020.
- ^ a b c «Windows Speech Recognition». Microsoft Accessibility. Microsoft. Archived from the original on February 4, 2007. Retrieved May 15, 2020.
- ^ a b Hachman, Mark (May 10, 2017). «The Windows weakness no one mentions: Speech recognition». PC World. IDG. Retrieved March 28, 2018.
- ^ a b c d «Windows Vista Privacy Statement». Microsoft. 2006. Archived from the original (RTF) on August 30, 2008. Retrieved May 15, 2020.
- ^ a b c d Chambers, Rob (September 20, 2005). «Customized speech vocabularies in Windows Vista». MSDN. Microsoft. Retrieved March 29, 2018.
- ^ Thurrott, Paul (October 6, 2010). «Jim Allchin Talks Windows Vista». Windows IT Pro. Penton. Archived from the original on March 28, 2018. Retrieved May 15, 2020.
- ^ «Microsoft Privacy Statement». Microsoft. Retrieved May 12, 2020.
- ^ Chambers, Rob (February 15, 2007). «Transferring Windows Speech Recognition profiles from one machine to another». MSDN. Microsoft. Retrieved June 28, 2015.
- ^ Shintaku, Kurt (April 29, 2008). «BETA: ‘Windows Speech Recognition Macros’ Technology Preview». Retrieved March 17, 2016.
- ^ Pash, Adam (May 20, 2008). «Control Your PC with Your Voice». Lifehacker. Gawker Media. Retrieved March 17, 2016.
- ^ a b c Chambers, Rob (November 19, 2007). «Speech Macros, Typing Mode and Spelling Mode in Windows Speech Recognition». MSDN. Microsoft. Retrieved August 25, 2015.
- ^ Chambers, Rob (May 7, 2007). «Windows Speech Recognition — ExactMatchOverPartialMatch». MSDN. Microsoft. Retrieved August 24, 2015.
- ^ Chambers, Rob (March 12, 2007). «Windows Speech Recognition: General commands». MSDN. Microsoft. Retrieved May 1, 2017.
- ^ US 7742923, Bickel, Ryan; Murillo, Oscar & Mowatt, David et al., «Graphic user interface schemes for supporting speech recognition input systems», assigned to Microsoft Corporation
- ^ «Windows Speech Recognition Macros». Download Center. Microsoft. Retrieved June 29, 2015.
- ^ Protalinski, Emil (April 30, 2008). «WSR Macros extend Windows Vista’s speech recognition feature». ArsTechnica. Condé Nast. Retrieved June 29, 2015.
- ^ a b Chambers, Rob (June 9, 2008). «Macro of the Day: Send Email to [OutlookContact]». MSDN. Microsoft. Retrieved June 26, 2015.
- ^ Chambers, Rob (August 2, 2008). «Speech Macro of the Day: Speech Dictionary». MSDN. Microsoft. Retrieved September 3, 2015.
- ^ Chambers, Rob (July 1, 2008). «Macro of the Day: Windows Media Player». MSDN. Microsoft. Retrieved June 26, 2015.
- ^ Chambers, Rob (June 3, 2008). «Macro of the day: Next Slide». MSDN. Microsoft. Retrieved September 3, 2015.
- ^ a b c Chambers, Rob (May 28, 2008). «Macro of the Day: Read that». MSDN. Microsoft. Retrieved June 26, 2015.
- ^ Chambers, Rob (November 7, 2008). «Macro of the Day: Microphone Control». MSDN. Microsoft. Retrieved June 30, 2015.
- ^ Chambers, Rob (August 18, 2008). «Macro of the Day: Mute the speakers!». MSDN. Microsoft. Retrieved September 3, 2015.
- ^ Chambers, Rob (June 2, 2008). «Macro of the Day: Tell me the weather forecast for Redmond». MSDN. Microsoft. Retrieved June 26, 2015.
- ^ a b Chambers, Rob (June 30, 2008). «Making a Speech macro Application Specific». MSDN. Microsoft. Retrieved September 3, 2015.
- ^ «Windows Speech Recognition Macros Release Notes». Microsoft. 2009. Archived from the original (DOCX) on September 30, 2011. Retrieved May 15, 2020.
- Windows Vista Speech Recognition demonstration at Microsoft Financial Analyst Meeting
Last Updated :
22 Mar, 2024
Windows 11 and Windows 10, allow users to control their computer entirely with voice commands, allowing them to navigate, launch applications, dictate text, and perform other tasks. Originally designed for people with disabilities who cannot use a mouse or keyboard.
In this article, We’ll show you How to set up speech recognition on Windows.
What is Speech Recognition?
Speech recognition, also known as speech-to-text, automatic speech recognition (ASR), or computer speech recognition, refers to a machine’s or program’s ability to recognize spoken words and convert them into text.
Table of Content
- How To Setup Windows Speech Recognition
- How to train Speech Recognition to Improve Accuracy?
- How To Change Speech Recognition Settings?
- How To Use Speech Recognition In Windows?
How To Setup Windows Speech Recognition
To Set up Speech Recognition on Windows, You’ve to follow the given Steps:
Step 1: Press Windows Key + R then on the run dialog type «Control Panel«
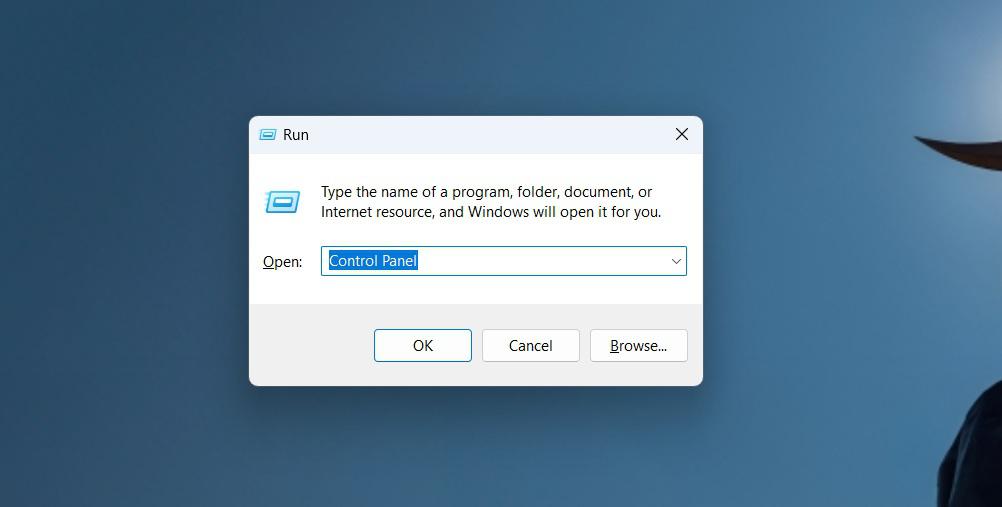
Step 2: Click on “Ease of Access”.
Step 3: Under the “Speech Recognition” section, click on “Start Speech Recognition”.
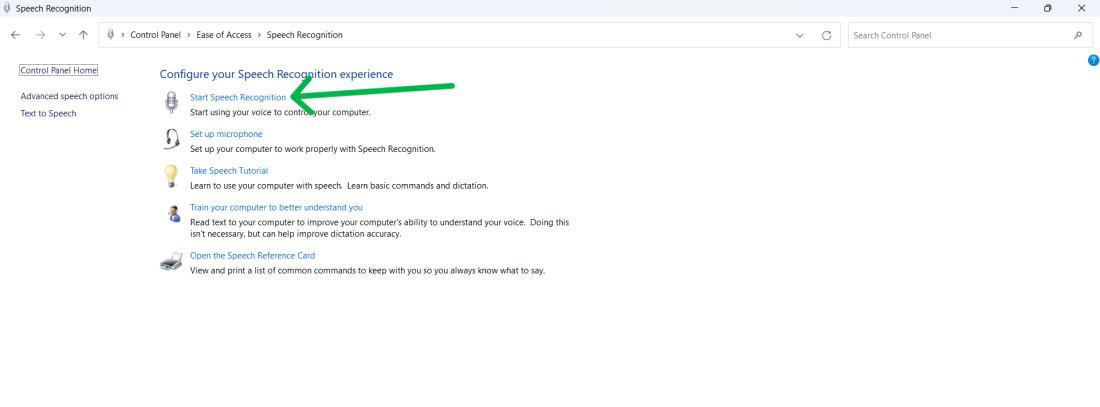
Step 4: Click on the «Next» button
Step 5: In this step, you will be asked to select the type of microphone you want to use on your system.
- Desktop microphones are not ideal.
- Microsoft recommends headset or array microphones.
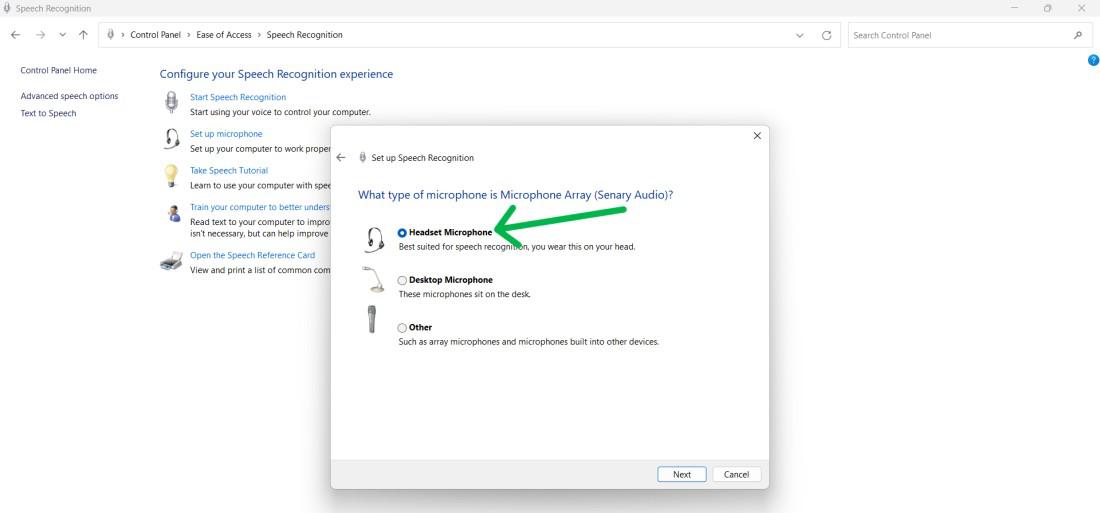
Step 6: To proceed with the setup, click Next after selecting the microphone type.
Step 7: Click on the Next Button again
Step 8: To adjust the microphone volume, speak out the sentence «Peter dictates to his computer, preferring it over typing, and particularly pen and paper.» The Next button will activate after reading the sentences out loud, allowing you to proceed.
Step 9: Click Next.
Step 10: Click Next again.
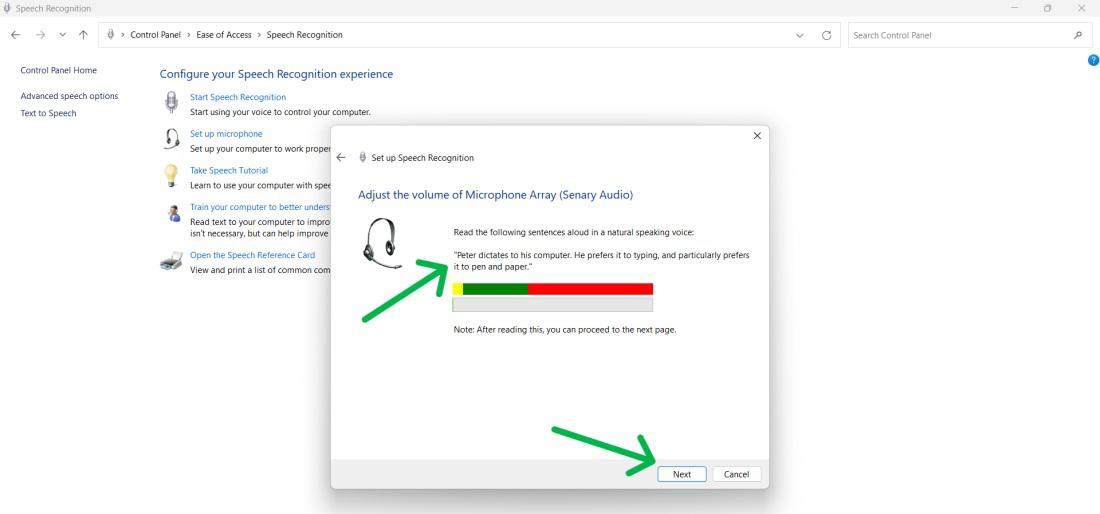
Step 11: Click Next.
Step 12: Click Next again.
Step 13: Speech Recognition enhances document and email accuracy by analyzing user words. Privacy concerns can be addressed by enabling or disabling document review.
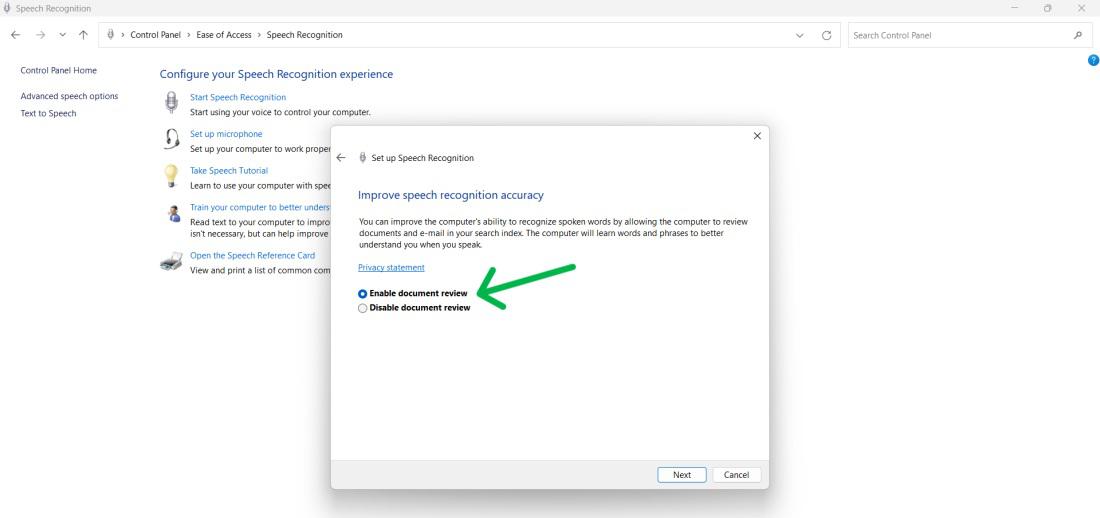
Step 14: Click Next
Step 15: Voice recognition can be enabled using one of two activation modes.
- You can select either manual or voice activation mode.
Step 16: Click Next.
Step 17: Click the View Reference Sheet button
Step 18: Click Next.
Step 19: To run speech recognition at the start-up, then check the “Run Speech Recognition at start-up” box as shown below.
Step 20: Click Next
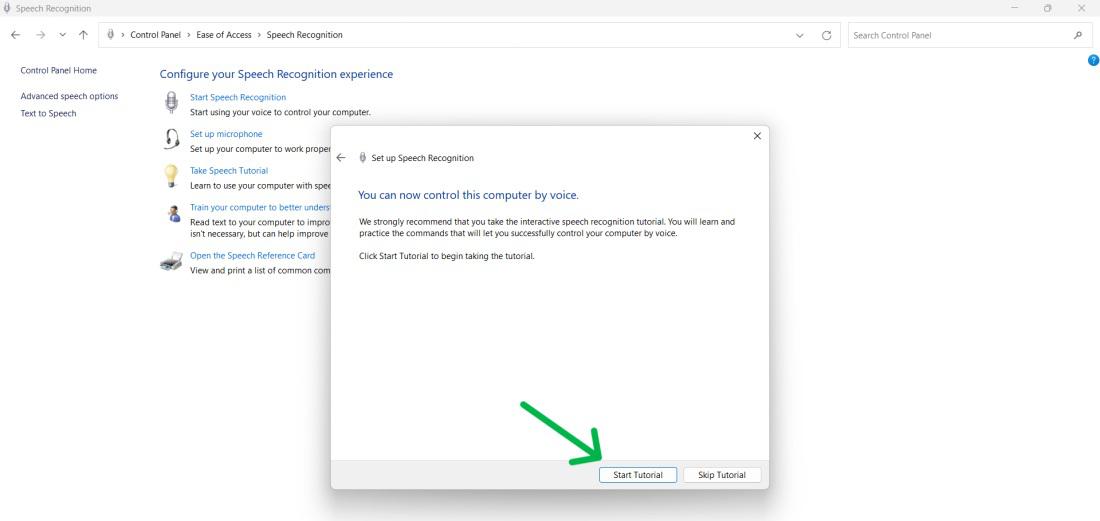
Step 21:
- Start tutorial for feature demonstration.
- Click on Skip tutorial for setup completion.
By following above steps, you will be able able to Set up speech recognition on your laptop/Computer with ease.
How to train Speech Recognition to Improve Accuracy?
To Train and Set up Speech Recognition following steps need to be implemented.
Step 1: Press Windows Key + R then on the run dialog type «Control Panel«
Step 2: Click on “Ease of Access”.
Step 3: Click on the «Train your computer to better understand you» option under the «Speech Recognition» section.
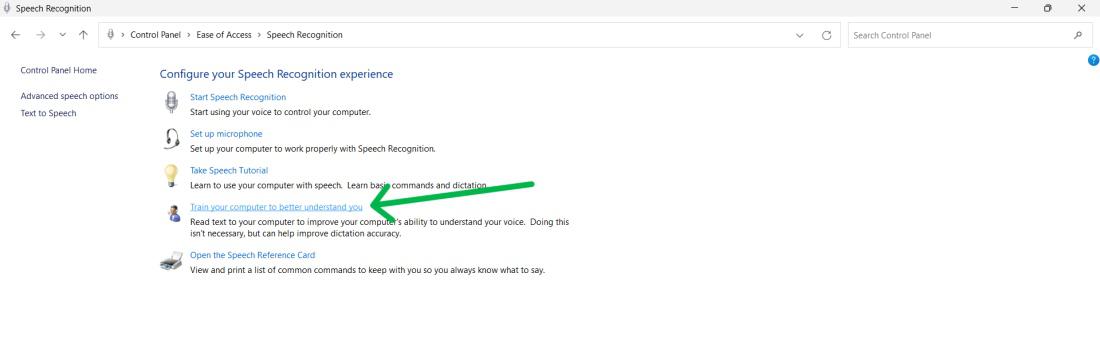
Step 4: Click Next
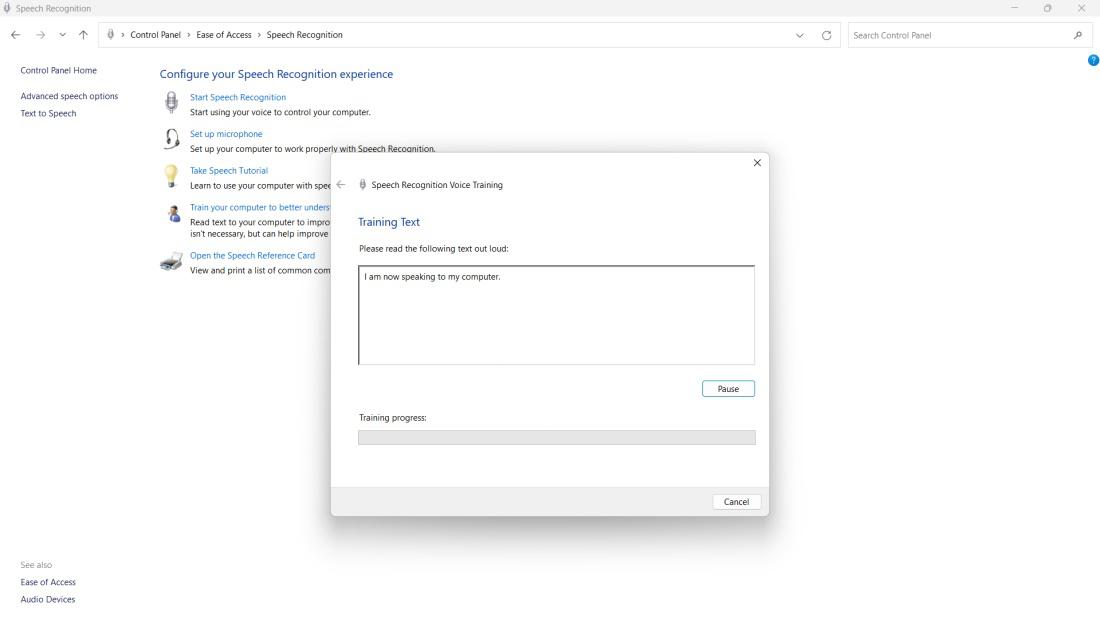
After training, Speech Recognition deepens its understanding of your voice
How To Change Speech Recognition Settings?
Step 1: Open the Control Panel by searching and selecting it.
Step 2: Click «Ease of Access.«
Step 3: Click on Speech Recognition.
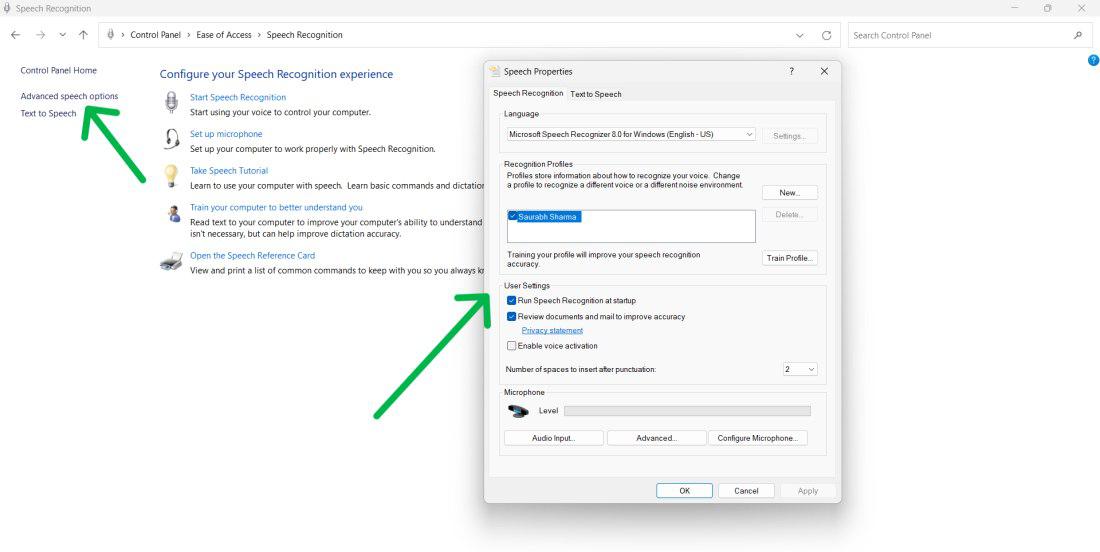
Step 4: Click the Advanced speech from the left side pane
Step 5: In «Speech Properties,» you can customize things like
- Language
- Recognition profiles
- User settings
- Microphone
How To Use Speech Recognition In Windows?
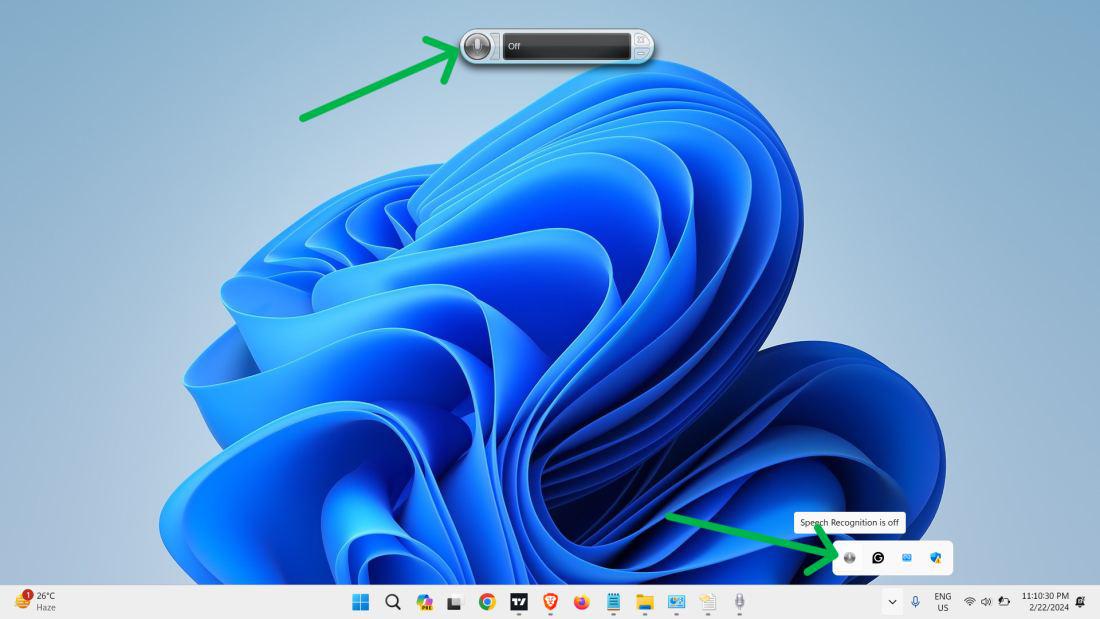
Using Speech Recognition in Windows is simple once you’ve set it up:
Step 1: Click on the system tray on the taskbar
Step 2: Click on the microphone icon to open the Speech Recognition settings menu.
Quick Solution!
Here is a quick solution for our active and speedy learners. Follow these steps to set up speech recognition on Windows 11/10:
- Open Control Panel.
- Click «Ease of Access.«
- Start Speech Recognition.
- Follow prompts to select microphone type, adjust volume, and configure privacy settings.
- Choose activation mode.
- Click on the View reference sheet.
- Opt to run at startup.
- Start tutorial or skip for setup completion.
Conclusion
In conclusion, Use your voice to control your computer with the powerful tool of speech recognition. Dictate text, launch apps, navigate menus, and perform tasks easily. Set up speech recognition, train it, and customize it on Windows 11 to meet your needs and preferences. And this is how You can set up Speech Recognition on Windows PC.
If you wish to use Inquisit’s speech recognition capabilities on Windows XP, you’ll
need the Microsoft Speech Engine 5.1 (or a compatible alternative), which you can download below.
If you are running Windows Vista or later
you do not need to download these components
because they are included by Windows.
Microsoft ships the engine in 3 different languages packs; English,
Japanese, and Chinese. Importantly, each package installs the exact same language neutral speech engine, so
you can use any of the packages to process speech in any Windows-supported language. The language of the package refers
only to the user interface of the control panels and wizards that allow you to configure the engine. If you
install the Chinese version, for example, you can still use the engine to process German speech. However,
the labels and instructions on the Microphone Wizard and other speech wizards would be written in Chinese.
Download Microsoft Speech 5.1 (English)
Download Microsoft Speech 5.1 (Japanese)
Download Microsoft Speech 5.1 (Chinese)
- Windows Speech Recognition
- Windows Speech Recognition on
non-English Windows Installs - Microsoft Speech Recognition
- Recording device
- Voice recognition mode
- Confidence Levels
- Testing voice recognition
- Windows Speech Recognition on
non-English Windows Installs
There are two voice recognition systems which Crew Chief can use.
- The default option is referred to as the «Windows speech recognition
engine» and uses the speech recognition system built in to
Windows. This requires a better quality voice input signal
than the default system but can be trained to recognise a
user’s individual voice. It does not require the installation
of any additional components. - The other option is referred to as the «Microsoft speech recognition
engine» which is optimised for noisy environments and poor
quality sound input. It requires no training and works with a
wide range of microphone types and accents, but it requires a
separate runtime installation and a language pack.
Which is best depends on the quality of your microphone, your
voice, the amount of background noise, and countless other
factors. It’s worth trying both and seeing which gives the best
results.
Windows Speech
Recognition
If you want to use the default Windows
speech recognition engine simply ensure that the ‘Prefer Windows
speech recogniser’ option is checked on the Properties screen. You
will get better results if you work through the speech recognition
training process in Windows.
Windows Speech
Recognition on non-English Windows Installs
If your Windows install isn’t English, you may need to add the English language speech recognition files to your Windows install.
In Settings -> «Time and Language» click Language and add a language package — English (US) works well. Exit the Settings app and restart it, go back to Time and Language settings, then Speech. The language you just added should appear in the Speech Language drop down box, showing that it’s available as a speech recognition language.
That should be sufficient — start Crew Chief and see if it works. You might need to select English (US) as your speech language in the Time and Language settings screen.
There’s also a checkbox in the Speech settings for «Recognise non-native accents for this language». This may improve accuracy for some users.
Note that you don’t have to change your display language to English
Microsoft Speech
Recognition
If you want to use the Microsoft
voice recognition system, you’ll need to install the Microsoft Speech
Recognition runtime
SpeechPlatformRuntime.msi.
From this page click ‘Download’ and select the right version — for most users
this will be x64_SpeechPlatformRuntime\SpeechPlatformRuntime.msi.
Alternative downloads containing this installer (and installers for the UK and US language packs) are
here (64bit) and
here (32bit)
Once you’ve installed this, you’ll also need to install an English language pack. The official download
location for these is here
Again, from this page click ‘Download’ and select the right
version — for most users this will be MSSpeech_SR_en-US_TELE.msi
(US users) or MSSpeech_SR_en-GB_TELE.msi (UK users).
If this isn’t available, these language packs are
also in the alternative download package linked above.
Note that Crew Chief will fall back to using the Microsoft speech
recognition engine if it can’t find a working installation of the
Windows speech recognition
engine.
Recording device
Crew Chief will use the «Default» recording device for voice
recognition — this can be selected in the «Recording devices»
section of the Window Sounds control panel.
(There is also the further choice of using nAudio for input but
that is not recommended, though it does allow you can choose the
recording device.)
Voice
recognition mode
Voice recognition can be configured to be always-on (it listens
continuously and responds when it recognises a command) or in
response to a button press. To assign a button to a activate voice
recognition see Getting
Started: Control Buttons. By default you have to hold this
button down while you talk — this can be changed by selecting a
different ‘Voice recognition mode’.
Confidence
Levels
The voice recognition system reports a «Confidence Level», indicating
how confident is is that it understood what you said.
Crew Chief uses that to be sure that speech is intended as a
and that Crew Chief interprets the command correctly. Crew Chief uses
confidence thresholds to decide whether to reject a voice command which
is recognised with too low a confidence value. The Microsoft and
Windows speech recognition engines report different confidence values and
Crew Chief also uses different threshold values for different situations
(recognising the trigger word «Chief», recognising commands,
recognising names) so there are 6 levels that can be adjusted if
needed. Crew Chief shows the confidence level in the
console window along with the relevant threshold property name and
value when it recognises speech — e.g. Microsoft
recogniser heard keyword «Chief», waiting for command,
confidence 0.986.
By default, Crew Chief will modify the Confidence Level thresholds
automatically, while running tuning them to better match the range of values reported
by the speech recogniser (starting from the initial values set in the Properties screen).
A screen dump of the levels:

Testing voice
recognition
Having set it all up press the Start Application button in
Crew Chief, then press your voice recognition button and ask «Can
you hear me?». If Crew Chief can understand you it’ll respond with
«Yes, I can hear you».
Make sure you test this while the game is running as some games
claim exclusive control, so if no app is running that is claiming
control it will always work.
If it doesn’t work: right click on the speaker on the taskbar,
select Open Sound Settings then Sound Control Panel. In the
Playback tab, select your playback device, then in the Properties
/ Advanced tab uncheck «Allow applications to take
exclusive control of this device» Do the same for your microphone.
Also in the Communications Tab set «When Windows detects
communication activity:» Do Nothing
A screen dump of that:

If it’s still not working read the words of wisdom in the FAQ.
Windows Speech
Recognition on non-English Windows Installs
If your Windows install isn’t English, you may need to add the
English language speech recognition files to your Windows install.
In Settings -> «Time and Language» click Language and add a
language package — English (US) works well. Exit the Settings app
and restart it, go back to Time and Language settings, then
Speech. The language you just added should appear in the Speech
Language drop down box, showing that it’s available as a speech
recognition language.
That should be sufficient — start Crew Chief and see if it works.
You might need to select English (US) as your speech language in
the Time and Language settings screen.
There’s also a checkbox in the Speech settings for «Recognise
non-native accents for this language». This may improve accuracy
for some users.
Note that you don’t have to change your display language to
English
In this article, we will discuss how to use Microsoft’s Speech Recognition Engine to write a virtual assistant application. Speech recognition apps are the way of the future and they are actually easy to write using Microsoft.Speech Recognition.
Speech Recognition Operations
A speech recognition application will typically perform the following basic operations:
- Start the speech recognizer.
- Create a recognition grammar.
- Load the grammar into the speech recognizer.
- Register for speech recognition event notification.
- Create a handler for the speech recognition event.
Free Speech Recognition API
If you are looking for a free solution for a hobby application or if you’re just trying to get your MVP built for your application, this is a nice place to start. You could swap over the code later to use for more expensive APIs available.
In this video, I also referenced Microsoft documentation, you could access this through this link. We used this example, they also have a console app built here.
The first step is to add the following line.
microsoft.speech.recognitionYou need to import the speech recognition engine first and to do that, adding the reference is a must. Navigate to your Solution Explorer and find “References” and search for speech.
You need to add a reference to the System.Speech assembly, which is located in the GAC.
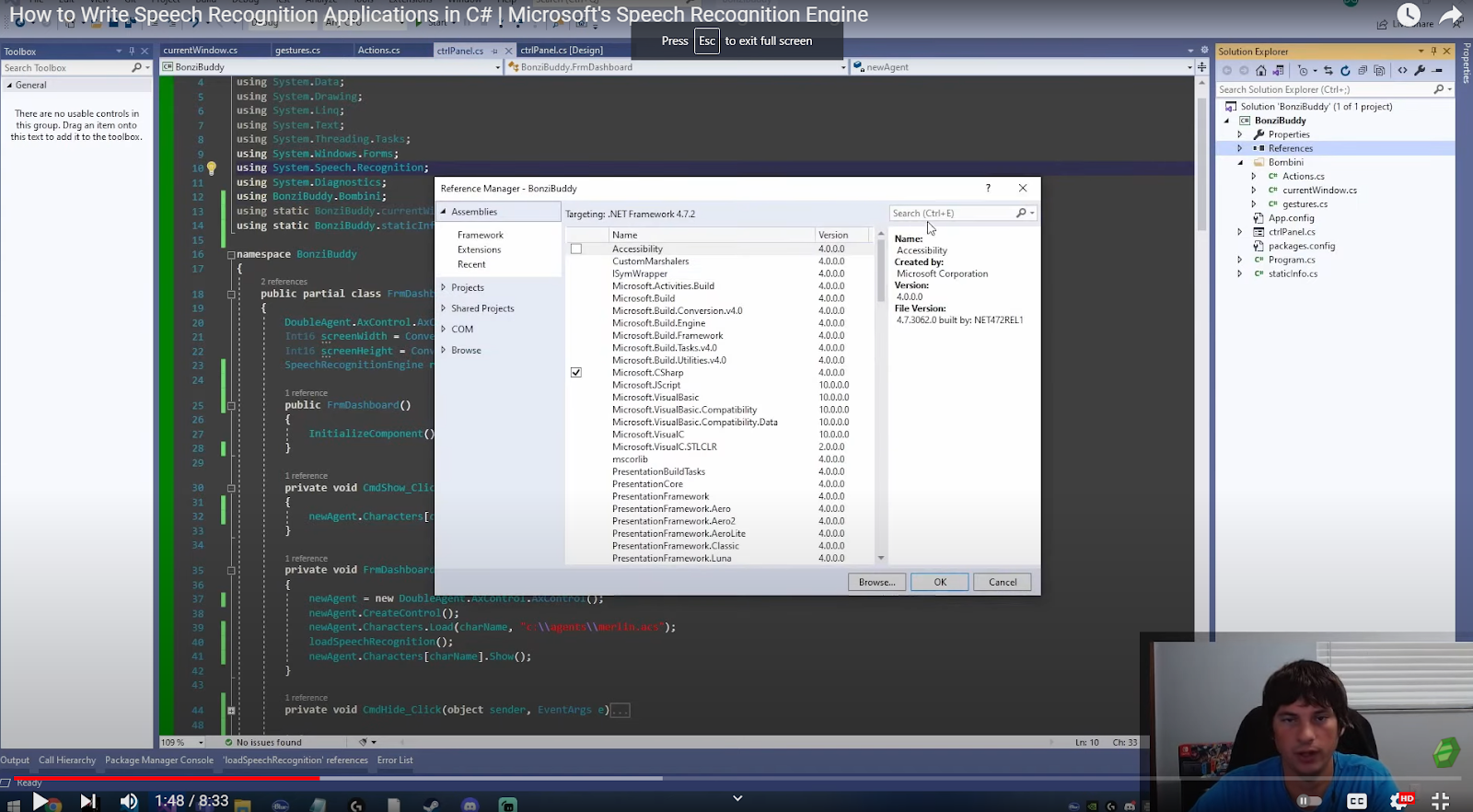
This is the only reference needed. It contains all of the following namespaces and classes. The System.Speech.Recognition namespace contains the Windows Desktop Speech technology types for implementing speech recognition.
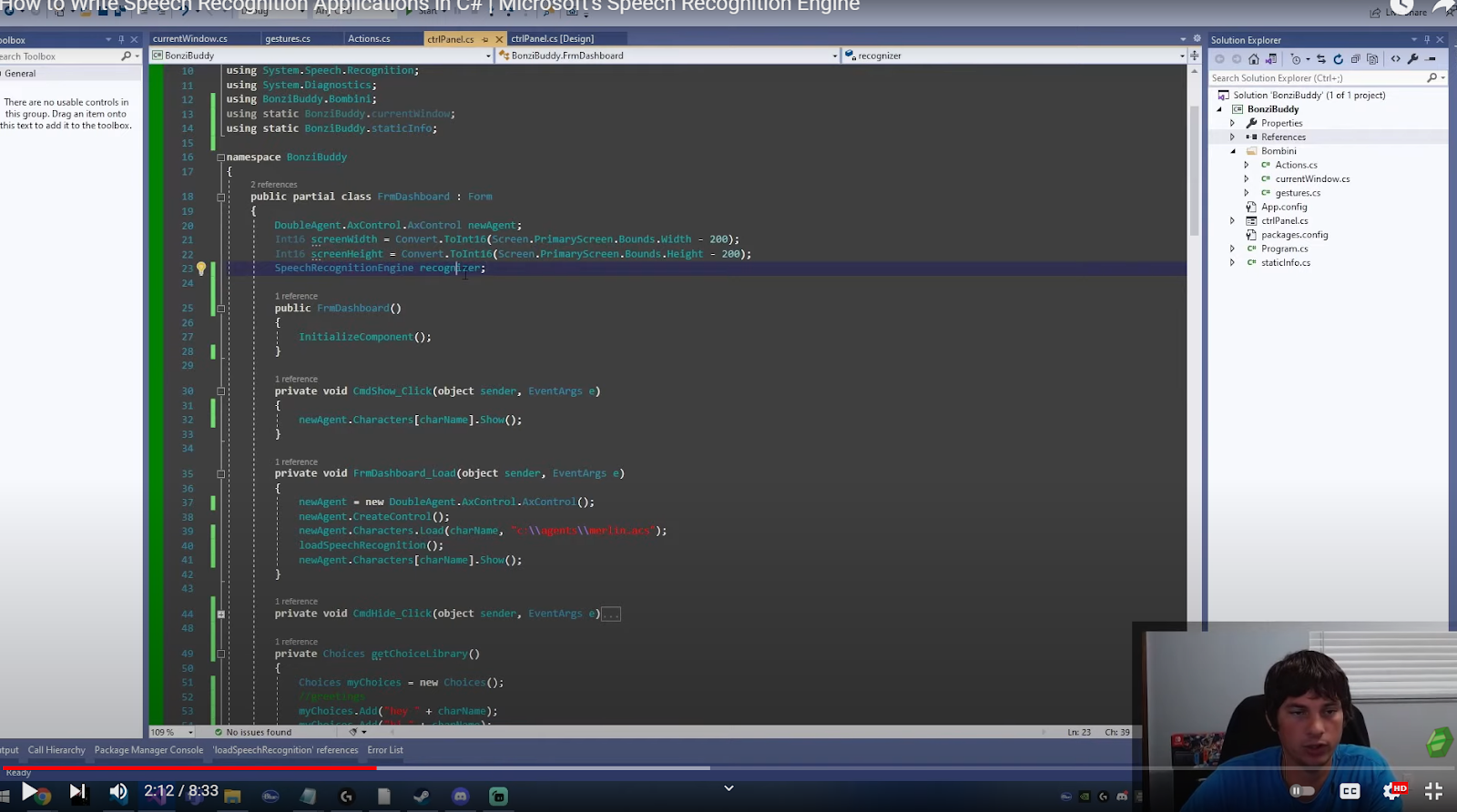
Before you can use the Microsoft SpeechRecognitionEngine, you have to set up several properties and invoke some methods. The next step now is to create a new recognizer. In the video, at the top of my class, I’ve created an empty object for the recognizer.
// Create an in-process speech recognizer for the en-US locale.
recognizer = new SpeechRecognitionEngine(new System.Globalization.CultureInfo("en-US"));
On load, I have the following code.
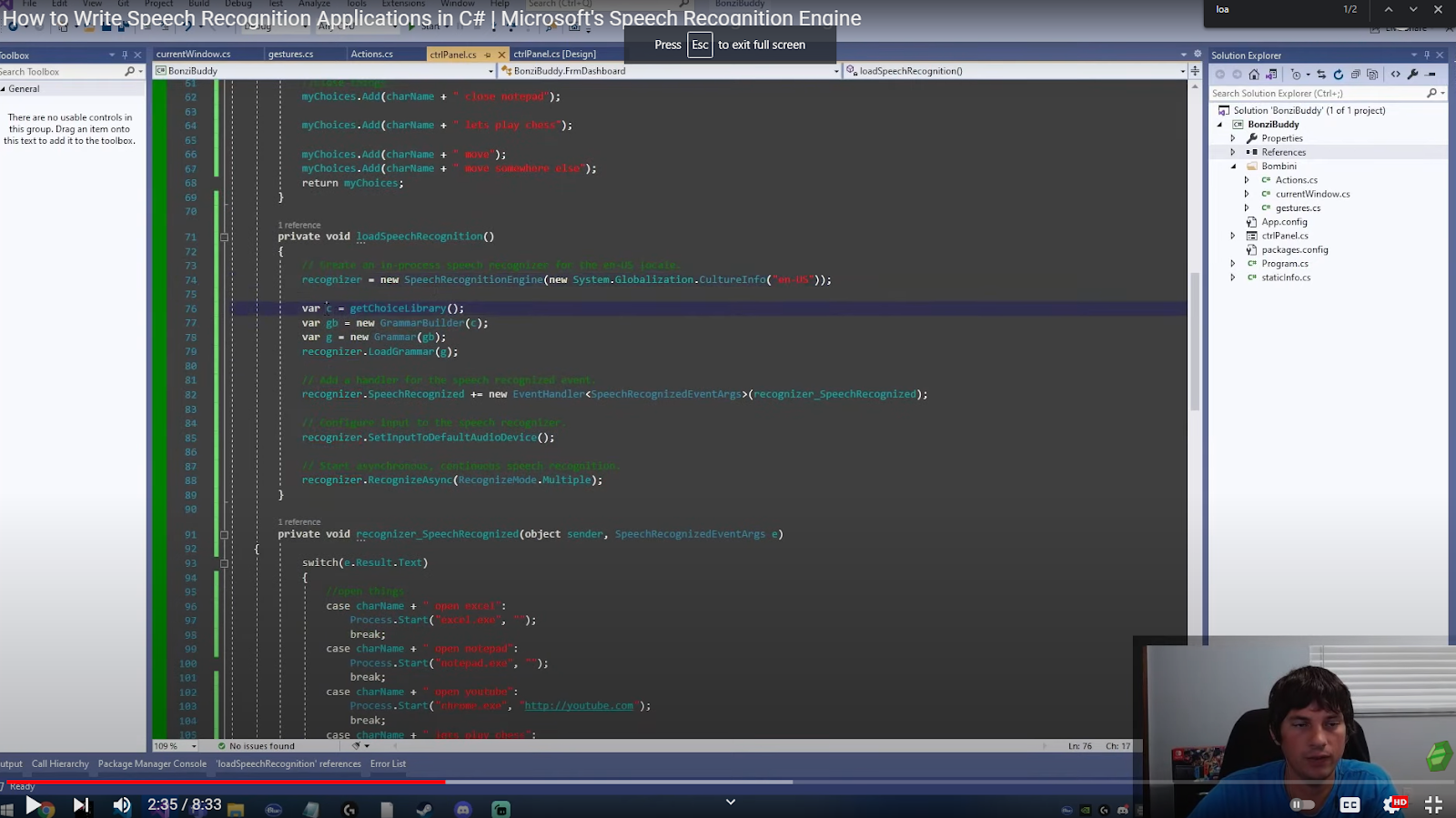
loadSpeechRecognition(); This is a function that has the loading code for the recognizer. We create a new speech recognition engine and pass it as a language because this works in multiple languages.
private void loadSpeechRecognition()
{
// Create an in-process speech recognizer for the en-US locale.
recognizer = new SpeechRecognitionEngine(new System.Globalization.CultureInfo("en-US"));
var gb = new GrammarBuilder(getChoiceLibrary());
var g = new Grammar(gb);
recognizer.LoadGrammar(g);
// Add a handler for the speech recognized event.
recognizer.SpeechRecognized += new EventHandler<SpeechRecognizedEventArgs>(recognizer_SpeechRecognized);
// Configure input to the speech recognizer.
recognizer.SetInputToDefaultAudioDevice();
// Start asynchronous, continuous speech recognition.
recognizer.RecognizeAsync(RecognizeMode.Multiple);
}
Instantiate your recognizer and then you are going to build this choice library.
If you look back to the SpeechRecognitionEngine Class that is linked in this article, they created a list of choices. In your application, you may create a function that returns a list of choices.
public Choices getChoiceLibrary()
{
Choices myChoices = new Choices();
//greetings
myChoices.Add("hey " + Agent.charName);
myChoices.Add("hi " + Agent.charName);
myChoices.Add("hello " + Agent.charName);
myChoices.Add("bye " + Agent.charName);
myChoices.Add("thanks " + Agent.charName);
//open things
myChoices.Add(Agent.charName + " open notepad");
myChoices.Add(Agent.charName + " open youtube");
myChoices.Add(Agent.charName + " open excel");
myChoices.Add(Agent.charName + " open discord");
myChoices.Add(Agent.charName + " open davinci");
myChoices.Add(Agent.charName + " play some music");
//Rocket
myChoices.Add(Agent.charName + " say nice shot");
myChoices.Add(Agent.charName + " say sorry");
myChoices.Add(Agent.charName + " say no problem");
myChoices.Add(Agent.charName + " say thanks");
myChoices.Add(Agent.charName + " say great pass");
myChoices.Add(Agent.charName + " say good game");
//Chrome
myChoices.Add(Agent.charName + " close this tab");
myChoices.Add(Agent.charName + " refresh this tab");
myChoices.Add(Agent.charName + " open gmail");
//close things
myChoices.Add(Agent.charName + " close notepad");
myChoices.Add(Agent.charName + " lets play chess");
myChoices.Add(Agent.charName + " open chess");
myChoices.Add(Agent.charName + " move");
myChoices.Add(Agent.charName + " move somewhere else");
return myChoices;
}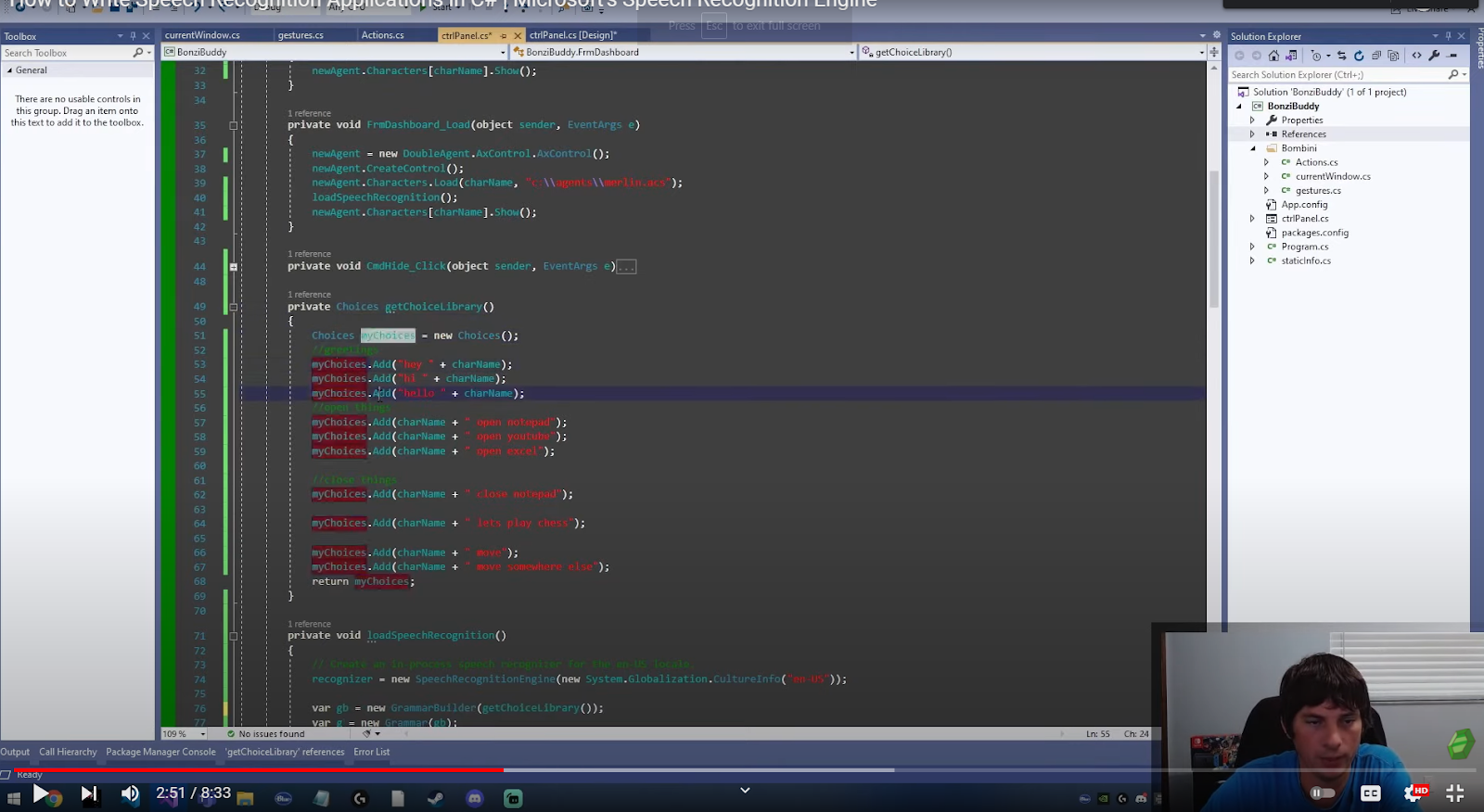
This code creates a new “choices” object and then adds your choices to it.
These pertain to the words the user can say. Make sure to add a list of choices because it heightens the accuracy of your command.
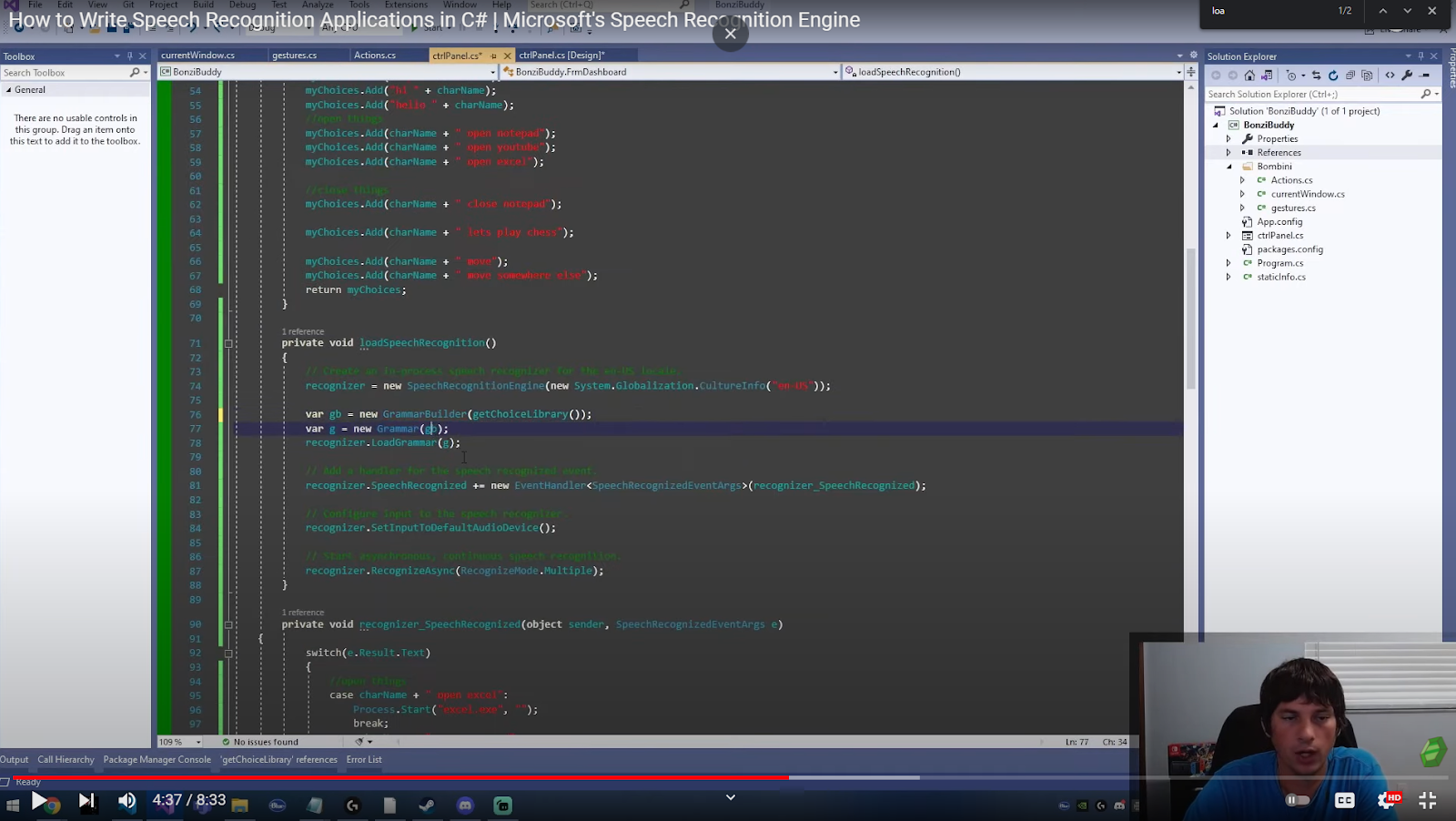
After you have built your set of choices, it will return back over here to this grammar builder. This is where you can tell the API how a sentence should look.

The next step is the speech recognized event handler.
public void recognizer_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
bombini.processSpeech(e.Result.Text);
}This action is what your recognition engine hears (something that matches with one of the choices), it will call whatever function you have built. I have it calling a function with a few different commands that it can run.
public void processSpeech(string speechText)
{
string currWinTitle = currentWindow.GetActiveWindowTitle();
switch (speechText)
{
//open things
case charName + " open excel":
myActions.startProcess("excel.exe", "");
myActions.animate(gestures.Write);
break;
case charName + " open notepad":
myActions.startProcess("notepad.exe", "");
myActions.animate(gestures.Write);
break;
case charName + " open youtube":
myActions.startProcess("chrome.exe", "http://youtube.com");
myActions.animate(gestures.Search);
break;
case charName + " open davinci":
myActions.startProcess("G:\\DaVinci Resolve\\Resolve.exe", "");
myActions.animate(gestures.Search);
break;
}
}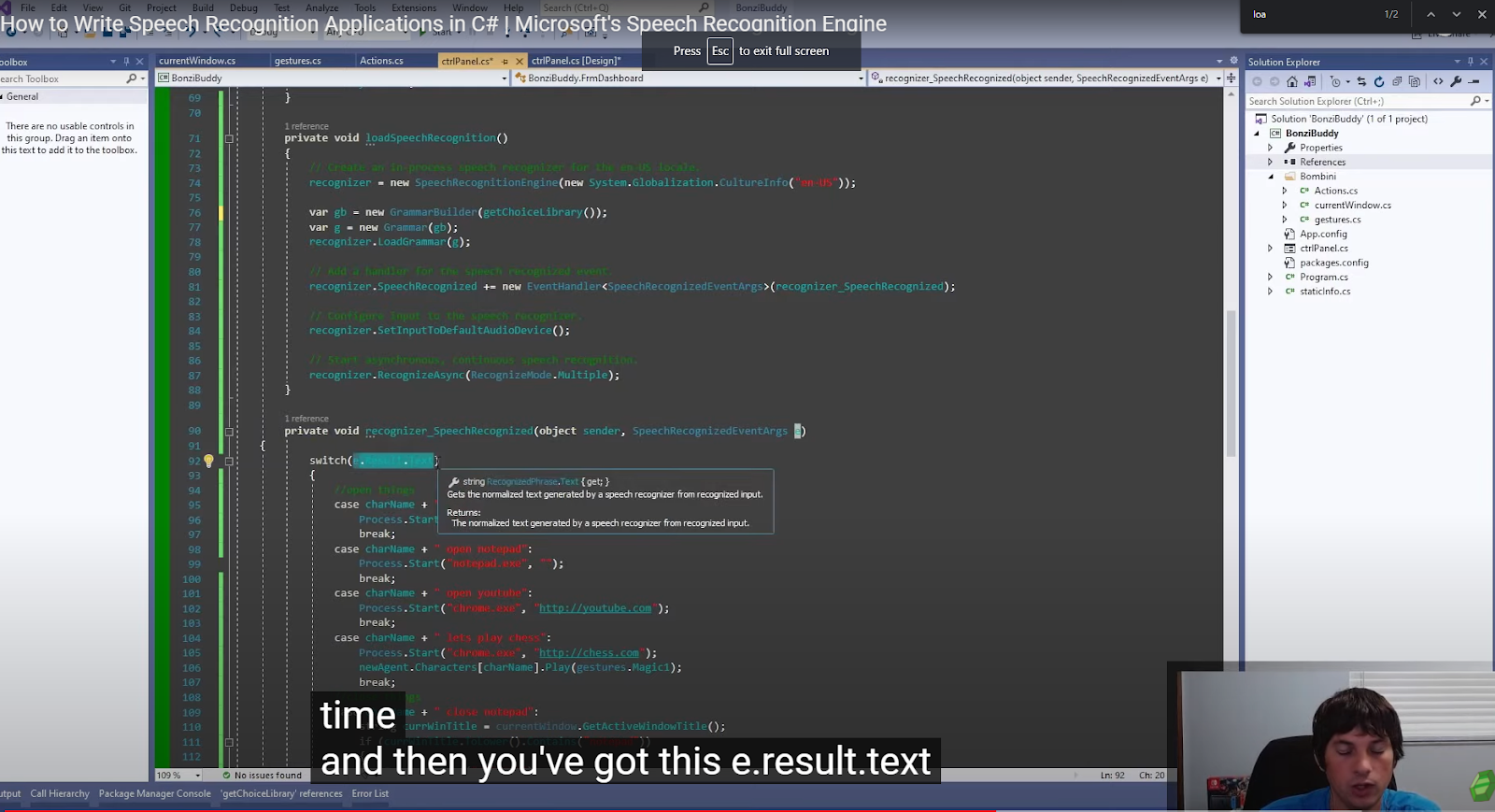
You could also take a look at “e.result.text” which is going to be the result that the recognizer will generate.
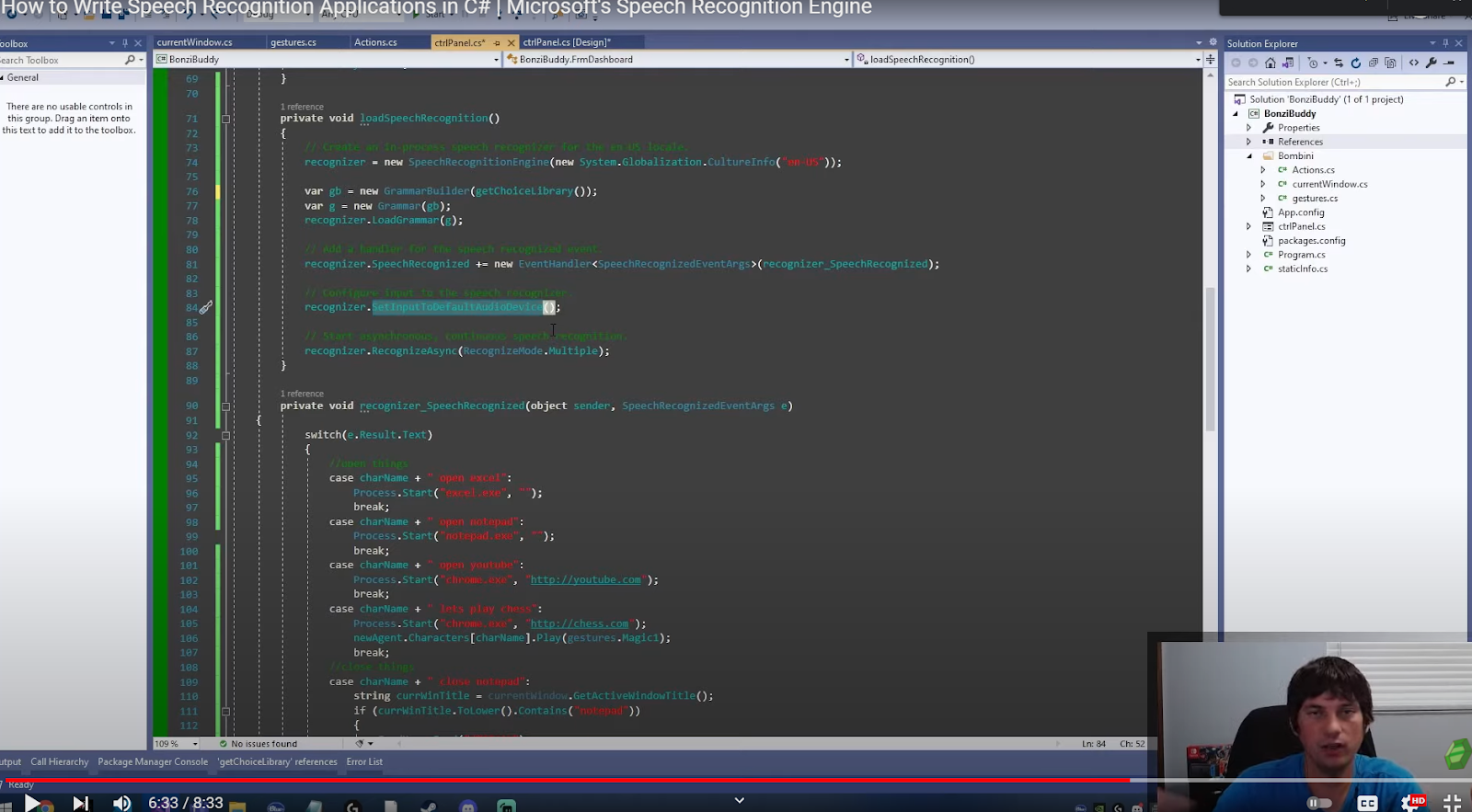
After setting up the event handler is set to listen to input from the default audio device. This determines if it will be listening on your microphone or listening to a headset.
Once you have the above set up your application should be able to listen on the correct device.
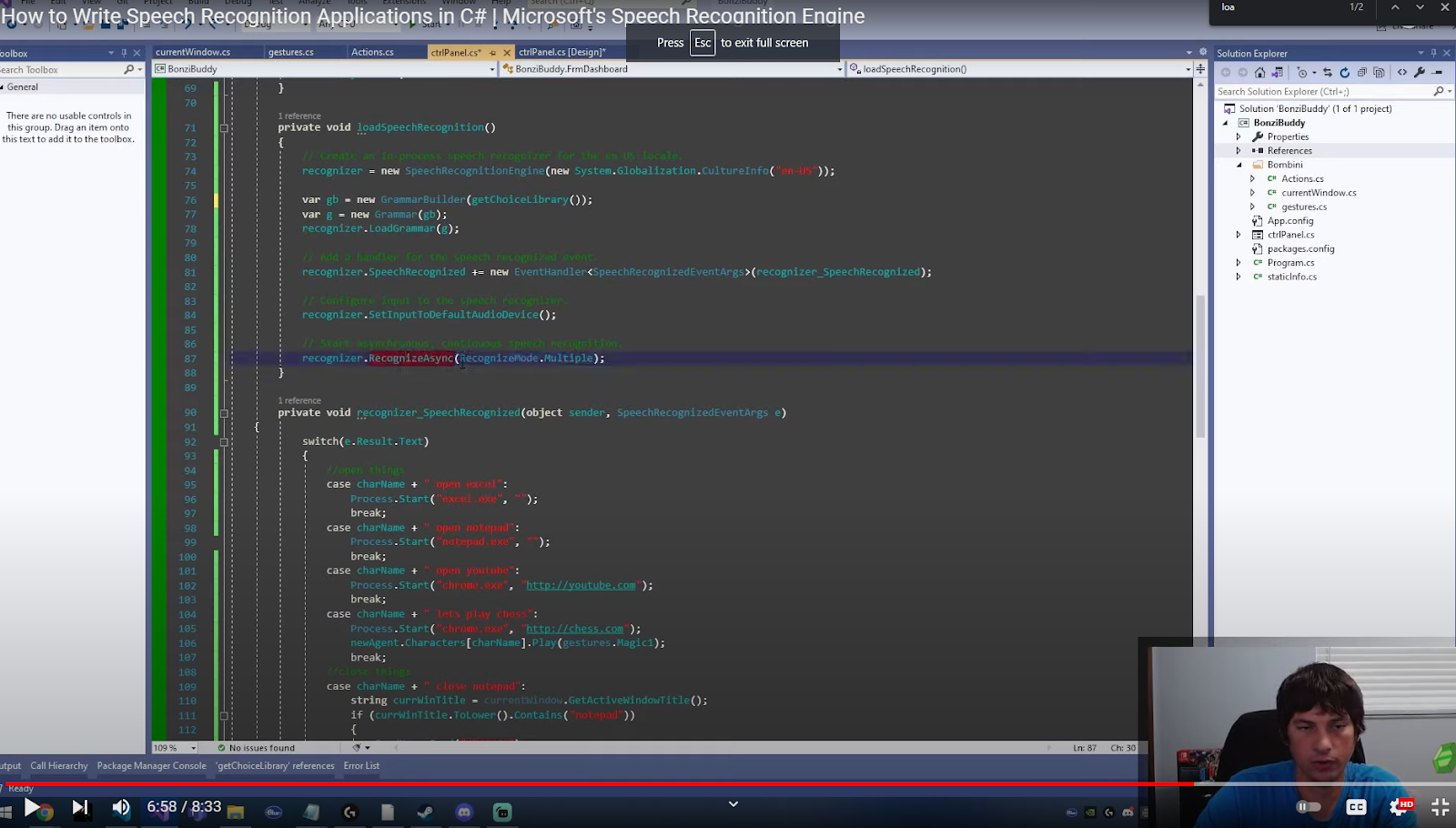
Once you have followed all of the above steps, we can start the Speech Recognition Engine asynchronously which will begin listening on another thread. Starting the Engine asynchronously makes it keep listening constantly on a second thread instead of blocking the current thread.
That is it! There are plenty of other possibilities to use the SAPI for, perhaps you could use it for innovative projects!
Thanks for reading and I’ll see you in the next one!