
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
Current Windows versions support Unicode, new Windows applications should use Unicode (UTF-8) and not 8-bit character encodings.[1]
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
Windows-125x series
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) UTF-8 (for files) |
ANSI code pages (officially called «Windows code pages»[2] after Microsoft accepted the former term being a misnomer[3]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1,[3] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[4]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[3]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
Early computer systems had limited storage and restricted the number of bits available to encode a character. Although earlier proprietary encodings had fewer, the American Standard Code for Information Interchange (ASCII) settled on seven bits: this was sufficient to encode a 96 member subset of the characters used in the US. As eight-bit bytes came to predominate, Microsoft (and others) expanded the repertoire to 224, to handle a variety of other uses such a box-drawing symbols. The need to provide precomposed characters for the Western European and South American markets required a different character set: Microsoft established the principle of code pages, one for each alphabet. For the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte but two or more bytes are needed for the ideographic sets used in the rest of the world. The code-page model was unable to handle this challenge.
Since the late 1990s, software and systems have adopted Unicode as their preferred character encoding format: Unicode is designed to handle millions of characters. All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding[clarification needed] of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but additionally supports UTF-8 (aka CP_UTF8) since Windows 10 version 1803.[5]
UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder).
The following Windows code pages exist:
Windows-125x series
[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages
[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
| ID | IBM Equivalent | Description |
|---|---|---|
| 37 | Country Extended Code Page for US, Canada, Netherlands, Portugal, Brazil, Australia, New Zealand[30] | |
| 500 | Country Extended Code Page for Belgium, Canada and Switzerland | |
| 870 | EBCDIC Latin-2 | |
| 875 | EBCDIC Greek | |
| 1026 | EBCDIC Latin-5 (Turkish) | |
| 1047 | Country Extended Code Page for Open Systems (POSIX) | |
| 1140 | Euro-sign Country Extended Code Page for US, Canada, Netherlands, Portugal, Brazil, Australia, New Zealand | |
| 1141 | Euro-sign Country Extended Code Page for Austria and Germany | |
| 1142 | Euro-sign Country Extended Code Page for Denmark and Norway | |
| 1143 | Euro-sign Country Extended Code Page for Finland and Sweden | |
| 1144 | Euro-sign Country Extended Code Page for Italy | |
| 1145 | Euro-sign Country Extended Code Page for Spain and Latin America | |
| 1146 | Euro-sign Country Extended Code Page for UK | |
| 1147 | Euro-sign Country Extended Code Page for France | |
| 1148 | Euro-sign Country Extended Code Page for Belgium, Canada and Switzerland | |
| 1149 | Euro-sign Country Extended Code Page for Iceland | |
| 20273 | 273 | Country Extended Code Page for Germany |
| 20277 | 277 | Country Extended Code Page for Denmark/Norway |
| 20278 | 278 | Country Extended Code Page for Finland/Sweden |
| 20280 | 280 | Country Extended Code Page for Italy |
| 20284 | 284 | Country Extended Code Page for Latin America/Spain |
| 20285 | 285 | Country Extended Code Page for United Kingdom |
| 20290 | 290 | Japanese Katakana EBCDIC |
| 20297 | 297 | Country Extended Code Page for France |
| 20420 | 420 | EBCDIC Arabic |
| 20423 | 423 | EBCDIC Greek with Extended Latin |
| 20424 | — | x-EBCDIC-KoreanExtended |
| 20833 | 833 | Korean EBCDIC for N-Byte Hangul |
| 20838 | 838 | EBCDIC Thai |
| 20871 | 871 | Country Extended Code Page for Iceland |
| 20880 | 880 | EBCDIC Cyrillic (DKOI) |
| 20905 | 905 | EBCDIC Latin-3 (Maltese, Esperanto and Turkish) |
| 20924 | 924 | EBCDIC Latin-9 (including Euro sign) for Open Systems (POSIX) |
| 21025 | 1025 | EBCDIC Cyrillic (DKOI) with section sign |
| 21027 | (1027) | Japanese EBCDIC (an incomplete implementation of IBM code page 1027,[31] now deprecated)[32] |
| ID | IBM Equivalent | Description |
|---|---|---|
| 1200 | 1202, 1203 | Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32] |
| 1201 | 1200, 1201 | Unicode (UTF-16BE). Available only to managed applications.[32] |
| 12000 | 1234, 1235 | UTF-32. Available only to managed applications.[32] |
| 12001 | 1232, 1233 | UTF-32. Big-endian. Available only to managed applications.[32] |
| 65000 | — | Unicode (UTF-7) |
| 65001 | 1208, 1209 | Unicode (UTF-8) |
Macintosh compatibility code pages
[edit]
| ID | IBM Equivalent | Description |
|---|---|---|
| 10000 | 1275 | Apple Macintosh Roman |
| 10001 | — | Apple Macintosh Japanese |
| 10002 | — | Apple Macintosh Chinese (traditional) (BIG-5) |
| 10003 | — | Apple Macintosh Korean |
| 10004 | — | Apple Macintosh Arabic |
| 10005 | — | Apple Macintosh Hebrew |
| 10006 | 1280 | Apple Macintosh Greek |
| 10007 | 1283 | Apple Macintosh Cyrillic |
| 10008 | — | Apple Macintosh Chinese (simplified) (GB 2312) |
| 10010 | 1285 | Apple Macintosh Romanian |
| 10017 | — | Apple Macintosh Ukrainian |
| 10021 | — | Apple Macintosh Thai |
| 10029 | 1282 | Apple Macintosh Roman II / Central Europe |
| 10079 | 1286 | Apple Macintosh Icelandic |
| 10081 | 1281 | Apple Macintosh Turkish |
| 10082 | 1284 | Apple Macintosh Croatian |
ISO 8859 code pages
[edit]
| ID | IBM Equivalent | Description |
|---|---|---|
| 28591 | 819, 5100 | ISO-8859-1 – Latin-1 |
| 28592 | 912 | ISO-8859-2 – Latin-2 |
| 28593 | 913 | ISO-8859-3 – Latin-3 or South European |
| 28594 | 914 | ISO-8859-4 – Latin-4 or North European |
| 28595 | 915 | ISO-8859-5 – Latin/Cyrillic |
| 28596 | — | ISO-8859-6 – Latin/Arabic |
| 28597 | 813, 4909, 9005 | ISO-8859-7 – Latin/Greek (1987 edition, i.e. without euro sign, drachma sign or iota subscript)[33] |
| 28598 | — | ISO-8859-8 – Latin/Hebrew (visual order; 1988 edition, i.e. without LRM and RLM)[33] |
| 28599 | 920 | ISO-8859-9 – Latin-5 or Turkish |
| 28600 | 919 | ISO-8859-10 – Latin-6 or Nordic |
| 28601 | — | ISO-8859-11 – Latin/Thai |
| 28602 | — | ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported) |
| 28603 | 921 | ISO-8859-13 – Latin-7 or Baltic Rim |
| 28604 | — | ISO-8859-14 – Latin-8 or Celtic |
| 28605 | 923 | ISO-8859-15 – Latin-9 |
| 28606 | — | ISO-8859-16 – Latin-10 or South-Eastern European |
| 38596 | 1089 | ISO-8859-6-I – Latin/Arabic (logical bidirectional order) |
| 38598 | 916, 5012 | ISO-8859-8-I – Latin/Hebrew (logical bidirectional order; 1988 edition, i.e. without LRM and RLM)[33] |
| ID | IBM Equivalent | Description |
|---|---|---|
| 20105 | 1009 | 7-bit IA5 IRV (Western European)[34][35][36] |
| 20106 | 1011 | 7-bit IA5 German (DIN 66003)[34][35][37] |
| 20107 | 1018 | 7-bit IA5 Swedish (SEN 850200 C)[34][35][38] |
| 20108 | 1016 | 7-bit IA5 Norwegian (NS 4551-2)[34][35][39] |
| 20127 | 367 | 7-bit ASCII[34][35][40] |
| 20261 | 1036 | T.61 (T.61-8bit) |
| 20269 | ? | ISO-6937 |
| ID | IBM Equivalent | Description |
|---|---|---|
| 20866 | 878 | Russian – KOI8-R |
| 21866 | 1167, 1168 | Ukrainian – KOI8-U (or KOI8-RU in some versions)[41] |
Problems arising from the use of code pages
[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
- ^ «Unicode and character sets». Microsoft. 2023-06-13. Retrieved 2024-05-27.
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre (11 March 2021). «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c Mozilla Foundation. «Relationship with Windows Code Pages». Crate encoding_rs. Docs.rs.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
The May 2019 update of Windows 10 introduced the possibility of setting the ActiveCodePage property of an executable to UTF-8. This is done via the application manifest. The documentation is super-vague on the technical details and history, and in usual Microsoft fashion the functionality is obscured and the little desirable kill-a-gnat can only be done by costly nuclear bombing, so to speak — why let something simple be simple if it can be wrapped in military standard complexity?
But it means that with Visual C++ 2019 one can now use UTF-8 encoding for GUI applications, and for the output of console programs, without any encoding conversions in the code.
In particular, with UTF-8 active process codepage the arguments of main now come handily UTF-8 encoded, which means that they can now represent general filenames also in Windows. Hurray! Yippi!
However, interactive console input of UTF-8 is still limited to ASCII at the API-level. And the MinGW g++ 9.2 compiler’s default standard library implementation doesn’t support UTF-8 in the C and C++ locale machinery, e.g in setlocale, probably because it employs an old version of Microsoft’s runtime library. That means that FILE* or iostreams UTF-8 console output with MinGW g++ 9.2 only works for the default “C” locale.
I experimented by setting the ANSI codepage default in the registry to 65001, the UTF-8 codepage number. After rebooting the console windows came up with active codepage 65001, even though the OEM codepage default was the same old one (850 in my case). That indicates an effort on Microsoft’s part to support UTF-8 all the way in Windows, which if so is fantastically good.
An example application manifest.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<assembly manifestVersion="1.0" xmlns="urn:schemas-microsoft-com:asm.v1">
<assemblyIdentity type="win32" name="UTF-8 app example" version="6.0.0.0"/>
<application>
<windowsSettings>
<activeCodePage xmlns="http://schemas.microsoft.com/SMI/2019/WindowsSettings"
>UTF-8</activeCodePage>
</windowsSettings>
</application>
<dependency>
<dependentAssembly>
<assemblyIdentity
type="win32"
name="Microsoft.Windows.Common-Controls"
version="6.0.0.0"
processorArchitecture="*"
publicKeyToken="6595b64144ccf1df"
language="*"
/>
</dependentAssembly>
</dependency>
</assembly>
The second assemblyIdentity part has nothing to do with the UTF-8 support, it just corrects a practically unusable default for the look and feel of buttons etc. Essentially this manifest corrects the two “wrong” defaults: the narrow text encoding, and the look ’n feel. From within an application with this manifest it looks as both CP_ACP (the global default) and CP_THREAD_ACP (the mysterious thread codepage) are UTF-8, codepage 65001.
In my experimentation UTF-8 had to be specified in uppercase, and it did not work with whitespace such as space or newline at either side.
An example resource script:
#include <windows.h> 1 RT_MANIFEST "resources/application-manifest.xml"
По умолчанию cmd.exe использует кодировку cp866. Текущую кодировку можно посмотреть командой chcp. Иногда возникает необходимость использовать в терминале юникод. Для этого необходимо использовать шрифт «Lucida Console» и переключить кодировку командой
>chcp <codepage>
Где параметр <codepage> для UTF-8 равен 65001

Время на прочтение9 мин
Количество просмотров47K
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие.
По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Виды консолей
В общем случае функции консоли таковы:
-
управление операционной системой и системным окружением приложений на основе применения стандартных системных устройств ввода-вывода (экран и клавиатура), использования команд операционной системы и/или собственно консоли;
-
запуск приложений и обеспечение их доступа к стандартным потокам ввода-вывода системы, также с помощью стандартных системных устройств ввода-вывода.
Основная консоль Windows — командная строка или иначе командный процессор (CMD). Большие возможности предоставляют оболочки PowerShell (PS), Windows PowerShell (WPS) и Terminal. По умолчанию Windows устанавливает Windows Power Shell мажорной версией до 5, однако предлагает перейти на новую версию — 7-ку, имеющую принципиальное отличие (вероятно, начинающееся с 6-ки) — кроссплатформенность. Terminal — также отдельно уставливаемое приложение, по сути интегратор всех ранее установленных оболочек PowerShell и командной строки.
Отдельным видом консоли можно считать консоль отладки Visual Studio (CMD-D).
Конфликт кодировок
Полностью локализованная консоль в идеале должна поддерживать все мыслимые и немыслимые кодировки приложений, включая свои собственные команды и команды Windows, меняя «на лету» кодовые страницы потоков ввода и вывода. Задача нетривиальная, а иногда и невозможная — кодовые страницы DOS (CP437, CP866) плохо совмещаются с кодовыми страницами Windows и Unicode.
История кодировок здесь: О кодировках и кодовых страницах / Хабр (habr.com)
Исторически кодовой страницей Windows является CP1251 (Windows-1251, ANSI, Windows-Cyr), уверенно вытесняемая 8-битной кодировкой Юникода CP65001 (UTF-8, Unicode Transformation Format), в которой выполняется большинство современных приложений, особенно кроссплатформенных. Между тем, в целях совместимости с устаревшими файловыми системами, именно в консоли Windows сохраняет базовые кодировки DOS — CP437 (DOSLatinUS, OEM) и русифицированную CP866 (AltDOS, OEM).
Совет 1. Выполнять разработку текстовых файлов (программных кодов, текстовых данных и др.) исключительно в кодировке UTF-8. Мир любит Юникод, а кроссплатформенность без него вообще невозможна.
Совет 2. Периодически проверять кодировку, например в текстовом редакторе Notepad++. Visual Studio может сбивать кодировку, особенно при редактировании за пределами VS.
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Были запущены три консоли — CMD, PS и WPS. В каждой консоли менялась кодовая страница с помощью команды CHCP, выполнялась команда Echo c двуязычной строкой в качестве параметра (табл. 1), а затем в консоли запускалось тестовое приложение, исходные файлы которого были созданы в кодировке UTF-8 (CP65001): первая строка формируется и направляется в поток главным модулем, вторая вызывается им же, формируется в подключаемой библиотеке классов и направляется в поток опять главным модулем, третья строка полностью формируется и направляется в поток подключаемой библиотекой.
Команды и код приложения под катом
команды консоли:
-
> Echo ffffff фффффф // в командной строке
-
PS> Echo ffffff фффффф // в PowerShell
-
PS> Echo ffffff ?????? // так выглядит та же команда в Windows PowerShell
код тестового приложения:
using System;
using ova.common.logging.LogConsole;
using Microsoft.Extensions.Logging;
using ova.common.logging.LogConsole.Colors;
namespace LoggingConsole.Test
{
partial class Program
{
static void Main2(string[] args)
{
ColorLevels.ColorsDictionaryCreate();
Console.WriteLine("Hello World! Привет, мир!"); //вывод строки приветствия на двух языках
LogConsole.Write("Лог из стартового проекта", LogLevel.Information);
Console.WriteLine($"8. Active codepage: input {Console.InputEncoding.CodePage}, output {Console.OutputEncoding.CodePage}");
Console.ReadKey();
}
}
}Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.
Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.

Сoвет 3. Про PowerShell забываем раз и навсегда. Ну может не навсегда, а до следующей мажорной версии…
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Совет 4. Перед запуском приложения необходимо проверить кодовую страницу консоли командой CHCP и ей же изменить кодировку на совместимую — 866, 1251, 65001.
Совет 5. Можно установить кодовую страницу консоли по умолчанию. Кратко: в разделе реестра \HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor добавить или изменить значение параметра Autorun на: chcp <номер кодовой страницы>. Очень подробно здесь: Изменить кодовую страницу консоли Windows по умолчанию на UTF-8 (qastack.ru), оригинал на английском здесь: Change default code page of Windows console to UTF-8.
Проблемы консолей Visual Studio
В Visual Studio имеется возможность подключения консолей, по умолчанию подключены командная строка для разработчика и Windows PowerShell для разработчика. К достоинствам можно отнести возможности определения собственных параметров консоли, отдельных от общесистемных, а также запуск консоли непосредственно в директории разработки. В остальном — это обычные стандартные консоли Windows, включая, как показано ранее, установленную кодовую страницу по умолчанию.
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Совет 6. Тестирование приложения целесообразно выполнять во внешних консолях, более дружелюбных к локализации.
Анализ проблем консолей был бы не полон без ответа на вопрос — можно ли запустить консольное приложение без консоли? Можно — любой файл «.exe» запустится двойным кликом, и даже откроется окно приложения. Однако консольное приложение, по крайней мере однопоточное, по двойному клику запустится, но консольный режим не поддержит — все консольные вводы-выводы будут проигнорированы, и приложение завершится
Локализация отладочной консоли Visual Studio
Отладочная консоль — наиболее востребованная консоль разработчика, гораздо более удобная, чем внешняя консоль, поэтому резонно приложить максимум усилий для ее локализации.
На самом деле, правильнее говорить о локализации приложения в консоли — это важное уточнение. Microsoft по этому поводу высказывается недвусмысленно: «Programs that you start after you assign a new code page use the new code page. However, programs (except Cmd.exe) that you started before assigning the new code page will continue to use the original code page». Иными словами, консоль можно локализовать когда угодно и как угодно, но приложение будет локализовано в момент стабилизации взаимодействия с консолью в соответствии с текущей локализацией консоли, и эта локализация сохранится до завершения работы приложения. В связи с этим возникает вопрос — в какой момент окончательно устанавливается связь консоли и приложения?
Важно! Приложение окончательно стабилизирует взаимодействие с консолью в момент начала ввода-вывода в консоль, благодаря чему и появляется возможность программного управления локализацией приложения в консоли — до первого оператора ввода-вывода.
Ниже приведен пример вывода тестового приложения в консоль, иллюстрирующий изложенное. Метод Write получает номера текущих страниц, устанавливает новые кодовые страницы вводного и выводного потоков, выполняет чтение с консоли и записывает выводную строку, содержащий русский текст, в том числе считанный с консоли, обратно в консоль. Операция повторяется несколько раз для всех основных кодовых страниц, упомянутых ранее.
F:\LoggingConsole.Test\bin\Release\net5.0>chcp
Active code page: 1251
F:\LoggingConsole.Test\bin\Release\net5.0>loggingconsole.test
Codepages: current 1251:1251, setted 437:437, ΓΓεΣΦ∞ 5 ±Φ∞ΓεδεΓ ∩ε-≡≤±±ΩΦ: Θ÷≤Ωσ=Θ÷≤Ωσ
Codepages: current 437:437, setted 65001:65001, 5 -: =
Codepages: current 65001:65001, setted 1252:1252, ââîäèì 5 ñèìâîëîâ ïî-ðóññêè: éöóêå=éöóêå
Codepages: current 1252:1252, setted 1251:1251, вводим 5 символов по-русски: йцуке=йцуке
Codepages: current 1251:1251, setted 866:866, ттюфшь 5 ёшьтюыют яю-Ёєёёъш: щЎєъх=щЎєъх
Codepages: current 866:866, setted 1251:1251, вводим 5 символов по-русски: йцуке=йцуке
Codepages: current 1251:1251, setted 1252:1252, ââîäèì 5 ñèìâîëîâ ïî-ðóññêè: éöóêå=éöóêå
F:\LoggingConsole.Test\bin\Release\net5.0>chcp
Active code page: 1252-
приложение запущено в консоли с кодовыми страницами 1251 (строка 2);
-
приложение меняет кодовые страницы консоли (current, setted);
-
приложение остановлено в консоли с кодовыми страницами 1252 (строка 11, setted);
-
по окончании работы приложения изменения консоли сохраняются (строка 14 — Active codepage 1252);
-
Приложение адекватно локализовано только в случае совпадения текущих кодовых страниц консоли (setted 1251:1251) с начальными кодовыми страницами (строки 8 и 10).
Код тестового приложения под катом
using System;
using System.Runtime.InteropServices;
namespace LoggingConsole.Test
{
partial class Program
{
[DllImport("kernel32.dll")] static extern uint GetConsoleCP();
[DllImport("kernel32.dll")] static extern bool SetConsoleCP(uint pagenum);
[DllImport("kernel32.dll")] static extern uint GetConsoleOutputCP();
[DllImport("kernel32.dll")] static extern bool SetConsoleOutputCP(uint pagenum);
static void Main(string[] args)
{
Write(437);
Write(65001);
Write(1252);
Write(1251);
Write(866);
Write(1251);
Write(1252);
}
static internal void Write(uint WantedIn, uint WantedOut)
{
uint CurrentIn = GetConsoleCP();
uint CurrentOut = GetConsoleOutputCP();
Console.Write($"current {CurrentIn}:{CurrentOut} - текущая кодировка, "); /*wanted {WantedIn}:{WantedOut},*/
SetConsoleCP(WantedIn);
SetConsoleOutputCP(WantedOut);
Console.Write($"setted {GetConsoleCP()}:{GetConsoleOutputCP()} - новая кодировка, ");
Console.Write($"вводим 3 символа по-русски: ");
string str = "" + Console.ReadKey().KeyChar.ToString();
str += Console.ReadKey().KeyChar.ToString();
str += Console.ReadKey().KeyChar.ToString();
Console.WriteLine($"={str}");
}
static internal void Write(uint ChangeTo)
{
Write(ChangeTo, ChangeTo);
}
}
}
Программное управление кодировками консоли — это единственный способ гарантированной адекватной локализацией приложения в консоли. Языки .Net такой возможности не предоставляют, однако предоставляют функции WinAPI: SetConsoleCP(uint numcp) и SetConsoleOutputCP(uint numcp), где numcp — номер кодовой страницы потоков ввода и вывода соответственно. Подробнее здесь: Console Functions — Windows Console | Microsoft Docs. Пример применения консольных функций WInAPI можно посмотреть в тестовом приложении под катом выше.
Совет 7. Обязательный и повторный! Функции SetConsoleCP должны размещаться в коде до первого оператора ввода-вывода в консоль.
Стратегия локализации приложения в консоли
-
Удалить приложение PowerShell (если установлено), сохранив Windows PowerShell;
-
Установить в качестве кодовую страницу консоли по умолчанию CP65001 (utf-8 Unicode) или CP1251 (Windows-1251-Cyr), см. совет 5;
-
Разработку приложений выполнять в кодировке utf-8 Unicode;
-
Контролировать кодировку файлов исходных кодов, текстовых файлов данных, например с помощью Notepad++;
-
Реализовать программное управление локализацией приложения в консоли, пример ниже под катом:
Пример программной установки кодовой страницы и локализации приложения в консоли
using System;
using System.Runtime.InteropServices;
namespace LoggingConsole.Test
{
partial class Program
{
static void Main(string[] args)
{
[DllImport("kernel32.dll")] static extern bool SetConsoleCP(uint pagenum);
[DllImport("kernel32.dll")] static extern bool SetConsoleOutputCP(uint pagenum);
SetConsoleCP(65001); //установка кодовой страницы utf-8 (Unicode) для вводного потока
SetConsoleOutputCP(65001); //установка кодовой страницы utf-8 (Unicode) для выводного потока
Console.WriteLine($"Hello, World!");
}
}
}
-
Unicode in PowerShell
-
Change System Locale to Use UTF-8 Encoding in Windows PowerShell
-
Set Encoding in
$PSDefaultParameterValuesVariable to Use UTF-8 Encoding in Windows PowerShell -
Use the
chcpCommand to Switch to UTF-8 Encoding in Windows PowerShell -
Benefits of Using UTF-8 Encoding in PowerShell
-
Conclusion

UTF-8 encoding, represented by CHCP 65001 in PowerShell, is a pivotal tool for working with multilingual and special characters in the console.
This article will provide a comprehensive guide on how to utilize UTF-8 encoding in PowerShell, from understanding its significance to practical implementation.
Unicode in PowerShell
Unicode is a worldwide character encoding standard. It defines how characters in text files, web pages, and other documents are represented.
The computer system uses Unicode to manipulate characters and strings. The default encoding in PowerShell is Windows-1252.
Unicode was developed to support characters from all languages of the world. PowerShell supports a Unicode character encoding by default.
UTF-8 and UTF-16 are the most common Unicode encodings. PowerShell always uses BOM in all Unicode encodings except UTF7.
The BOM (byte-order-mark) is a Unicode signature included in the first few bytes of a file or text stream that indicates the Unicode encoding.
Understanding UTF-8 Encoding
UTF-8 is a character encoding standard that uses variable-width encoding to represent text. It’s capable of encoding virtually all characters in Unicode, making it the most widely used character encoding on the internet.
In the context of PowerShell, UTF-8 encoding ensures that characters from different languages, symbols, and special characters are displayed and processed correctly in the console window.
Change System Locale to Use UTF-8 Encoding in Windows PowerShell
There is an option to change the system locale (current language for non-Unicode programs) in Windows. But this feature is still in beta.
Go to Region Settings from the Control Panel or open intl.cpl from the Run program (Windows+R).
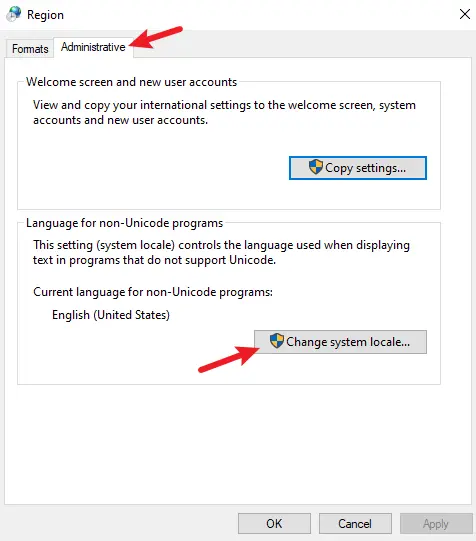
Open the Administrative tab and click Change system locale. Then, check the Beta option, as shown in the image below.
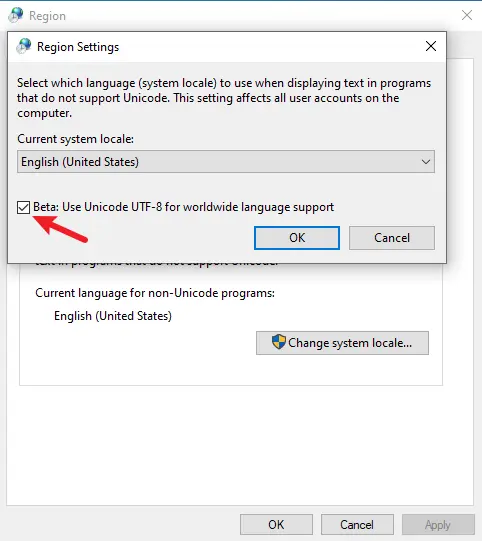
After that, press OK and restart the computer to apply the settings.
After restarting the computer, you can check the $OutputEncoding variable to view the current encoding.
Output:
As you can see, the current encoding is Unicode (UTF-8).
BodyName : utf-8
EncodingName : Unicode (UTF-8)
HeaderName : utf-8
WebName : utf-8
WindowsCodePage : 1200
IsBrowserDisplay : True
IsBrowserSave : True
IsMailNewsDisplay : True
IsMailNewsSave : True
IsSingleByte : False
EncoderFallback : System.Text.EncoderReplacementFallback
DecoderFallback : System.Text.DecoderReplacementFallback
IsReadOnly : True
CodePage : 65001
Now, you can view the characters of other languages in PowerShell.
Output:
Set Encoding in $PSDefaultParameterValues Variable to Use UTF-8 Encoding in Windows PowerShell
$PSDefaultParameterValues is a built-in automatic variable in PowerShell that allows you to set default values for cmdlet parameters. This means you can specify default values for parameters of cmdlets without having to explicitly provide them every time you use the cmdlet.
You can run the following command to activate the UTF-8 encoding in PowerShell.
$PSDefaultParameterValues = @{'*:Encoding' = 'utf8' }
It is only valid for the current PowerShell console. It will be reset to default after you exit the PowerShell window.
Output:
Several cmdlets in PowerShell have the -Encoding parameter to specify the encoding for different character sets. Some of them are Add-Content, Set-Content, Get-Content, Export-Csv, Out-File, etc.
The -Encoding parameter supports these values: ascii, bigendianunicode, oem, unicode, utf7, utf8, utf8BOM, utf8NoBOM, utf32.
Use the chcp Command to Switch to UTF-8 Encoding in Windows PowerShell
To switch to UTF-8 encoding in PowerShell, use the chcp command followed by 65001:
This command tells PowerShell to use UTF-8 encoding for character input and output.
Here’s what this command does in detail:
-
chcp: This is a command in the Windows command prompt and PowerShell. It stands for"Change Code Page". The code page determines how characters are encoded and displayed in the console window. -
65001: In this context,65001represents the code page for UTF-8 encoding. UTF-8 is a variable-width character encoding capable of encoding all possible characters, or code points, in Unicode.- UTF-8: It’s a widely used character encoding that can represent almost all characters from all human languages. It’s especially prevalent on the internet.
-
Changing to UTF-8 (
65001): When you runchcp 65001, you’re telling PowerShell to use UTF-8 encoding for character input and output in the console. This can be helpful when working with text data that includes characters from different languages and symbols.For instance, if you’re dealing with files or data that contain non-English characters, setting the code page to UTF-8 ensures that these characters are displayed correctly in the console.
Resetting to Default Code Page
Remember that changing the code page might affect how some console applications behave, so it’s generally a good practice to reset it to the default code page (usually 437 for English) when you’re done using UTF-8.
To reset the code page to the default, you can use the command:
This will switch back to the default code page for your system, which is suitable for English text.
Benefits of Using UTF-8 Encoding in PowerShell
- Multilingual Support: UTF-8 allows PowerShell to handle text in multiple languages, ensuring correct display and processing of characters from different scripts.
- Special Characters: It’s crucial when dealing with special characters like emojis or mathematical symbols that aren’t represented in standard encodings.
- File Handling: When working with text files that include characters from various languages, using UTF-8 ensures accurate file operations.
- Data Processing: If you’re working with data that contains non-English characters, setting the code page to UTF-8 ensures correct handling and processing.
Potential Considerations
- Console Applications: Changing the code page might affect how some console applications behave. Always reset to the default code page (
chcp 437for English) when done using UTF-8. - Compatibility: Ensure that the programs or scripts you’re running in PowerShell can handle UTF-8 encoding. Older applications may not fully support it.
Practical Use Cases
- Reading Files: When reading text files with non-English characters, using UTF-8 ensures accurate representation.
- Web Scraping: If you’re extracting text from websites that may contain characters from various languages, UTF-8 ensures correct interpretation.
- Script Outputs: If your scripts generate outputs with non-English characters, using UTF-8 ensures they are displayed correctly.
- Interactive PowerShell Sessions: For interactive sessions where you need to input or output text with special characters, UTF-8 encoding is invaluable.
Conclusion
UTF-8 encoding (CHCP 65001) in PowerShell is a powerful tool for handling multilingual and special characters in the console. It allows for accurate representation and processing of text from various languages and scripts. Understanding when and how to use UTF-8 encoding ensures a seamless experience when working with diverse sets of characters.
Remember to consider the compatibility of programs or scripts with UTF-8 and always revert to the default code page when necessary. By harnessing the power of UTF-8 encoding, you’ll be equipped to handle a wide range of text data with confidence and accuracy in PowerShell.
Enjoying our tutorials? Subscribe to DelftStack on YouTube to support us in creating more high-quality video guides. Subscribe