
Command Line Shell For SQLite
Table Of Contents
1. Getting Started
The SQLite project provides a simple command-line program named
sqlite3 (or sqlite3.exe on Windows)
that allows the user to manually enter and execute SQL
statements against an SQLite database or against a
ZIP archive. This document provides a brief
introduction on how to use the sqlite3 program.
1.1. SQLite command-line program versus the SQLite library
The SQLite library is code that implements an SQL database engine.
The «sqlite3» command-line program or «CLI» is an application that
accepts user input and passes it down into the SQLite library for
evaluation. Understand that these are two different things. When
somebody says «SQLite» or «sqlite3» they might be referring to either
the SQLite library itself, or the CLI that provides a human interface
to the library. You will often need to use context to figure out exactly
which of these two things the speaker is referring to.
This document is about the CLI, not the underlying SQLite library.
1.2. Starting the CLI
Start the sqlite3 program by typing «sqlite3» at the
command prompt, optionally followed
by the name of the file that holds the SQLite database
(or ZIP archive). If the named
file does not exist, a new database file with the given name will be
created automatically. If no database file is specified on the
command-line, a temporary database is created and automatically deleted when
the «sqlite3» program exits.
On startup, the sqlite3 program will show a brief banner
message then prompt you to enter SQL. Type in SQL statements (terminated
by a semicolon), press «Enter» and the SQL will be executed.
For example, to create a new SQLite database named «ex1»
with a single table named «tbl1», you might do this:
$ sqlite3 ex1
SQLite version 3.36.0 2021-06-18 18:36:39
Enter ".help" for usage hints.
sqlite> create table tbl1(one text, two int);
sqlite> insert into tbl1 values('hello!',10);
sqlite> insert into tbl1 values('goodbye', 20);
sqlite> select * from tbl1;
hello!|10
goodbye|20
sqlite>
Terminate the sqlite3 program by typing your system
End-Of-File character (usually a Control-D). Use the interrupt
character (usually a Control-C) to stop a long-running SQL statement.
Make sure you type a semicolon at the end of each SQL command!
The sqlite3 program looks for a semicolon to know when your SQL command is
complete. If you omit the semicolon, sqlite3 will give you a
continuation prompt and wait for you to enter more text to
complete the SQL command. This feature allows you to
enter SQL commands that span multiple lines. For example:
sqlite> CREATE TABLE tbl2 ( ...> f1 varchar(30) primary key, ...> f2 text, ...> f3 real ...> ); sqlite>
1.3. Double-click Startup On Windows
Windows users can double-click on the sqlite3.exe icon to cause
the command-line shell to pop-up a terminal window running SQLite. However,
because double-clicking starts the sqlite3.exe without command-line arguments,
no database file will have been specified, so SQLite will use a temporary
database that is deleted when the session exits.
To use a persistent disk file as the database, enter the «.open» command
immediately after the terminal window starts up:
SQLite version 3.36.0 2021-06-18 18:36:39 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. sqlite> .open ex1.db sqlite>
The example above causes the database file named «ex1.db» to be opened
and used. The «ex1.db» file is created if it does not previously exist.
You might want to
use a full pathname to ensure that the file is in the directory that you
think it is in. Use forward-slashes as the directory separator character.
In other words use «c:/work/ex1.db», not «c:\work\ex1.db».
Alternatively, you can create a new database using the default temporary
storage, then save that database into a disk file using the «.save» command:
SQLite version 3.36.0 2021-06-18 18:36:39 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. sqlite> ... many SQL commands omitted ... sqlite> .save ex1.db sqlite>
Be careful when using the «.save» command as it will overwrite any
preexisting database files having the same name without prompting for
confirmation. As with the «.open» command, you might want to use a
full pathname with forward-slash directory separators to avoid ambiguity.
2. Special commands to sqlite3 (dot-commands)
Most of the time, sqlite3 just reads lines of input and passes them
on to the SQLite library for execution.
But input lines that begin with a dot («.»)
are intercepted and interpreted by the sqlite3 program itself.
These «dot commands» are typically used to change the output format
of queries, or to execute certain prepackaged query statements.
There were originally just a few dot commands, but over the years
many new features have accumulated so that today there are over 60.
For a listing of the available dot commands, you can enter «.help» with
no arguments. Or enter «.help TOPIC» for detailed information about TOPIC.
The list of available dot-commands follows:
sqlite> .help .archive ... Manage SQL archives .auth ON|OFF Show authorizer callbacks .backup ?DB? FILE Backup DB (default "main") to FILE .bail on|off Stop after hitting an error. Default OFF .cd DIRECTORY Change the working directory to DIRECTORY .changes on|off Show number of rows changed by SQL .check GLOB Fail if output since .testcase does not match .clone NEWDB Clone data into NEWDB from the existing database .connection [close] [#] Open or close an auxiliary database connection .crlf ?on|off? Whether or not to use \r\n line endings .databases List names and files of attached databases .dbconfig ?op? ?val? List or change sqlite3_db_config() options .dbinfo ?DB? Show status information about the database .dbtotxt Hex dump of the database file .dump ?OBJECTS? Render database content as SQL .echo on|off Turn command echo on or off .eqp on|off|full|... Enable or disable automatic EXPLAIN QUERY PLAN .excel Display the output of next command in spreadsheet .exit ?CODE? Exit this program with return-code CODE .expert EXPERIMENTAL. Suggest indexes for queries .explain ?on|off|auto? Change the EXPLAIN formatting mode. Default: auto .filectrl CMD ... Run various sqlite3_file_control() operations .fullschema ?--indent? Show schema and the content of sqlite_stat tables .headers on|off Turn display of headers on or off .help ?-all? ?PATTERN? Show help text for PATTERN .import FILE TABLE Import data from FILE into TABLE .indexes ?TABLE? Show names of indexes .intck ?STEPS_PER_UNLOCK? Run an incremental integrity check on the db .limit ?LIMIT? ?VAL? Display or change the value of an SQLITE_LIMIT .lint OPTIONS Report potential schema issues. .load FILE ?ENTRY? Load an extension library .log FILE|on|off Turn logging on or off. FILE can be stderr/stdout .mode MODE ?OPTIONS? Set output mode .nonce STRING Suspend safe mode for one command if nonce matches .nullvalue STRING Use STRING in place of NULL values .once ?OPTIONS? ?FILE? Output for the next SQL command only to FILE .open ?OPTIONS? ?FILE? Close existing database and reopen FILE .output ?FILE? Send output to FILE or stdout if FILE is omitted .parameter CMD ... Manage SQL parameter bindings .print STRING... Print literal STRING .progress N Invoke progress handler after every N opcodes .prompt MAIN CONTINUE Replace the standard prompts .quit Stop interpreting input stream, exit if primary. .read FILE Read input from FILE or command output .recover Recover as much data as possible from corrupt db. .restore ?DB? FILE Restore content of DB (default "main") from FILE .save ?OPTIONS? FILE Write database to FILE (an alias for .backup ...) .scanstats on|off|est Turn sqlite3_stmt_scanstatus() metrics on or off .schema ?PATTERN? Show the CREATE statements matching PATTERN .separator COL ?ROW? Change the column and row separators .session ?NAME? CMD ... Create or control sessions .sha3sum ... Compute a SHA3 hash of database content .shell CMD ARGS... Run CMD ARGS... in a system shell .show Show the current values for various settings .stats ?ARG? Show stats or turn stats on or off .system CMD ARGS... Run CMD ARGS... in a system shell .tables ?TABLE? List names of tables matching LIKE pattern TABLE .timeout MS Try opening locked tables for MS milliseconds .timer on|off Turn SQL timer on or off .trace ?OPTIONS? Output each SQL statement as it is run .unmodule NAME ... Unregister virtual table modules .version Show source, library and compiler versions .vfsinfo ?AUX? Information about the top-level VFS .vfslist List all available VFSes .vfsname ?AUX? Print the name of the VFS stack .width NUM1 NUM2 ... Set minimum column widths for columnar output .www Display output of the next command in web browser sqlite>
3. Rules for «dot-commands», SQL and More
3.1. Line Structure
The CLI’s input is parsed into a sequence consisting of:
- SQL statements;
- dot-commands; or
- CLI comments
SQL statements are free-form, and can be spread across multiple lines,
with whitespace or SQL comments embedded anywhere.
They are terminated by either a ‘;’ character at the end of an input line,
or a ‘/’ character or the word «go» on a line by itself.
When not at the end of an input line, the ‘;’ character
acts to separate SQL statements.
Trailing whitespace is ignored for purposes of termination.
A dot-command has a more restrictive structure:
- It must begin with its «.» at the left margin
with no preceding whitespace. - It must be entirely contained on a single input line.
- It cannot occur in the middle of an ordinary SQL
statement. In other words, it cannot occur at a
continuation prompt. - There is no comment syntax for dot-commands.
The CLI also accepts whole-line comments that
begin with a ‘#’ character and extend to the end of the line.
There can be no with whitespace prior to the ‘#’.
3.2. Dot-command arguments
The arguments passed to dot-commands are parsed from the command tail,
per these rules:
- The trailing newline and any other trailing whitespace is discarded;
- Whitespace immediately following the dot-command name, or any argument
input end bound is discarded; - An argument input begins with any non-whitespace character;
- An argument input ends with a character which
depends upon its leading character thusly: - for a leading single-quote (‘), a single-quote acts
as the end delimiter; - for a leading double-quote («), an unescaped double-quote
acts as the end delimiter; - for any other leading character, the end delimiter is
any whitespace; and - the command tail end acts as the end delimiter for any argument;
- Within a double-quoted argument input, a backslash-escaped double-quote
is part of the argument rather than its terminating quote; - Within a double-quoted argument, traditional C-string literal, backslash
escape sequence translation is done; and - Argument input delimiters (the bounding quotes or whitespace)
are discarded to yield the passed argument.
3.3. Dot-command execution
The dot-commands
are interpreted by the sqlite3.exe command-line program, not by
SQLite itself. So none of the dot-commands will work as an argument
to SQLite interfaces such as sqlite3_prepare() or sqlite3_exec().
4. Changing Output Formats
The sqlite3 program is able to show the results of a query
in 14 different output formats:
- ascii
- box
- csv
- column
- html
- insert
- json
- line
- list
- markdown
- quote
- table
- tabs
- tcl
You can use the «.mode» dot command to switch between these output
formats.
The default output mode is «list». In
list mode, each row of a query result is written on one line of
output and each column within that row is separated by a specific
separator string. The default separator is a pipe symbol («|»).
List mode is especially useful when you are going to send the output
of a query to another program (such as AWK) for additional processing.
sqlite> .mode list sqlite> select * from tbl1; hello!|10 goodbye|20 sqlite>
Type «.mode» with no arguments to show the current mode:
sqlite> .mode current output mode: list sqlite>
Use the «.separator» dot command to change the separator.
For example, to change the separator to a comma and
a space, you could do this:
sqlite> .separator ", " sqlite> select * from tbl1; hello!, 10 goodbye, 20 sqlite>
The next «.mode» command might reset the «.separator» back to some
default value (depending on its arguments).
So you will likely need to repeat the «.separator» command whenever you
change modes if you want to continue using a non-standard separator.
In «quote» mode, the output is formatted as SQL literals. Strings are
enclosed in single-quotes and internal single-quotes are escaped by doubling.
Blobs are displayed in hexadecimal blob literal notation (Ex: x’abcd’).
Numbers are displayed as ASCII text and NULL values are shown as «NULL».
All columns are separated from each other by a comma (or whatever alternative
character is selected using «.separator»).
sqlite> .mode quote sqlite> select * from tbl1; 'hello!',10 'goodbye',20 sqlite>
In «line» mode, each column in a row of the database
is shown on a line by itself. Each line consists of the column
name, an equal sign and the column data. Successive records are
separated by a blank line. Here is an example of line mode
output:
sqlite> .mode line sqlite> select * from tbl1; one = hello! two = 10 one = goodbye two = 20 sqlite>
In column mode, each record is shown on a separate line with the
data aligned in columns. For example:
sqlite> .mode column sqlite> select * from tbl1; one two -------- --- hello! 10 goodbye 20 sqlite>
In «column» mode (and also in «box», «table», and «markdown» modes)
the width of columns adjusts automatically. But you can override this,
providing a specified width for each column using the «.width» command.
The arguments to «.width» are integers which are the number of
characters to devote to each column. Negative numbers mean right-justify.
Thus:
sqlite> .width 12 -6 sqlite> select * from tbl1; one two ------------ ------ hello! 10 goodbye 20 sqlite>
A width of 0 means the column width is chosen automatically.
Unspecified column widths become zero. Hence, the command
«.width» with no arguments resets all column widths to zero and
hence causes all column widths to be determined automatically.
The «column» mode is a tabular output format. Other
tabular output formats are «box», «markdown», and «table»:
sqlite> .width sqlite> .mode markdown sqlite> select * from tbl1; | one | two | |---------|-----| | hello! | 10 | | goodbye | 20 | sqlite> .mode table sqlite> select * from tbl1; +---------+-----+ | one | two | +---------+-----+ | hello! | 10 | | goodbye | 20 | +---------+-----+ sqlite> .mode box sqlite> select * from tbl1; ┌─────────┬─────┐ │ one │ two │ ├─────────┼─────┤ │ hello! │ 10 │ │ goodbye │ 20 │ └─────────┴─────┘ sqlite>
The columnar modes accept some addition options to control formatting.
The «—wrap N» option (where N is an integer) causes columns
to wrap text that is longer than N characters. Wrapping is disabled if
N is zero.
sqlite> insert into tbl1 values('The quick fox jumps over a lazy brown dog.',90);
sqlite> .mode box --wrap 30
sqlite> select * from tbl1 where two>50;
┌────────────────────────────────┬─────┐
│ one │ two │
├────────────────────────────────┼─────┤
│ The quick fox jumps over a laz │ 90 │
│ y brown dog. │ │
└────────────────────────────────┴─────┘
sqlite>
Wrapping happens after exactly N characters,
which might be in the middle of a word.
To wrap at a word boundary, add the «—wordwrap on» option
(or just «-ww» for short):
sqlite> .mode box --wrap 30 -ww sqlite> select * from tbl1 where two>50; ┌─────────────────────────────┬─────┐ │ one │ two │ ├─────────────────────────────┼─────┤ │ The quick fox jumps over a │ 90 │ │ lazy brown dog. │ │ └─────────────────────────────┴─────┘ sqlite>
The «—quote» option causes the results in each column to be
quoted like an SQL literal, as in the «quote» mode. See the on-line
help for additional options.
The command «.mode box —wrap 60 —quote» is so useful for general-purpose
database queries that it is given its own alias. Instead of typing out
that whole 27-character command, you can just say «.mode qbox».
Another useful output mode is «insert». In insert mode, the output
is formatted to look like SQL INSERT statements. Use insert
mode to generate text that can later be used to input data into a
different database.
When specifying insert mode, you have to give an extra argument
which is the name of the table to be inserted into. For example:
sqlite> .mode insert new_table
sqlite> select * from tbl1 where two<50;
INSERT INTO "new_table" VALUES('hello',10);
INSERT INTO "new_table" VALUES('goodbye',20);
sqlite>
If .headers on is active, the INSERT output will
include that list of column names:
sqlite> .mode insert mytable sqlite> .headers on sqlite> select 1 a, 2 b, 3 c; INSERT INTO mytable(a,b,c) VALUES(1,2,3); sqlite>
Other output modes include «csv», «json», and «tcl». Try these
yourself to see what they do.
4.1. Control of line endings
The default line ending on Windows can be either «\r\n» (CRLF)
or «\n» NL. The line ending is controlled by the «.crlf» dot-command.
Use «.crlf on» to set the CRLF line ending and «.crlf off» for NL.
As is traditional for Windows, CRLF is the default. However, this
causes some outputs to be different than on non-Windows platforms due
to the added «\r» characters. To cause the CLI to output results on
Windows that are identical to the results on all other systems,
run «.crlf off».
On non-Windows platforms, the «.crlf» command is a no-op and the
crlf mode is always «off». For CSV output, the line ending is always
«\r\n» regardless of the .crlf setting, due to requirements of
RFC-4180.
5. Querying the database schema
The sqlite3 program provides several convenience commands that
are useful for looking at the schema of the database. There is
nothing that these commands do that cannot be done by some other
means. These commands are provided purely as a shortcut.
For example, to see a list of the tables in the database, you
can enter «.tables».
sqlite> .tables tbl1 tbl2 sqlite>
The «.tables» command is similar to setting list mode then
executing the following query:
SELECT name FROM sqlite_schema
WHERE type IN ('table','view') AND name NOT LIKE 'sqlite_%'
ORDER BY 1
But the «.tables» command does more. It queries the sqlite_schema table
for all attached databases, not just the primary database. And it arranges
its output into neat columns.
The «.indexes» command works in a similar way to list all of
the indexes. If the «.indexes» command is given an argument which is
the name of a table, then it shows just indexes on that table.
The «.schema» command shows the complete schema for the database,
or for a single table if an optional tablename argument is provided:
sqlite> .schema create table tbl1(one varchar(10), two smallint) CREATE TABLE tbl2 ( f1 varchar(30) primary key, f2 text, f3 real ); sqlite> .schema tbl2 CREATE TABLE tbl2 ( f1 varchar(30) primary key, f2 text, f3 real ); sqlite>
The «.schema» command is roughly the same as setting
list mode, then entering the following query:
SELECT sql FROM sqlite_schema ORDER BY tbl_name, type DESC, name
As with «.tables», the «.schema» command shows the schema for
all attached databases. If you only want to see the schema for
a single database (perhaps «main») then you can add an argument
to «.schema» to restrict its output:
The «.schema» command can be augmented with the «—indent» option,
in which case it tries to reformat the various CREATE statements of
the schema so that they are more easily readable by humans.
The «.databases» command shows a list of all databases open in
the current connection. There will always be at least 2. The first
one is «main», the original database opened. The second is «temp»,
the database used for temporary tables. There may be additional
databases listed for databases attached using the ATTACH statement.
The first output column is the name the database is attached with,
and the second result column is the filename of the external file.
There may be a third result column which will be either «‘r/o'» or
«‘r/w'» depending on whether the database file is read-only or read-write.
And there might be a fourth result column showing the result of
sqlite3_txn_state() for that database file.
The «.fullschema» dot-command works like the «.schema» command in
that it displays the entire database schema. But «.fullschema» also
includes dumps of the statistics tables «sqlite_stat1», «sqlite_stat3»,
and «sqlite_stat4», if they exist. The «.fullschema» command normally
provides all of the information needed to exactly recreate a query
plan for a specific query. When reporting suspected problems with
the SQLite query planner to the SQLite development team, developers
are requested to provide the complete «.fullschema» output as part
of the trouble report. Note that the sqlite_stat3 and sqlite_stat4
tables contain samples of index entries and so might contain sensitive
data, so do not send the «.fullschema» output of a proprietary database
over a public channel.
6. Opening Database Files
The «.open» command opens a new database connection, after first closing the
previously opened database command. In its simplest form, the «.open» command merely
invokes sqlite3_open() on the file named as its argument. Use the name «:memory:»
to open a new in-memory database that disappears when the CLI exits or when the
«.open» command is run again.
Or use no name to open a private, temporary on-disk database which
will also disappear upon exit or use of «.open».
If the —new option is included with «.open», then the database is reset prior
to being opened. Any prior data is destroyed. This is a destructive overwrite of
prior data and no confirmation is requested, so use this option carefully.
The —readonly option opens the database in read-only mode. Write will be
prohibited.
The —deserialize option causes the entire content of the on-disk file to be
read into memory and then opened as an in-memory database using the
sqlite3_deserialize() interface. This will, of course, require a lot of memory
if you have a large database. Also, any changes you make to the database will not
be saved back to disk unless you explicitly save them using the «.save» or «.backup»
commands.
The —append option causes the SQLite database to be appended to an existing
file rather than working as a stand-alone file. See the
appendvfs extension for
more information.
The —zip option causes the specified input file to be interpreted as a ZIP archive
instead of as an SQLite database file.
The —hexdb option causes the database content to be read from subsequent
lines of input in a hex format, rather than from a separate file on disk.
The «.dbtotxt» dot-command and/or the dbtotxt command-line tool can be used to generate
the appropriate text for a database. The —hexdb option is intended for use by the
SQLite developers for testing purposes. We do not know of any use cases for this
option outside of internal SQLite testing and development.
7. Redirecting I/O
7.1. Writing results to a file
By default, sqlite3 sends query results to standard output. You
can change this using the «.output» and «.once» commands. Just put
the name of an output file as an argument to .output and all subsequent
query results will be written to that file. Or use the .once command
instead of .output and output will only be redirected for the single next
command before reverting to the console. Use .output with no arguments to
begin writing to standard output again. For example:
sqlite> .mode list sqlite> .separator | sqlite> .output test_file_1.txt sqlite> select * from tbl1; sqlite> .exit $ cat test_file_1.txt hello|10 goodbye|20 $
If the first character of the «.output» or «.once» filename is a pipe
symbol («|») then the remaining characters are treated as a command and the
output is sent to that command. This makes it easy to pipe the results
of a query into some other process. For example, the
«open -f» command on a Mac opens a text editor to display the content that
it reads from standard input. So to see the results of a query
in a text editor, one could type:
sqlite> .once | open -f sqlite> SELECT * FROM bigTable;
If the «.output» or «.once» commands have an argument of «-e» then
output is collected into a temporary file and the system text editor is
invoked on that text file. Thus, the command «.once -e» achieves the
same result as «.once ‘|open -f'» but with the benefit of being portable
across all systems.
If the «.output» or «.once» commands have a «-x» argument, that causes
them to accumulate output as Comma-Separated-Values (CSV) in a temporary
file, then invoke the default system utility for viewing CSV files
(usually a spreadsheet program) on the result. This is a quick way of
sending the result of a query to a spreadsheet for easy viewing:
sqlite> .once -x sqlite> SELECT * FROM bigTable;
The «.excel» command is an alias for «.once -x». It does exactly the same
thing.
The «-w» option to «.output» or «.once» cause the output to be displayed
in your web-browser. The «.www» command is an alias for «.once -w». Normally
the data shown in the web-browser is in the form of an HTML table, but you
can instead show it as plain text by adding the «—plain» argument.
sqlite> .www sqlite> SELECT * FROM users WHERE email LIKE '%@aol.com';
7.2. Reading SQL from a file
In interactive mode, sqlite3 reads input text (either SQL statements
or dot-commands) from the keyboard. You can also redirect input from
a file when you launch sqlite3, of course, but then you do not have the
ability to interact with the program. Sometimes it is useful to run an
SQL script contained in a file entering other commands from the command-line.
For this, the «.read» dot-command is provided.
The «.read» command takes a single argument which is (usually) the name
of a file from which to read input text.
sqlite> .read myscript.sql
The «.read» command temporarily stops reading from the keyboard and instead
takes its input from the file named. Upon reaching the end of the file,
input reverts back to the keyboard. The script file may contain dot-commands,
just like ordinary interactive input.
If the argument to «.read» begins with the «|» character, then instead of
opening the argument as a file, it runs the argument (without the leading «|»)
as a command, then uses the output of that command as its input. Thus, if you
have a script that generates SQL, you can execute that SQL directly using
a command similar to the following:
sqlite> .read |myscript.bat
7.3. File I/O Functions
The command-line shell adds two application-defined SQL functions that
facilitate reading content from a file into a table column, and writing the
content of a column into a file, respectively.
The readfile(X) SQL function reads the entire content of the file named
X and returns that content as a BLOB. This can be used to load content into
a table. For example:
sqlite> CREATE TABLE images(name TEXT, type TEXT, img BLOB);
sqlite> INSERT INTO images(name,type,img)
...> VALUES('icon','jpeg',readfile('icon.jpg'));
The writefile(X,Y) SQL function write the blob Y into the file named X
and returns the number of bytes written. Use this function to extract
the content of a single table column into a file. For example:
sqlite> SELECT writefile('icon.jpg',img) FROM images WHERE name='icon';
Note that the readfile(X) and writefile(X,Y) functions are extension
functions and are not built into the core SQLite library. These routines
are available as a loadable extension in the
ext/misc/fileio.c
source file in the SQLite source code repositories.
7.4. The edit() SQL function
The CLI has another built-in SQL function named edit(). Edit() takes
one or two arguments. The first argument is a value — often a large
multi-line string to be edited. The second argument is the invocation
for a text editor. (It may include options to affect the editor’s
behavior.) If the second argument is omitted, the VISUAL environment
variable is used. The edit() function writes its first argument into a
temporary file, invokes the editor on the temporary file, rereads the file
back into memory after the editor is done, then returns the edited text.
The edit() function can be used to make changes to large text
values. For example:
sqlite> UPDATE docs SET body=edit(body) WHERE name='report-15';
In this example, the content of the docs.body field for the entry where
docs.name is «report-15» will be sent to the editor. After the editor returns,
the result will be written back into the docs.body field.
The default operation of edit() is to invoke a text editor. But by using
an alternative edit program in the second argument, you can also get it to edit
images or other non-text resources. For example, if you want to modify a JPEG
image that happens to be stored in a field of a table, you could run:
sqlite> UPDATE pics SET img=edit(img,'gimp') WHERE id='pic-1542';
The edit program can also be used as a viewer, by simply ignoring the
return value. For example, to merely look at the image above, you might run:
sqlite> SELECT length(edit(img,'gimp')) WHERE id='pic-1542';
7.5. Importing files as CSV or other formats
Use the «.import» command to import CSV (comma separated value)
or similarly delimited data into an SQLite table.
The «.import» command takes two arguments which are the
source from which data is to be read and the name of the
SQLite table into which the data is to be inserted. The source argument
is the name of a file to be read or, if it begins with a «|» character,
it specifies a command which will be run to produce the input data.
Note that it may be important to set the «mode» before running the
«.import» command. This is prudent to prevent the command-line shell
from trying to interpret the input file text as some format other than
how the file is structured. If the —csv or —ascii options are used,
they control import input delimiters. Otherwise, the delimiters are
those in effect for the current output mode.
To import into a table not in the «main» schema, the —schema option
may be used to specify that the table is in some other schema. This can
be useful for ATTACH’ed databases or to import into a TEMP table.
When .import is run, its treatment of the first input row depends
upon whether the target table already exists. If it does not exist,
the table is automatically created and the content of the first input
row is used to set the name of all the columns in the table. In this
case, the table data content is taken from the second and subsequent
input rows. If the target table already exists, every row of the
input, including the first, is taken to be actual data content. If
the input file contains an initial row of column labels, you can make
the .import command skip that initial row using the «—skip 1» option.
Here is an example usage, loading a pre-existing temporary table
from a CSV file which has column names in its first row:
sqlite> .import --csv --skip 1 --schema temp C:/work/somedata.csv tab1
While reading input data in modes other than ‘ascii’, «.import»
interprets input as records composed of fields according to the RFC 4180
specification with this exception: The input record and field separators
are as set by the mode or by use of the .separator command. Fields are
always subject to quote removal to reverse quoting done per RFC 4180,
except in ascii mode.
To import data with arbitrary delimiters and no quoting,
first set ascii mode («.mode ascii»), then set the field
and record delimiters using the «.separator» command. This
will suppress dequoting. Upon «.import», the data will be split
into fields and records according to the delimiters so specified.
7.6. Export to CSV
To export an SQLite table (or part of a table) as CSV, simply set
the «mode» to «csv» and then run a query to extract the desired rows
of the table. The output will formatted as CSV per RFC 4180.
sqlite> .headers on sqlite> .mode csv sqlite> .once c:/work/dataout.csv sqlite> SELECT * FROM tab1; sqlite> .system c:/work/dataout.csv
In the example above, the «.headers on» line causes column labels to
be printed as the first row of output. This means that the first row of
the resulting CSV file will contain column labels. If column labels are
not desired, set «.headers off» instead. (The «.headers off» setting is
the default and can be omitted if the headers have not been previously
turned on.)
The line «.once FILENAME» causes all query output to go into
the named file instead of being printed on the console. In the example
above, that line causes the CSV content to be written into a file named
«C:/work/dataout.csv».
The final line of the example (the «.system c:/work/dataout.csv»)
has the same effect as double-clicking on the c:/work/dataout.csv file
in windows. This will typically bring up a spreadsheet program to display
the CSV file.
That command only works as written on Windows.
The equivalent line on a Mac would be:
sqlite> .system open dataout.csv
On Linux and other unix systems you will need to enter something like:
sqlite> .system xdg-open dataout.csv
7.6.1. Export to Excel
To simplify export to a spreadsheet, the CLI provides the
«.excel» command which captures the output of a single query and sends
that output to the default spreadsheet program on the host computer.
Use it like this:
sqlite> .excel sqlite> SELECT * FROM tab;
The command above writes the output of the query as CSV into a temporary
file, invokes the default handler for CSV files (usually the preferred
spreadsheet program such as Excel or LibreOffice), then deletes the
temporary file. This is essentially a short-hand method of doing
the sequence of «.csv», «.once», and «.system» commands described above.
The «.excel» command is really an alias for «.once -x». The -x option
to .once causes it to writes results as CSV into a temporary file that
is named with a «.csv» suffix, then invoke the systems default handler
for CSV files.
There is also a «.once -e» command which works similarly, except that
it names the temporary file with a «.txt» suffix so that the default
text editor for the system will be invoked, instead of the default
spreadsheet.
7.6.2. Export to TSV (tab separated values)
Exporting to pure TSV, without any field quoting, can be done by
entering «.mode tabs» before running a query. However, the output
will not be read correctly in tabs mode by the «.import» command
if it contains doublequote characters. To get TSV quoted per
RFC 4180 so that it can be input in tabs mode with «.import»,
first enter «.mode csv», then enter ‘.separator «\t»‘
before running a query.
8. Accessing ZIP Archives As Database Files
In addition to reading and writing SQLite database files,
the sqlite3 program will also read and write ZIP archives.
Simply specify a ZIP archive filename in place of an SQLite database
filename on the initial command line, or in the «.open» command,
and sqlite3 will automatically detect that the file is a
ZIP archive instead of an SQLite database and will open it as such.
This works regardless of file suffix. So you can open JAR, DOCX,
and ODP files and any other file format that is really a ZIP
archive and SQLite will read it for you.
A ZIP archive appears to be a database containing a single table
with the following schema:
CREATE TABLE zip( name, // Name of the file mode, // Unix-style file permissions mtime, // Timestamp, seconds since 1970 sz, // File size after decompression rawdata, // Raw compressed file data data, // Uncompressed file content method // ZIP compression method code );
So, for example, if you wanted to see the compression efficiency
(expressed as the size of the compressed content relative to the
original uncompressed file size) for all files in the ZIP archive,
sorted from most compressed to least compressed, you could run a
query like this:
sqlite> SELECT name, (100.0*length(rawdata))/sz FROM zip ORDER BY 2;
Or using file I/O functions, you can extract elements of the
ZIP archive:
sqlite> SELECT writefile(name,content) FROM zip ...> WHERE name LIKE 'docProps/%';
8.1. How ZIP archive access is implemented
The command-line shell uses the Zipfile virtual table to
access ZIP archives. You can see this by running the «.schema»
command when a ZIP archive is open:
sqlite> .schema
CREATE VIRTUAL TABLE zip USING zipfile('document.docx')
/* zip(name,mode,mtime,sz,rawdata,data,method) */;
When opening a file, if the command-line client discovers that the
file is ZIP archive instead of an SQLite database, it actually opens
an in-memory database and then in that in-memory database it creates
an instance of the Zipfile virtual table that is attached to the
ZIP archive.
The special processing for opening ZIP archives is a trick of the
command-line shell, not the core SQLite library. So if you want to
open a ZIP archive as a database in your application, you will need to
activate the Zipfile virtual table module then run an appropriate
CREATE VIRTUAL TABLE statement.
9. Converting An Entire Database To A Text File
Use the «.dump» command to convert the entire contents of a
database into a single UTF-8 text file. This file can be converted
back into a database by piping it back into sqlite3.
A good way to make an archival copy of a database is this:
$ sqlite3 ex1 .dump | gzip -c >ex1.dump.gz
This generates a file named ex1.dump.gz that contains everything
you need to reconstruct the database at a later time, or on another
machine. To reconstruct the database, just type:
$ zcat ex1.dump.gz | sqlite3 ex2
The text format is pure SQL so you
can also use the .dump command to export an SQLite database
into other popular SQL database engines. Like this:
$ createdb ex2 $ sqlite3 ex1 .dump | psql ex2
10. Recover Data From a Corrupted Database
Like the «.dump» command, «.recover» attempts to convert the entire
contents of a database file to text. The difference is that instead of
reading data using the normal SQL database interface, «.recover»
attempts to reassemble the database based on data extracted directly from
as many database pages as possible. If the database is corrupt, «.recover»
is usually able to recover data from all uncorrupted parts of the database,
whereas «.dump» stops when the first sign of corruption is encountered.
If the «.recover» command recovers one or more rows that it cannot
attribute to any database table, the output script creates a «lost_and_found»
table to store the orphaned rows. The schema of the lost_and_found
table is as follows:
CREATE TABLE lost_and_found(
rootpgno INTEGER, -- root page of tree pgno is a part of
pgno INTEGER, -- page number row was found on
nfield INTEGER, -- number of fields in row
id INTEGER, -- value of rowid field, or NULL
c0, c1, c2, c3... -- columns for fields of row
);
The «lost_and_found» table contains one row for each orphaned row recovered
from the database. Additionally, there is one row for each recovered index
entry that cannot be attributed to any SQL index. This is because, in an
SQLite database, the same format is used to store SQL index entries and
WITHOUT ROWID table entries.
| Column | Contents |
|---|---|
| rootpgno | Even though it may not be possible to attribute the row to a specific database table, it may be part of a tree structure within the database file. In this case, the root page number of that tree structure is stored in this column. Or, if the page the row was found on is not part of a tree structure, this column stores a copy of the value in column «pgno» — the page number of the page the row was found on. In many, although not all, cases, all rows in the lost_and_found table with the same value in this column belong to the same table. |
| pgno | The page number of the page on which this row was found. |
| nfield | The number of fields in this row. |
| id | If the row comes from a WITHOUT ROWID table, this column contains NULL. Otherwise, it contains the 64-bit integer rowid value for the row. |
| c0, c1, c2… | The values for each column of the row are stored in these columns. The «.recover» command creates the lost_and_found table with as many columns as required by the longest orphaned row. |
If the recovered database schema already contains a table named
«lost_and_found», the «.recover» command uses the name «lost_and_found0». If
the name «lost_and_found0» is also already taken, «lost_and_found1», and so
on. The default name «lost_and_found» may be overridden by invoking «.recover»
with the —lost-and-found switch. For example, to have the output script call
the table «orphaned_rows»:
sqlite> .recover --lost-and-found orphaned_rows
11. Loading Extensions
You can add new custom application-defined SQL functions,
collating sequences, virtual tables, and VFSes to the command-line
shell at run-time using the «.load» command. First, build the
extension as a DLL or shared library (as described in the
Run-Time Loadable Extensions document) then type:
sqlite> .load /path/to/my_extension
Note that SQLite automatically adds the appropriate extension suffix
(«.dll» on windows, «.dylib» on Mac, «.so» on most other unixes) to the
extension filename. It is generally a good idea to specify the full
pathname of the extension.
SQLite computes the entry point for the extension based on the extension
filename. To override this choice, simply add the name of the extension
as a second argument to the «.load» command.
Source code for several useful extensions can be found in the
ext/misc
subdirectory of the SQLite source tree. You can use these extensions
as-is, or as a basis for creating your own custom extensions to address
your own particular needs.
12. Cryptographic Hashes Of Database Content
The «.sha3sum» dot-command computes a
SHA3 hash of the content
of the database. To be clear, the hash is computed over the database content,
not its representation on disk. This means, for example, that a VACUUM
or similar data-preserving transformation does not change the hash.
The «.sha3sum» command supports options «—sha3-224», «—sha3-256»,
«—sha3-384», and «—sha3-512» to define which variety of SHA3 to use
for the hash. The default is SHA3-256.
The database schema (in the sqlite_schema table) is not normally
included in the hash, but can be added by the «—schema» option.
The «.sha3sum» command takes a single optional argument which is a
LIKE pattern. If this option is present, only tables whose names match
the LIKE pattern will be hashed.
The «.sha3sum» command is implemented with the help of the
extension function «sha3_query()»
that is included with the command-line shell.
13. Database Content Self-Tests
The «.selftest» command attempts to verify that a database is
intact and is not corrupt.
The .selftest command looks for a table in schema named «selftest»
and defined as follows:
CREATE TABLE selftest( tno INTEGER PRIMARY KEY, -- Test number op TEXT, -- 'run' or 'memo' cmd TEXT, -- SQL command to run, or text of "memo" ans TEXT -- Expected result of the SQL command );
The .selftest command reads the rows of the selftest table in
selftest.tno order.
For each ‘memo’ row, it writes the text in ‘cmd’ to the output. For
each ‘run’ row, it runs the ‘cmd’ text as SQL and compares the result
to the value in ‘ans’, and shows an error message if the results differ.
If there is no selftest table, the «.selftest» command runs
PRAGMA integrity_check.
The «.selftest —init» command creates the selftest table if it
does not already exists, then appends entries that check the SHA3
hash of the content of all tables. Subsequent runs of «.selftest»
will verify that the database has not been changed in any way. To
generate tests to verify that a subset of the tables is unchanged,
simply run «.selftest —init» then DELETE the selftest rows that
refer to tables that are not constant.
14. SQLite Archive Support
The «.archive» dot-command and the «-A» command-line option
provide built-in support for the
SQLite Archive format. The interface is similar to
that of the «tar» command on unix systems. Each invocation of the «.ar»
command must specify a single command option. The following commands
are available for «.archive»:
| Option | Long Option | Purpose |
|---|---|---|
| -c | —create | Create a new archive containing specified files. |
| -x | —extract | Extract specified files from archive. |
| -i | —insert | Add files to existing archive. |
| -r | —remove | Remove files from the archive. |
| -t | —list | List the files in the archive. |
| -u | —update | Add files to existing archive if they have changed. |
As well as the command option, each invocation of «.ar» may specify
one or more modifier options. Some modifier options require an argument,
some do not. The following modifier options are available:
| Option | Long Option | Purpose |
|---|---|---|
| -v | —verbose | List each file as it is processed. |
| -f FILE | —file FILE | If specified, use file FILE as the archive. Otherwise, assume that the current «main» database is the archive to be operated on. |
| -a FILE | —append FILE | Like —file, use file FILE as the archive, but open the file using the apndvfs VFS so that the archive will be appended to the end of FILE if FILE already exists. |
| -C DIR | —directory DIR | If specified, interpret all relative paths as relative to DIR, instead of the current working directory. |
| -g | —glob | Use glob(Y,X) to match arguments against names in the archive. |
| -n | —dryrun | Show the SQL that would be run to carry out the archive operation, but do not actually change anything. |
| — | — | All subsequent command line words are command arguments, not options. |
For command-line usage, add the short style command-line options immediately
following the «-A», without an intervening space. All subsequent arguments
are considered to be part of the .archive command. For example, the following
commands are equivalent:
sqlite3 new_archive.db -Acv file1 file2 file3 sqlite3 new_archive.db ".ar -cv file1 file2 file3"
Long and short style options may be mixed. For example, the following are
equivalent:
-- Two ways to create a new archive named "new_archive.db" containing -- files "file1", "file2" and "file3". .ar -c --file new_archive.db file1 file2 file3 .ar -f new_archive.db --create file1 file2 file3
Alternatively, the first argument following to «.ar» may be the concatenation
of the short form of all required options (without the «-» characters). In
this case arguments for options requiring them are read from the command line
next, and any remaining words are considered command arguments. For example:
-- Create a new archive "new_archive.db" containing files "file1" and -- "file2" from directory "dir1". .ar cCf dir1 new_archive.db file1 file2 file3
14.1. SQLite Archive Create Command
Create a new archive, overwriting any existing archive (either in the current
«main» db or in the file specified by a —file option). Each argument following
the options is a file to add to the archive. Directories are imported
recursively. See above for examples.
14.2. SQLite Archive Extract Command
Extract files from the archive (either to the current working directory or
to the directory specified by a —directory option).
Files or directories whose names match the arguments,
as affected by the —glob option, are extracted.
Or, if no arguments follow the options, all files and directories are extracted.
Any specified directories are extracted recursively. It is an error if any
specified names or match patterns cannot be found in the archive.
-- Extract all files from the archive in the current "main" db to the -- current working directory. List files as they are extracted. .ar --extract --verbose -- Extract file "file1" from archive "ar.db" to directory "dir1". .ar fCx ar.db dir1 file1 -- Extract files with ".h" extension to directory "headers". .ar -gCx headers *.h
14.3. SQLite Archive List Command
List the contents of the archive. If no arguments are specified, then all
files are listed. Otherwise, only those which match the arguments,
as affected by the —glob option, are listed. Currently,
the —verbose option does not change the behaviour of this command. That may
change in the future.
-- List contents of archive in current "main" db.. .ar --list
14.4. SQLite Archive Insert And Update Commands
The —update and —insert commands work like —create command, except that
they do not delete the current archive before commencing. New versions of
files silently replace existing files with the same names, but otherwise
the initial contents of the archive (if any) remain intact.
For the —insert command, all files listed are inserted into the archive.
For the —update command, files are only inserted if they do not previously
exist in the archive, or if their «mtime» or «mode» is different from what
is currently in the archive.
Compatibility node: Prior to SQLite version 3.28.0 (2019-04-16) only
the —update option was supported but that option worked like —insert in that
it always reinserted every file regardless of whether or not it had changed.
14.5. SQLite Archive Remove Command
The —remove command deletes files and directories which match the
provided arguments (if any) as affected by the —glob option.
It is an error to provide arguments which match nothing in the archive.
14.6. Operations On ZIP Archives
If FILE is a ZIP archive rather than an SQLite Archive, the «.archive»
command and the «-A» command-line option still work. This is accomplished
using of the zipfile extension.
Hence, the following commands are roughly equivalent,
differing only in output formatting:
| Traditional Command | Equivalent sqlite3.exe Command |
|---|---|
| unzip archive.zip | sqlite3 -Axf archive.zip |
| unzip -l archive.zip | sqlite3 -Atvf archive.zip |
| zip -r archive2.zip dir | sqlite3 -Acf archive2.zip dir |
14.7. SQL Used To Implement SQLite Archive Operations
The various SQLite Archive Archive commands are implemented using SQL statements.
Application developers can easily add SQLite Archive Archive reading and writing
support to their own projects by running the appropriate SQL.
To see what SQL statements are used to implement an SQLite Archive
operation, add the —dryrun or -n option. This causes the SQL to be
displayed but inhibits the execution of the SQL.
The SQL statements used to implement SQLite Archive operations make use of
various loadable extensions. These extensions are all available in
the SQLite source tree in the
ext/misc/ subfolder.
The extensions needed for full SQLite Archive support include:
-
fileio.c —
This extension adds SQL functions readfile() and writefile() for
reading and writing content from files on disk. The fileio.c
extension also includes fsdir() table-valued function for listing
the contents of a directory and the lsmode() function for converting
numeric st_mode integers from the stat() system call into human-readable
strings after the fashion of the «ls -l» command. -
sqlar.c —
This extension adds the sqlar_compress() and sqlar_uncompress()
functions that are needed to compress and uncompress file content
as it is inserted and extracted from an SQLite Archive. -
zipfile.c —
This extension implements the «zipfile(FILE)» table-valued function
which is used to read ZIP archives. This extension is only needed
when reading ZIP archives instead of SQLite archives. -
appendvfs.c —
This extension implements a new VFS that allows an SQLite database
to be appended to some other file, such as an executable. This
extension is only needed if the —append option to the .archive
command is used.
15. SQL Parameters
SQLite allows bound parameters to appear in an SQL statement anywhere
that a literal value is allowed. The values for these parameters are set
using the sqlite3_bind_…() family of APIs.
Parameters can be either named or unnamed. An unnamed parameter is a single
question mark («?»). Named parameters are a «?» followed immediately by a number
(ex: «?15» or «?123») or one of the characters «$», «:», or «@» followed by an
alphanumeric name (ex: «$var1», «:xyz», «@bingo»).
This command-line shell leaves unnamed parameters unbound, meaning that they
will have a value of an SQL NULL, but named parameters might be assigned values.
If there exists a TEMP table named «sqlite_parameters» with a schema like this:
CREATE TEMP TABLE sqlite_parameters( key TEXT PRIMARY KEY, value ) WITHOUT ROWID;
And if there is an entry in that table where the key column exactly matches
the name of parameter (including the initial «?», «$», «:», or «@» character)
then the parameter is assigned the value of the value column. If no entry exists,
the parameter defaults to NULL.
The «.parameter» command exists to simplify managing this table. The
«.parameter init» command (often abbreviated as just «.param init») creates
the temp.sqlite_parameters table if it does not already exist. The «.param list»
command shows all entries in the temp.sqlite_parameters table. The «.param clear»
command drops the temp.sqlite_parameters table. The «.param set KEY VALUE» and
«.param unset KEY» commands create or delete entries from the
temp.sqlite_parameters table.
The VALUE passed to «.param set KEY VALUE» can be either a SQL literal
or any other SQL expression or query which can be evaluated to yield a value.
This allows values of differing types to be set.
If such evaluation fails, the provided VALUE is instead quoted and inserted
as text.
Because such initial evaluation may or may not fail depending upon
the VALUE content, the reliable way to get a text value is to enclose it
with single-quotes protected from the above-described command-tail parsing.
For example, (unless one intends a value of -1365):
.parameter init .parameter set @phoneNumber "'202-456-1111'"
Note that the double-quotes serve to protect the single-quotes
and ensure that the quoted text is parsed as one argument.
The temp.sqlite_parameters table only provides values for parameters in the
command-line shell. The temp.sqlite_parameter table has no effect on queries
that are run directly using the SQLite C-language API. Individual applications
are expected to implement their own parameter binding. You can search for
«sqlite_parameters» in the
command-line shell source code
to see how the command-line shell does parameter binding, and use that as
a hint for how to implement it yourself.
16. Index Recommendations (SQLite Expert)
Note: This command is experimental. It may be removed or the
interface modified in incompatible ways at some point in the future.
For most non-trivial SQL databases, the key to performance is creating
the right SQL indexes. In this context «the right SQL indexes» means those
that cause the queries that an application needs to optimize run fast. The
«.expert» command can assist with this by proposing indexes that might
assist with specific queries, were they present in the database.
The «.expert» command is issued first, followed by the SQL query
on a separate line. For example, consider the following session:
sqlite> CREATE TABLE x1(a, b, c); -- Create table in database sqlite> .expert sqlite> SELECT * FROM x1 WHERE a=? AND b>?; -- Analyze this SELECT CREATE INDEX x1_idx_000123a7 ON x1(a, b); 0|0|0|SEARCH TABLE x1 USING INDEX x1_idx_000123a7 (a=? AND b>?) sqlite> CREATE INDEX x1ab ON x1(a, b); -- Create the recommended index sqlite> .expert sqlite> SELECT * FROM x1 WHERE a=? AND b>?; -- Re-analyze the same SELECT (no new indexes) 0|0|0|SEARCH TABLE x1 USING INDEX x1ab (a=? AND b>?)
In the above, the user creates the database schema (a single table — «x1»),
and then uses the «.expert» command to analyze a query, in this case
«SELECT * FROM x1 WHERE a=? AND b>?». The shell tool recommends that the
user create a new index (index «x1_idx_000123a7») and outputs the plan
that the query would use in EXPLAIN QUERY PLAN format. The user then creates
an index with an equivalent schema and runs the analysis on the same query
again. This time the shell tool does not recommend any new indexes, and
outputs the plan that SQLite will use for the query given the existing
indexes.
The «.expert» command accepts the following options:
| Option | Purpose |
|---|---|
| ‑‑verbose | If present, output a more verbose report for each query analyzed. |
| ‑‑sample PERCENT | This parameter defaults to 0, causing the «.expert» command to recommend indexes based on the query and database schema alone. This is similar to the way the SQLite query planner selects indexes for queries if the user has not run the ANALYZE command on the database to generate data distribution statistics.
If this option is passed a non-zero argument, the «.expert» command
For small databases and modern CPUs, there is usually no reason not |
The functionality described in this section may be integrated into other
applications or tools using the
SQLite expert extension code.
A database schema which incorporate SQL custom functions made available
via the extension load mechanism may need special provision to work with
the .expert feature. Because the feature uses additional connections to
implement its functionality, those custom functions must be made available
to those additional connections. This can be done by means of the extension
load/usage options described at
Automatically Load Statically Linked Extensions
and
Persistent Loadable Extensions.
17. Working With Multiple Database Connections
Beginning with version 3.37.0 (2021-11-27), the CLI has the ability to
hold multiple database connections open at once. Only one database connection
is active at a time. The inactive connections are still open but are idle.
Use the «.connection» dot-command (often abbreviated as just «.conn») to see a
list of database connections and an indication of which one is currently active.
Each database connection is identified by an integer between 0 and 9. (There
can be at most 10 simultaneously open connections.) Change to another database
connection, creating it if it does not already exist, by typing the «.conn»
command followed by its number. Close a database connection by typing
«.conn close N» where N is the connection number.
Though the underlying SQLite database connections are completely independent
of one another, many of the CLI settings, such as the output format, are
shared across all database connections. Thus, changing the output mode in
one connection will change it in them all. On the other hand, some
dot-commands such as .open only affect the current connection.
18. Miscellaneous Extension Features
The CLI is built with several SQLite extensions that are not
included with the SQLite library. A few add features
not described in the preceding sections, namely:
- the UINT collating sequence which treats
unsigned integers embedded in text according to
their value, along with other text, for ordering; - decimal arithmetic as provided by the decimal extension;
- the generate_series() table-valued function;
- the base64() and base85() functions which encode a
blob to base64 or base85 text or decode the same to a blob; and - support for POSIX extended regular expressions
bound to the REGEXP operator.
19. Other Dot Commands
There are many other dot-commands available in the command-line
shell. See the «.help» command for a complete list for any particular
version and build of SQLite.
20. Using sqlite3 in a shell script
One way to use sqlite3 in a shell script is to use «echo» or
«cat» to generate a sequence of commands in a file, then invoke sqlite3
while redirecting input from the generated command file. This
works fine and is appropriate in many circumstances. But as
an added convenience, sqlite3 allows a single SQL command to be
entered on the command line as a second argument after the
database name. When the sqlite3 program is launched with two
arguments, the second argument is passed to the SQLite library
for processing, the query results are printed on standard output
in list mode, and the program exits. This mechanism is designed
to make sqlite3 easy to use in conjunction with programs like
«awk». For example:
$ sqlite3 ex1 'select * from tbl1' \
> | awk '{printf "<tr><td>%s<td>%s\n",$1,$2 }'
<tr><td>hello<td>10
<tr><td>goodbye<td>20
$
21. Marking The End Of An SQL Statement
SQLite commands are normally terminated by a semicolon. In the CLI
you can also use the word «GO» (case-insensitive) or a slash character
«/» on a line by itself to end a command. These are used by SQL Server
and Oracle, respectively, and are supported by the SQLite CLI for
compatibility. These won’t work in sqlite3_exec(),
because the CLI translates these inputs into a semicolon before passing
them down into the SQLite core.
22. More Details On How To Start The CLI
As stated previously, the usual way to start
up the CLI is to type «sqlite3» followed by the name of the database file.
But the «sqlite3» program accepts many other arguments other than just
the database filename.
22.1. Extra command-line arguments
Additional command-line arguments that occur after the database filename
are treated as if they were lines of input text. Each additional argument
can be either an SQL statement or a dot-command. They are evaluated in
order from left to right.
Since both SQLite statements and dot-commands often contain spaces, you will
probably need to put each SQL statement or dot-command inside
single- or double-quotes (depending on your OS). For example:
$ sqlite3 test.db ".mode box" "SELECT * FROM users;"
When extra arguments are provided this way, standard input is not read
and the CLI exits after it has processed all the extra arguments.
22.2. Command-line Options
Extra arguments that start with the «-» character are command-line options.
There are many command-line options available. Use the —help
command-line option to see a list:
$ sqlite3 --help FILENAME is the name of an SQLite database. A new database is created if the file does not previously exist. Defaults to :memory:. OPTIONS include: -- treat no subsequent arguments as options -A ARGS... run ".archive ARGS" and exit -append append the database to the end of the file -ascii set output mode to 'ascii' -bail stop after hitting an error -batch force batch I/O -box set output mode to 'box' -column set output mode to 'column' -cmd COMMAND run "COMMAND" before reading stdin -csv set output mode to 'csv' -deserialize open the database using sqlite3_deserialize() -echo print inputs before execution -init FILENAME read/process named file -[no]header turn headers on or off -heap SIZE Size of heap for memsys3 or memsys5 -help show this message -html set output mode to HTML -interactive force interactive I/O -json set output mode to 'json' -line set output mode to 'line' -list set output mode to 'list' -lookaside SIZE N use N entries of SZ bytes for lookaside memory -markdown set output mode to 'markdown' -maxsize N maximum size for a --deserialize database -memtrace trace all memory allocations and deallocations -mmap N default mmap size set to N -newline SEP set output row separator. Default: '\n' -nofollow refuse to open symbolic links to database files -nonce STRING set the safe-mode escape nonce -no-rowid-in-view Disable rowid-in-view using sqlite3_config() -nullvalue TEXT set text string for NULL values. Default '' -pagecache SIZE N use N slots of SZ bytes each for page cache memory -pcachetrace trace all page cache operations -quote set output mode to 'quote' -readonly open the database read-only -safe enable safe-mode -separator SEP set output column separator. Default: '|' -stats print memory stats before each finalize -table set output mode to 'table' -tabs set output mode to 'tabs' -unsafe-testing allow unsafe commands and modes for testing -version show SQLite version -vfs NAME use NAME as the default VFS -vfstrace enable tracing of all VFS calls -zip open the file as a ZIP Archive
The CLI is flexible regarding command-line option formatting.
Either one or two leading «-» characters are permitted.
Thus «-box» and «—box» mean the same thing.
Command-line options are processed from left to right.
Hence a «—box» option will override a prior «—quote» option.
Most of the command-line options are self-explanatory, but a few merit additional
discussion below.
22.3. The —safe command-line option
The —safe command-line option attempts to disable all features of the CLI that
might cause any changes to the host computer other than changes to the specific database
file named on the command-line. The idea is that if you receive a large SQL script
from an unknown or untrusted source, you can run that script to see what it does without
risking an exploit by using the —safe option. The —safe option disables (among other
things):
- The .open command, unless the —hexdb option is used or the filename is «:memory:».
This prevents the script from reading or writing any database files not named on
the original command-line. - The ATTACH SQL command.
- SQL functions that have potentially harmful side-effects, such as
edit(), fts3_tokenizer(), load_extension(), readfile() and writefile(). - The .archive command.
- The .backup and .save commands.
- The .import command.
- The .load command.
- The .log command.
- The .shell and .system commands.
- The .excel, .once and .output commands.
- Other commands that can have deleterious side effects.
Basically, any feature of the CLI that reads or writes from a file on disk other
than the main database file is disabled.
22.3.1. Bypassing —safe restrictions for specific commands
If the «—nonce NONCE» option is also included on the command-line, for some
large and arbitrary NONCE string, then the «.nonce NONCE» command (with the
same large nonce string) will permit the next SQL statement or dot-command
to bypass the —safe restrictions.
Suppose you want to run a suspicious script and the script requires one or
two of the features that —safe normally disables. For example, suppose it
needs to ATTACH one additional database. Or suppose the script needs to load
a specific extension. This can be accomplished by preceding the (carefully
audited) ATTACH statement or the «.load» command with an appropriate «.nonce»
command and supplying the same nonce value using the «—nonce» command-line
option. Those specific commands will then be allowed to execute normally,
but all other unsafe commands will still be restricted.
The use of «.nonce» is dangerous in the sense that a mistake can allow a
hostile script to damage your system. Therefore, use «.nonce» carefully,
sparingly, and as a last resort when there are no other ways to get a
script to run under —safe mode.
22.4. The —unsafe-testing command-line option
The —unsafe-testing command-line option enables features of the CLI
that are intended for internal testing only. The —unsafe-testing option
disables defenses that are built into SQLite. Examples of
that are disabled defenses include SQLITE_DBCONFIG_DEFENSIVE and
SQLITE_DBCONFIG_TRUSTED_SCHEMA.
The —unsafe-testing option also enables features that, if misused, might
cause database corruption, memory errors, or
similar problems in the CLI itself or in the SQLite library.
Example of features that —unsafe-testing enables include
the .imposter dot-command and SQLITE_TESTCTRL_ASSERT.
Misbehavior which requires use of the —unsafe-testing option
will generally not be considered a bug.
22.5. The —no-utf8 and —utf8 command-line options
On the Windows platform, when the console is used for input or output,
translation is required between character encoding available from or sent to
the console and the CLI’s internal, UTF-8 text representation. Past versions
of the CLI accepted these options to enable or disable use of a translation
that relied upon a Windows console feature whereby it could be made to
produce or accept UTF-8 on modern versions of the OS.
Present CLI versions (3.44.1 or later) do console I/O by reading or writing
UTF-16 from/to the Windows console APIs. Because this operates correctly even
on Windows versions going back to Window 2000, there is no longer any need
for these options. They are still accepted, but without effect.
In all cases, non-console text I/O is UTF-8 encoded.
On non-Windows platforms, these options are also ignored.
23. Compiling the sqlite3 program from sources
To compile the command-line shell on unix systems and on Windows with MinGW,
the usual configure-make command works:
The configure-make works whether you are building from the canonical sources
from the source tree, or from an amalgamated bundle. There are few
dependencies. When building from canonical sources, a working
tclsh is required.
If using an amalgamation bundle, all the preprocessing work normally
done by tclsh will have already been carried out and only normal build
tools are required.
A working zlib compression library is
needed in order for the .archive command to operate.
On Windows with MSVC, use nmake with the Makefile.msc:
For correct operation of the .archive command, make a copy of the
zlib source code into the compat/zlib subdirectory
of the source tree and compile this way:
nmake /f Makefile.msc USE_ZLIB=1
23.1. Do-It-Yourself Builds
The source code to the sqlite3 command line interface is in a single
file named «shell.c». The shell.c source file is generated from other
sources, but most of the code for shell.c can be found in
src/shell.c.in.
(Regenerate shell.c by typing «make shell.c» from the canonical source tree.)
Compile the shell.c file (together
with the sqlite3 library source code) to generate
the executable. For example:
gcc -o sqlite3 shell.c sqlite3.c -ldl -lpthread -lz -lm
The following additional compile-time options are recommended in order to
provide a full-featured command-line shell:
- -DSQLITE_THREADSAFE=0
- -DSQLITE_ENABLE_EXPLAIN_COMMENTS
- -DSQLITE_HAVE_ZLIB
- -DSQLITE_INTROSPECTION_PRAGMAS
- -DSQLITE_ENABLE_UNKNOWN_SQL_FUNCTION
- -DSQLITE_ENABLE_STMTVTAB
- -DSQLITE_ENABLE_DBPAGE_VTAB
- -DSQLITE_ENABLE_DBSTAT_VTAB
- -DSQLITE_ENABLE_OFFSET_SQL_FUNC
- -DSQLITE_ENABLE_JSON1
- -DSQLITE_ENABLE_RTREE
- -DSQLITE_ENABLE_FTS4
- -DSQLITE_ENABLE_FTS5
This page last modified on 2025-04-16 13:13:29 UTC
About SQLite
SQLite is a software library that provides a relational database
management system. The lite in SQLite means lightweight in terms of
setup, database administration, and required resources.
SQLite has the following noticeable features: self-contained,
serverless, zero-configuration, transactional.
For more information, see What is SQLite
Why SQLite?
For one obvious reason – all the riskassessment App data
is stored in a SQLite database. Also, one of SQLite’s advantages is that
it can run nearly anywhere. This vignette will provide you with the
means of accessing the database outside of the
riskassessment App.
Download SQLite tools
Open the download page SQLite Download Page
To work with SQLite on Windows, you download the command-line
shell program as shown in the screenshot below.
If you are using a Mac, you need to download this one:
In
either case, the downloaded file is in ZIP format and its size is quite
small.
Run SQLite tools
Installing SQLite is simple and straightforward.
Create a new folder e.g., C:\sqlite.
Extract the content of the .zip file that you downloaded in the
previous section to the C:\sqlite folder. You should see
three programs as shown below:
Open the command line window.
On Windows, type “cmd” in the search bar.
Navigate to the C:\sqlite folder.
C:\cd c:\sqlite
C:\sqlite>Next, type sqlite3 and press enter, you should see the
following output:
C:\sqlite>sqlite3
SQLite version 3.33.0 2020-08-14 13:23:32
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>Navigate to the directory containing the riskassessment
database. Note: the app’s default behavior is to call this database
“database.sqlite”, unless you’ve specified otherwise using the
assessment_db_name arg in run_app(). Next, use
the .open FILENAME command to open it. For example:
.open database.sqlite;
To show the tables, type .tables
sqlite> .tables
comments metric package_metrics
community_usage_metrics package
sqlite>To show the structure of a table, type .schema TABLE
sqlite> .schema package_metrics
CREATE TABLE package_metrics ( id INTEGER PRIMARY KEY AUTOINCREMENT, package_id INT, metric_id INT, value CHAR, /* value == 'pkg_metric_error' indicates an error. */ /* value == NA indicates metric is not applicable for this package. */ weight REAL, FOREIGN KEY (package_id) REFERENCES package(id), FOREIGN KEY (metric_id) REFERENCES metric(id));
sqlite>You can also type .help from the sqlite> prompt to
see all available commands.
sqlite> .help
.archive ... Manage SQL archives
.auth ON|OFF Show authorizer callbacks
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail on|off Stop after hitting an error. Default OFF
.binary on|off Turn binary output on or off. Default OFF
.cd DIRECTORY Change the working directory to DIRECTORY
.changes on|off Show number of rows changed by SQL
.check GLOB Fail if output since .testcase does not match
.clone NEWDB Clone data into NEWDB from the existing database
.databases List names and files of attached databases
.dbconfig ?op? ?val? List or change sqlite3_db_config() options
.dbinfo ?DB? Show status information about the database
.dump ?TABLE? Render database content as SQL
.echo on|off Turn command echo on or off
.eqp on|off|full|... Enable or disable automatic EXPLAIN QUERY PLAN
.excel Display the output of next command in spreadsheet
...
additional output not displayedTo exit, type .quitor .exit
Command Line Shell
You can also temporarily add C:\sqlite to the
Windows path.
set PATH=%PATH%;C:\sqlite
Verify by typing
echo %PATH%
Then when you are in the riskassessment directory, you
can just enter the following on the command line:
sqlite3 database.sqlite and then you will see
SQLite version 3.33.0 2020-08-14 13:23:32
Enter ".help" for usage hints.
sqlite> You can also use the system2 command to execute SQLite
commands on the RStudio command line.
> system2("C:/sqlite/sqlite3", args =c("database.sqlite", ".tables", ".quit"))
comments metric package_metrics
community_usage_metrics package And you can build queries or commands for SQLite and execute
them.
> table_name <- "package"
> query <- glue::glue("select * from { table_name } limit 1;")
> frst_row <- system2("C:/sqlite/sqlite3", args ="database.sqlite", input = query, stdout = TRUE)
>
> frst_row
[1] "1|glue|1.6.2|glue: Interpreted String Literals|An implementation of interpreted string literals, inspired by Pythons Literal String Interpolation <https://www.python.org/dev/peps/pep-0498/> and Docstrings <https://www.python.org/dev/peps/pep-0257/> and Julias Triple-Quoted String Literals <https://docs.julialang.org/en/v1.3/manual/strings/#Triple-Quoted-String-Literals-1>.|Jennifer Bryan <jenny at rstudio.com>|Jim Hester [aut], Jennifer Bryan [aut, cre], RStudio [cph, fnd]|MIT + file LICENSE|2022-02-24|0.11|||2022-02-24"For more info, see Command Line
Shell for SQLite
SQLiteStudio
The SQLiteStudio tool is a free GUI tool for managing SQLite
databases. It is free, portable, intuitive, and cross-platform. SQLite
tool also provides some of the most important features to work with
SQLite databases such as importing, exporting data in various formats
including CSV, XML, and JSON.
Visit SQLite Studio
You can download the SQLiteStudio installer or its portable version
by visiting the download page. Then, you can extract (or install) the
download file to a folder e.g., C: and launch it.
The following picture illustrates how to launch the SQLiteStudio:
Introduction
SQLite3 (https://www.sqlite.org) is an ubiquitous
relational database written in C.
The main thing that stands out about SQLite versus other databases is the fact
that the whole database is contained in a single file with no server or configuration
needed making it very easy to set up and use.
It is licensed as public domain which is even more free than typical open
source libraries like MIT or GPL.
It uses a mostly SQL compliant language so if you are familiar with any other
standard SQL engine the language should be something you are familiar with.
SQLite has proven to be stable in production environments,
but is often used for development environments due to its ease of use.
There are language bindings to Sqlite written in almost every language.
Reads can be done concurrently but there is a database-wide lock for write
events.
For that reason, it does not perform well for write-heavy applications.
A database that provides row-level locking would be more efficient for
performing lots of concurrent writes.
The official website has more information on when it is a good choice
to use.
For a more exhaustive list of features, check out the official page,
Distinctive Features Of SQLite.
For an example of using SQLite with a programming language,
check out my Ruby SQLite Tutorial.
- All SQLite tutorials of mine at https://www.devdungeon.com/tags/sqlite
- Compiling SQLite3 with C++
- Ruby SQLite Tutorial
- Ruby ActiveRecord (without Rails) Tutorial
- PHP SQLite Tutorial
Install SQLite
To install SQLite, you have a few options depending on what kind of system
you have. Some options include: building from source, downloading pre-built
binaries, or installing using your system’s package manager.
From Source
One option for all systems is to build from source.
To build with gcc, download the source code from https://www.sqlite.org/download.html and then extract the source.
If you download the amalgamation version, it only comes with two .c files.
You can build it as simple as:
gcc shell.c sqlite3.c -o sqlite3
./sqlite3 --help
# You can place the sqlite3 file anywhere you want
# Update your PATH environment variable if you want to run it from anywhere
If you download the autoconf version, you will also need make and autoconf tools.
To build the autoconf version, run:
./configure
make
./sqlite3 --help
# Optional step to install: `make install`
make install
To learn how to compile SQLite3 in to a C++ application, check out my tutorial Compiling SQLite3 with C++.
Windows
In Windows, the easiest thing to do is download the pre-built binaries from https://www.sqlite.org/download.html and extract them.
The executable will be ready to use, but if you want to use it from the command line anywhere, you will need
to update your PATH environment variable to include the directory that contains the SQLite executable/DLL.
Mac
The easiest way to install SQLite3 on a Mac is to use use https://brew.sh/.
brew install sqlite
Ubuntu
In Ubuntu, you can use apt to install the necessary packages.
The main package is sqlite3 but you can optionally also install the
development headers and the documentation as well.
sudo apt install sqlite3
sudo apt install libsqlite3-dev
sudo apt install sqlite3-doc
Fedora
In Fedora, you can use dnf to install the packages.
The main package in Fedora is sqlite but you can optionally also install the
development headers and the documentation as well.
sudo dnf install sqlite
sudo dnf install sqlite-devel
sudo dnf install sqlite-doc
Read documentation
There are a few places to get help. If you have an internet connection you
can read the online documentation, but if you are offline you will need
to find offline documentation. You have a few options for getting help
including:
- Read online at https://www.sqlite.org/docs.html
- Download the HTML documentation from https://www.sqlite.org/download.html
- From the command line with
sqlite3 --help - From the man page with
man sqlite3 - In the command line shell with
.help - From your system’s SQLite doc package (e.g.
/usr/share/doc/sqlite-doc/in Fedora fromsqlite-docpackage)
Command line shell
One of the primary interfaces to a SQLite database is through the command line
shell sqlite3. Launch the shell with no arguments, or pass it the name of
the database file you want to use. By default, if no database name is provided
it uses an in-memory database.
sqlite3
# or
sqlite3 my.db
Once in the command line shell, you can open databse files, inspect schemas,
query, and execute statements.
List all commands
You can get a list of all available commands with the .help command.
.help
Open a file
To open a database use the .open command. For example, to open a database
file named my.db you would run:
.open my.db
Identify current database
To see which database is currently being used, you can use the .database
command. This will output the full path to the database file being used,
unless you are using the in-memory database then it will only output main.
.database
List database tables
To see information about the tables in a database, you can use the .tables
command. This will list the names of tables in the database.
.tables
You could also query the special sqlite_master table for a list of tables
that exist:
SELECT name FROM sqlite_master;
If you want to see the details about a table, like what columns it has,
you can use the .schema command. Using .schema by itself will describe all
the tables.
You can also specify a table name as an argument. For example:
.schema
-- Or a specific table
.schema sqlite_master
Exit shell
To quit the interactive command line shell, call .exit.
.exit
Execute directly from command line
Instead of using the interactive command line shell, you can execute
a query directly and get the results in STDOUT. This is useful if you want
to output the data to a file or you want to the pipe the output to another
program.
sqlite3 test.db "select * from sqlite_master"
Backing up and restoring databases
Since databases are fully contained in a single file, creating a backup
is as simple as creating a copy of the file. Restoring a database is also
as simple as renaming or replacing the database file.
There is however one command available that is useful inside the sqlite shell:
This .backup command is like a «Save as…» feature when run in sqlite3.
It will store the current database to a file named myfile.db.
.backup myfile.db
SQL dialect
SQLite supports most standard SQL but not everything. For a full list
of the keywords and syntax it supports, refer to
https://www.sqlite.org/lang.html.
Most of these examples here are just standard SQL and not unique to SQLite.
Here are some practical examples.
Comments
SQLite supports single-line and multi-line comments. It supports C-style
comments and comments that go until the end of the line.
-- Single line comment
SELECT * FROM sqlite_master; -- Comment at end of line
/*
This is a
Multi line
comment
*/
Create and delete tables
This is a basic example of creating a table. It uses basic SQL syntax
without anything too special.
The IF NOT EXISTS clause is optional.
You can also add unique contrains with the CONSTRAINT clause.
CREATE TABLE IF NOT EXISTS images(path TEXT, thumbs_up INT);
CREATE TABLE my_table (
some_int INT,
some_text TEXT,
some_float REAL,
some_blob BLOB,
CONSTRAINT enforce_unique_numbers UNIQUE (some_int, some_float)
);
There are only a few Sqlite3 datatypes.
NULL— Empty valueINTEGER— Basic whole numberREAL— 64-bit floating pointTEXT— StringBLOB— Binary or raw data
To drop or delete a table, use:
DROP TABLE mytable;
Modify tables
To make changes to an existing table you use the ALTER TABLE statement.
You use this statement to rename tables, rename columns within tables,
to add columns and
-- Rename table
ALTER TABLE mytable RENAME to mynewtable;
-- Add a column
ALTER TABLE ADD COLUMN username TEXT;
Queries
Here are a few simple examples of how to query data from a database.
SELECT * FROM mytable;
SELECT field1, field2 FROM mytable;
SELECT COUNT(*) FROM mytable;
SELECT * FROM mytable ORDER BY create_date DESC;
Insert statements
There is nothing special about the insert statements either, just standard
SQL.
INSERT INTO images (path, thumbs_up) VALUES ("image1.png", 0);
Update statements
Update statements also work as you would generally expect with most SQL dialects.
UPDATE images SET thumbs_up=5 WHERE path="image1.png";
# To set multiple fields at once:
UPDATE images SET thumbs_up=10, description="an image" WHERE path="image1.png";
Delete statements
To delete rows, use a delete statement like the following:
DELETE FROM images WHERE path="image1.png";
Like operator
To match partial strings, you can use a LIKE clause. For example:
SELECT FROM images WHERE path LIKE '%.png';
SELECT FROM images WHERE path LIKE '%.jp_g';
SELECT FROM images WHERE path like '%dog%'
The % means match zero or more characters,
and the _ means match up to a single character.
Manage index
Indices are used to speed up read operations, but they slow down write operations.
You can create an index on any column and a table may have more than one index.
Include the UNIQUE if you want to enforce unique values on the column.
CREATE INDEX image_path_index ON images (path);
CREATE INDEX IF NOT EXISTS image_path_index ON images (path);
CREATE UNIQUE INDEX unique_image_path_index ON images (path);
To delete an index, use the DROP INDEX command and pass it the index name.
DROP INDEX image_path_index;
DROP INDEX [IF EXISTS] image_path_index;
Transactions
SQLite does support transactions, allowing you to execute a series
of statements that can either be rolled back and undone, or finalized and committed.
Start a transaction with BEGIN and then execute the statements you want
like deleting a row. Then end the transaction by executing ROLLBACK
or COMMIT depending on whether you want to undo or complete the transaction.
BEGIN TRANSACTION;
-- Perform whatever actions you want now.
-- Undo anything done since `BEGIN` and end transaction
ROLLBACK TRANSACTION;
-- Save changes done since `BEGIN` to the database and end transaction
COMMIT TRANSACTION;
Null fields
You can restrict fields from ever being null by adding a NOT NULL clause
like this:
CREATE TABLE users (
id INT,
profile_id INT NOT NULL
);
Default values
You can provide a default value for a field if no value is provided by
using a DEFAULT clause like this:
CREATE TABLE users (
id INT,
profile_id INT DEFAULT NULL
);
Primary and Foreign Keys
Foreign keys will require a valid value or it won’t accept the entry.
You can optionally add an ON UPDATE clause that will specify what to do if the
referenced foreign object is deleted. You can choose from the following:
- NO ACTION — Do nothing
- RESTRICT — Do not allow deleting when foreign key reference exists
- SET NULL — Set to null
- SET DEFAULT — Use the fields default value
- CASCADE — Delete the foreign reference too
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
profile_id INT,
FOREIGN KEY(profile_id) REFERENCES profiles(id)
);
CREATE TABLE profiles (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INT,
bio TEXT,
FOREIGN KEY(user_id) REFERENCES users(id) ON UPDATE CASCADE
);
CREATE TABLE posts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INT,
content TEXT,
FOREIGN KEY(user_id) REFERENCES users(id)
);
CREATE TABLE clans (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT
);
CREATE TABLE clans_users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INT,
clan_id INT,
FOREIGN KEY(user_id) REFERENCES users(id),
FOREIGN KEY(clan_id) REFERENCES clans(id)
);
Autoincrement fields
You can optionally set fields to auto increment, like on a primary key field
using the AUTOINCREMENT clause like this:
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL
);
Note that by default, each table automatically comes with a slightly hidden
field named rowid that acts as a unique, autoincremented field. You have
to explicitly query for it otherwise it does not come back with queries.
You can have a table NOT create the rowid field by using the WITHOUT ROWID clause
like this:
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL
) WITHOUT ROWID;
Note that when specifying WITHOUT ROWID you must provide an alternative
primary key.
Programming language bindings
While SQLite is written in C and comes with TCL bindings,
there are also language bindings
for virtually every language out there. Some languages, like Python,
even include SQLite in the standard library.
- Python
- Ruby — See my Ruby SQLite Tutorial
- Java
- JavaScript
- Go
Database browsing tools
Sometimes the interactive command line shell can be a bit tedious.
There are a few graphical tools for browsing and managing SQLite databases.
Some of the ones I would recommend include:
- SQLite Browser
- Visual Studio Code Extension: SQLTools
- JetBrains DataGrip
- JetBrains Professional IDEs like PyCharm Professional and IntelliJ Ultimate
References
- All SQLite tutorials of mine at https://www.devdungeon.com/tags/sqlite
- Compiling SQLite3 with C++
- Ruby SQLite Tutorial
- Ruby ActiveRecord (without Rails) Tutorial
- PHP SQLite Tutorial
- https://www.sqlite.org
- https://www.sqlite.org/lang.html
- https://www.sqlite.org/docs.html
- https://www.sqlite.org/download.html
- https://www.sqlite.org/whentouse.html
- https://brew.sh/
- SQLite Browser
- SQLTools
- DataGrip
- PyCharm Professional
- IntelliJ Ultimate
Последнее обновление: 26.11.2021
Для работы с SQLite разработчики данной СУБД предоставляют консольный клиент sqlite3. Рассмотрим вкратце, как с ним работать.
Прежде всего нам надо загрузить sqlite3. Для этого перейдем на страницу https://www.sqlite.org/download.html.
Название необходимого нам пакета начинается с sqlite-tools. И на странице загрузки мы можем найти версии для Windows, Linux, MacOS:
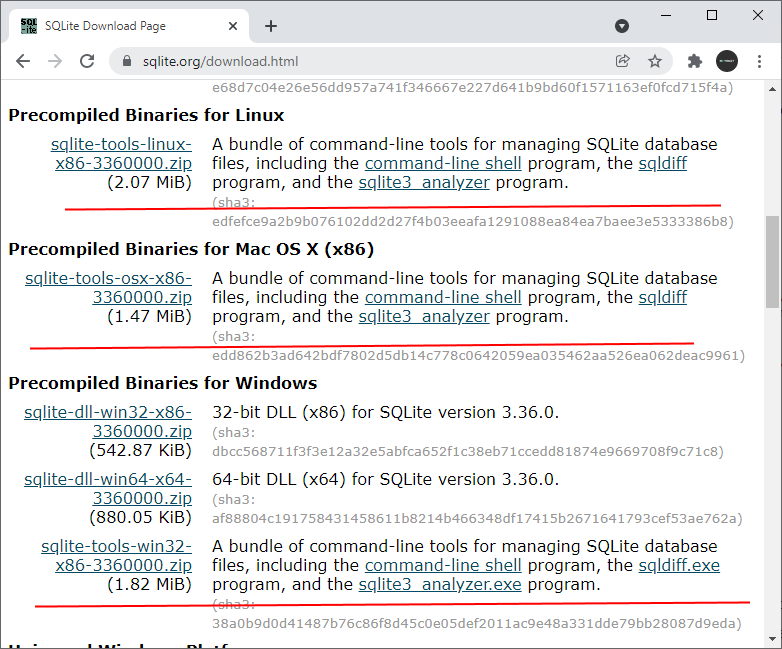
Загрузим нужную нам версию и распакуем ее.
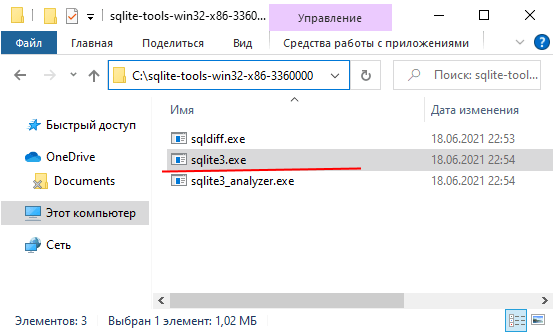
В распакованной папке мы сможем найти три утилиты, из которых файл с названием sqlite3 и представляет собственно
консольную оболочку для работы с бд SQLite. Запустим ее:
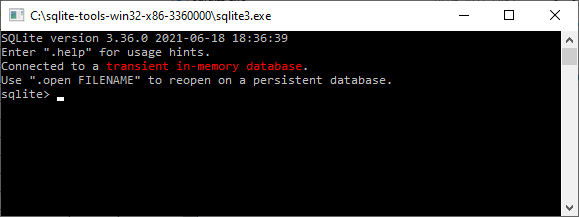
Открытие базы данных
Для открытия базы данных необходимо ввести команду .open, после которой указывается путь к базе данных. Например,
В данном случае будет открыта база данных под названием «test.db’, которая находится в той же папке, что и консольная утилита. Если базы данных не существует,
то она создается.
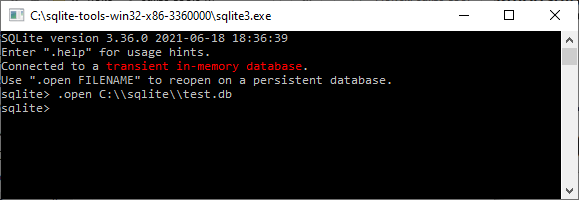
Также можно передать абсолютный путь:
sqlite>.open C:\\sqlite\\test.db
После открытия мы сможем работать с этой бд.
Создание таблицы
Для создания таблицы после открытия базы данных необходимо ввести команды CREATE TABLE, после которой указываются название таблицы и спецификация ее столбцов:
sqlite>create table users(name text, age integer);
В данном случае создается таблица users, в которой два столбца: столбец name, который имеет тип text, и столбец age, который имеет
тип integer
Обратите внимание, что команда завершается точкой с запятой. И все команды SQL должны завершаться точкой с запятой, благодаря чему sqlite может идентифицировать,
что выполняется sql-команда.
Операции с данными
Для добавления данных применяется команда INSERT INTO. Например, добавим в таблицу users одну строку:
sqlite>insert into users values ('Tom', 37);
Теперь получим ранее добавленны данные. Для этого используем команду SELECT:
sqlite>select * from users;
И sqlite выведет нам все данные из таблицы users:
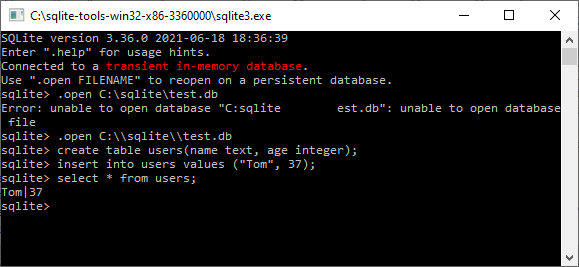
Image by shinichi | Some Rights Reserved
When one is developing in .NET with Visual Studio and other Microsoft tools, it is easy to lose sight of alternative solutions to common problems. MS does a competent job of creating a tightly integrated development tool chain, where available MS products (both free and paid) offer reasonable default choices which generally get the job done.
Given this, .NET devs often fail to explore outside this arena, or try on alternate solutions which might acquit themselves equally as well, or better, to the problem at hand. Also, of course, there is always a learning curve to new choices, and we often choose the familiar out of simple expediency.
- Getting Started – Using SQLite on Windows
- Open a New Database and Create Some Tables from the SQLite3 Console
- Entering SQL in the SQLite Console
- Formatting the Console Output
- Change the Display Mode for the SQLite Console
- Executing Script Files from the SQLite Console Using the .Read Command
- Wrap Multiple Actions in Transactions for Instant Performance Boost
- GUI-Based Tools
- Additional Resources and Items of Interest
Some Background
SQLite is an awesome, open source, cross-platform, freely available file-based relational database. Database files created on Windows will move seamlessly to OSX or Linux OSes. The tools (in particular the SQLite3 Command Line CLI we examine here) work the same from one environment to the next.
It is also not new. If you have been around for a while, you doubtless know SQLite has been in active and open development for well over a decade, and is widely used in many different scenarios and operating environments. In fact, SQLite.org estimates that SQLite is in fact the most widely deployed SQL database solution in the world. Their most recent figures (albeit from 2006) would indicate that there are over 500 million deployments of SQLite (this number is no doubt higher by now).
SQLite documentation is also widely regarded as above average in completeness and usability, providing both new and experienced users a well-developed canonical resource for learning and troubleshooting.
SQLite was originally designed by D. Richard Hipp in 2000 for the U.S. Navy, with the goal of allowing SQLite-based programs to function without installing a database management system, and without requiring a system administrator (from Wikipedia). These design requirements result in, as the SQLite site describes it, “a software library that implements a self-contained, serverless, zero-configuration, transactional SQL database engine.”
Until recently, I had not spent much time with SQLite. However, in developing the Biggy project, we decided that the core supported database systems would be cross-platform and open source. We wanted both a full-on client/server option, as well as a file-based relational database option. For our file-based relational database we chose SQLite, after exploring other alternatives.
In fitting SQLite into the Biggy workflow, I got to the chance to familiarize myself with SQLite, it strengths, some weaknesses, some peculiarities to watch for, and some tips and tricks for getting the most out of the product.
In this post, we will get familiar with the basics of using the database in a Windows environment. Next post, we will explore integration with .NET development, and Visual Studio. But, learn the hard way first always say, so… let”s get our command line on.
Getting Started – Using SQLite on Windows
Before we look at using SQLite in Visual Studio, let’s walk through the basics of using SQLite in a Windows environment outside the IDE.
First, download the pre-compiled binaries from the SQLite Downloads page. At a minimum you will want the binaries for the Win32 x86 SQLite dll, and for the SQLite x86 Command Shell. Unzip the contents of the files in a folder named C:\SQLite3 (or whatever other location suits your needs). Then add C:\SQLite3 to your PATH variable so that you can invoke the SQLite Command Shell right from the Windows console.
In your new directory C:\SQLite3 you should now have the following items:
- sqlite3.def
- sqlite3.dll
- sqlite3.exe
If we run the sqlite3.exe, we are greeted with a Console Application designed to allow us to work with SQLite databases:
The SQLite Console:

The command prompt is easy to use. Text entered without the “.” qualifier will be treated as SQL (and succeed or fail accordingly). There are a set of commands preceded with the “.” qualified which are application commands. An example is shown in the console window above, where we are instructed to use the .open command to open a database file.
The complete list of SQLite console commands is beyond the scope of this article, but we will walk through a list of the most useful here.
Open a New Database and Create Some Tables from the SQLite3 Console
The SQLite3 Console will open in the current directory (or in the directory in which the .exe is found, if you double-click in the GUI). Let’s start by opening a new Windows terminal (which should generally open in our home directory), create a new sub-directory named sqlite_data, and navigating into that folder:
Create a new Directory and Navigate Into the New Directory:
C:\Users\John> mkdir sqlite_databases C:\Users\John> cd sqlite_databases
Next, let’s try on that .open command. Open sqlite3 and open a new database in the directory we just created:
Open SQlite3.exe and Open a New Database File:
C:\Users\John\sqlite_databases>sqlite3 sqlite> .open test.sqlite
Your console output should now look like this:
Console Output after Opening SQLite3 and Creating a New Database File:

Next, let’s create a few tables to play with.
Entering SQL in the SQLite Console
Recall that plain text entered without the “.” qualifier will be interpreted by the SQLite console as SQL. There are a few additional things to bear in mind:
- SQL text may span multiple lines – the enter key will not cause the text following the prompt to execute until it is ended with a semi-colon.
- You can create multi-line SQL statements simply by hitting the Enter key without ending the statement with a semi-colon.
- SQLite uses either square brackets or double-quotes as delimiters for object names, in cases where the literal column name would not be allowed. For example, Last Name would NOT be a valid column name, but will work as [Last Name] . Likewise, the keyword Group is not allowed as a column name, but “Group” will work.
- SQLite is not case-sensitive. Unlike some other databases (most notably Postgresql), casing in both the SQL syntax, and in object names, is ignored.
So, with that said, let’s create a table or two.We will keep this really basic, since we are interested in how the console works, more so that a SQLite SQL syntax tutorial.
Create a Table in a Single-Line Statement:

Above, we just kept typing our whole SQL statement, and allowed the console to wrap the text when it needed to (that lovely Windows console, with its under-developed display characteristics…). Kinda ugly and hard to read. Let’s try a multi-line statement.
Create a Table Using a Multi-Line Statement:

Aside from the ugliness that is the Windows Console, that’s a little more readable.
Now let’s add a few records.
Insert Records into Test Database:

Notice how the case of my SQL doesn’t matter in the above? And, yes, as a matter of fact, that IS a syntax error in the midst of things there. I accidentally used an angle bracket instead of a paren…
So now, we have added a little data. Let’s read it back:
Select Data from Users Table:

Here we see that for unrelated reasons (ahem… I closed the wrong window…), I had to exit the application, and then go back in. However, once I opened our test.sqlite database, I was able to enter a standard SELECT statement, and return the data.
See that ...>;? That was the result of me forgetting to add the semi-colon at the end of my SELECT statement. If you do that (and you WILL…), simply add a semi-colon on the continued line, and the statement will execute (remember, until SQLite3 sees a semi-colon, it will continue to interpret text input as more SQL).
Formatting the Console Output
We can tell SQLite3 how we would like our data displayed. For example, we may prefer to see a more tabular display, with columns and headers. To accomplish this, we use a few of those application commands, prefixed with a period:
Change the Display Mode for the SQLite Console
We can use the following two commands to change the display mode and use columns and headers in our console output:
Use Column Display Mode with Headers in SQLite3
sqlite> .mode column sqlite> .headers on
If we run our SELECT statement again, the output looks like this:
Console Output Using Columns and Headers:

Executing Script Files from the SQLite Console Using the .Read Command
Of course, typing in SQL in the console can become painful. While it is fine for quick-and-diry queries and maintenance tasks, doing a lot of work is better accomplished by scripting out what you need in a text file, and then executing that from the Console.
To see this in action, we will download my personal favorite test database, the Chinook database. Chinook has a database script for most of the popular database platforms, providing a handy way to use the same data set for evaluating multiple platforms (among other things). Download the Chinook Database, extract the .zip file, and locate the Chinook_Sqlite_AutoIncrementPKs.sql file. To keep things simple, drop a copy of it into your sqlite_databases folder, so it is in the current directory. Then, also to keep out typing down, rename the file you just moved to simply “Chinook.sql”.
We can execute SQL scripts using the SQLite .read command. To illustrate, we will read in the Chinook database.
You will notice a couple things when we do this. First, the console may show an error (which you can see in the image below), but the script is still running – errors are logged out to the console.
Second, executing this script in its current form is SLOOOOWWWW. This is due to a peculiarity with SQLite we will address momentarily, but was not addressed by the creators of the Chinook Database script.
Execute SQL Script from the SQLite Console Using the .Read Command
sqlite> .read Chinook.sql
The script may run for a good number of minutes, so go grab a cup of coffee or something. your computer has not seized up. The Console will return when the script is finished (really, this took about 10 minutes on my machine, but we’re going to fix that…
<Coffeee Brake . . .>
Ok. Now that the script has finished running, let’s use the .tables command to see a list of the tables in our database. If everything worked as we expect, we should see our own users and groups tables, as well as a bunch of new ones populated with Chinook data:
List Tables Using the .Tables Command:
sqlite> .tables
We should see something like this:
Console Output from .Tables Command:

Now, why the hell did it take so long to run that script??!!
Wrap Multiple Actions in Transactions for Instant Performance Boost
SQLite is inherently transaction-based. Meaning, unless you specify otherwise, each statement will be treated as an individual transaction, which must succeed, or be rolled back.
Transactions are a key feature of relational databases, and critical in the big scheme of things. However, individually, transactions add significant performance overhead, and when we are inserting (or updating, or otherwise modifying) thousands of records in multiple tables, treating each insert as an individual transaction slows things WAAAAYYYY DOWWN.
If we go through the Chinook.sql script and place a BEGIN; statement before the inserts for each table, and a COMMIT; statement at the end of the INSERTs for each table, we will see several orders magnitude better performance from this script.
We can skip wrapping the DROP and CREATE table statements in transactions for our purposes here. As an example, open the file in your favorite text editor, go through and find the beginning of the INSERTs for the Genre table. Add a BEGIN and COMMIT clause like so:
Wrap Table Inserts in Transactions:
BEGIN;
INSERT INTO [Genre] ([Name]) VALUES ('Rock');
INSERT INTO [Genre] ([Name]) VALUES ('Jazz');
... Etc ...
INSERT INTO [Genre] ([Name]) VALUES ('Alternative');
INSERT INTO [Genre] ([Name]) VALUES ('Classical');
INSERT INTO [Genre] ([Name]) VALUES ('Opera');
COMMIT;
Now scroll on down, and do the same for each table. When you are done, let’s create a dedicated Chinook database to try it out.
Open the Windows Console, navigate back to sqlite_databases directory, run sqlite3, and open a new database named chinook.db. Then use .read to execute the chinook.sql script again:
Read Chinook Script into Chinook.db:
C:\Users\John>cd sqlite_databases C:\Users\John\sqlite_databases>sqlite3 sqlite> .open chinook.db sqlite> .read chinook.sql
Next, use the .tables command again to see that all the tables were created. The console output should look like this:
Console Output from Execution after Wrapping Table Inserts in Transactions:

We see there is still a little error bugaboo at Line 1 (most likely due to some unicode issue at the beginning of the file – welcome to the world of scripts). However, we can see if our data imported fairly easily:
Select Artists from the Chinook Artists Table:


GUI-Based Tools
We’ve covered enough here that we can explore what SQLite has to offer from the Windows console, and become familiar with this fantastic little database. Of course, there are other tools available to work with SQLite databases, including a terrific multi-platform GUI-based interface, SQLiteBrowser, which is a very competent management interface for SQLite databases.
As mentioned previously, the documentation available at SQL.org is first-rate, and there are a host of other resources out there as well.
SQLite is a handy, mature, highly performant database which is easy to use, and works on all the major OS platforms. Database files created on a Windows machine can move seamlessly between OSX and *Nix OSes, as can most of the tools designed to work with them.
I like to start everything with the most fundamental tools available, and then once I have developed a solid understanding of the system, move on up to more advanced tools. Take some time and get to know SQLite from the basic CLI interface. You won’t regret it.
Additional Resources and Items of Interest
- Command Line Shell for SQLite – Reference at SQLite.org
- SQLite Syntax – Reference at SQLite.org
- Database Browser for SQLite
- Adding and Editing PATH Environment Variables in Windows
- C#: Using Reflection and Custom Attributes to Map Object Properties