
Apache Spark is an open-source framework for processing large volumes of batch and streaming data from multiple sources. It is used in distributed computing for machine learning, data analytics, and graph processing tasks.
Learn how to install Apache Spark on Windows and verify the installation works.

Prerequisites
- A system running Windows 10 or 11.
- A user account with administrator privileges.
- Access to Windows Command Prompt or PowerShell.
- A tool to extract .tar files, such as 7-Zip or WinRAR.
Install and Set Up Apache Spark on Windows
To set up Apache Spark, you must install Java, download the Spark package, and set up environment variables. Python is also required to use Spark’s Python API called PySpark.
If you already have Java 8 (or later) and Python 3 (or later) installed, you can skip the first step of this guide.
Step 1: Install Spark Dependencies
Using the Windows winget utility is a convenient way to install the necessary dependencies for Apache Spark:
1. Open Command Prompt or PowerShell as an Administrator.
2. Enter the following command to install the Azul Zulu OpenJDK 21 (Java Development Kit) and Python 3.9:
winget install --id Azul.Zulu.21.JDK -e --source winget && winget install --id Python.Python.3.9 -e --source winget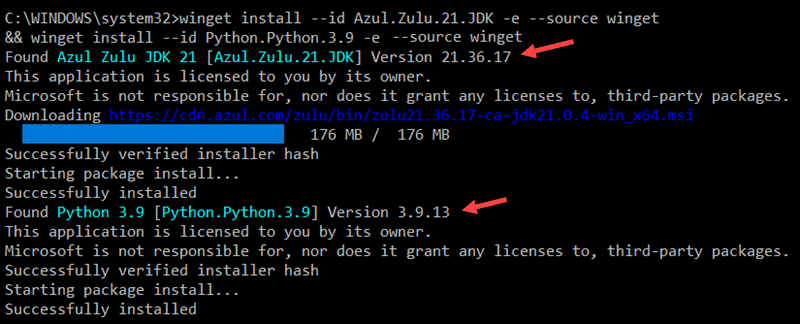
Adjust the command if you need a specific Java or Python version or a different OpenJDK vendor.
3. The OpenJDK installation is in the C:\Program Files\Zulu\zulu-21 folder by default. The space in the path can cause issues when launching Apache Spark. Avoid this by moving the installation to a folder without spaces. Use the following command to create a new Zulu folder in the root directory and move the installation:
mkdir C:\Zulu && robocopy "C:\Program Files\Zulu\zulu-21" "C:\Zulu\zulu-21" /E /MOVE4. Verify the installation by checking the Java and Python versions:
java -version && python --version
The output confirms your system is using OpenJDK 21 and Python 3.9.
Step 2: Download Apache Spark
To download the latest Apache Spark release:
1. Open a browser and navigate to the official Apache Spark download page.
2. The latest Spark version is selected by default. At the time of writing, the latest version is Spark 3.5.3 for Hadoop 3.3.
3. Click the spark-3.5.3-bin-hadoop3.tgz download link.
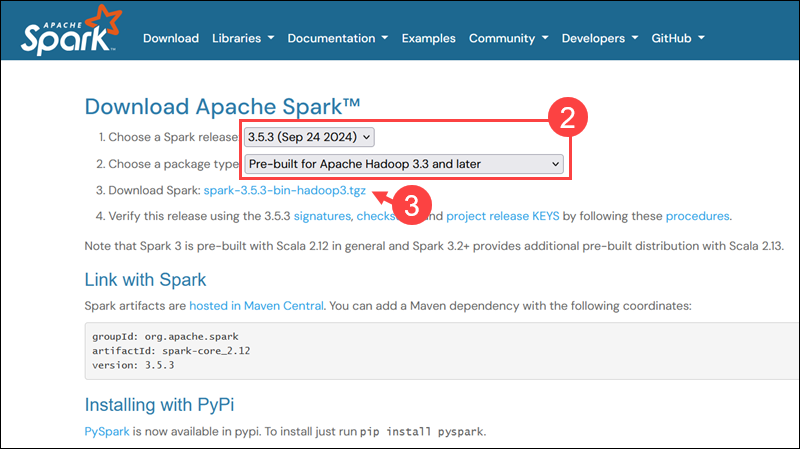
4. Select a location from a list of mirror servers to begin the download.
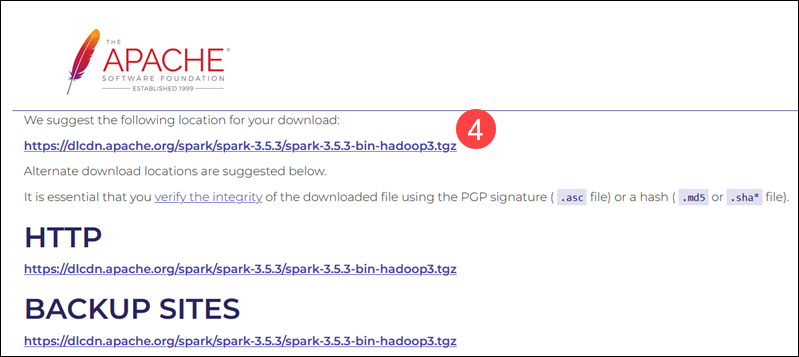
5. Save the file, for example, to the Downloads folder.
Step 3: Verify Spark Software File
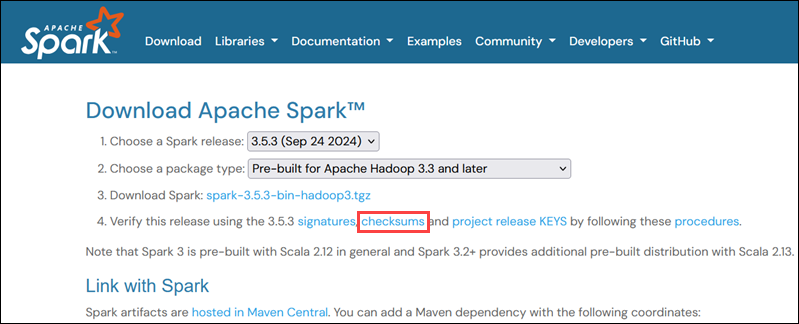
To verify that you are working with an unaltered, uncorrupted file, check its checksum:
1. Navigate to the Spark Download page and open the checksums link, preferably in a new tab.
2. Open Command Prompt and use the cd command to navigate to the folder where you downloaded Apache Spark. For example, if the file is in the Downloads folder, enter:
cd C:\Users\username\DownloadsReplace username with your actual Windows username.
3. Use the following command to calculate the downloaded file’s checksum:
certutil -hashfile spark-3.5.3-bin-hadoop3.tgz SHA512
The system displays a long alphanumeric code followed by the message Certutil: -hashfile completed successfully.
4. Manually compare the checksum output with the one on the Apache Spark website.
If they match, the file is legitimate.
Step 4: Install Apache Spark
To install Apache Spark, extract the downloaded file to a desired location:
1. For example, create a new Spark folder in the root of the C: drive using the following command:
cd \ && mkdir Spark2. Use 7-Zip to extract the Spark .tar file from the .tgz compressed file and place it in the Spark folder:
"C:\Program Files\7-Zip\7z.exe" x "C:\Users\username\Downloads\spark-3.5.3-bin-hadoop3.tgz" -oC:\Spark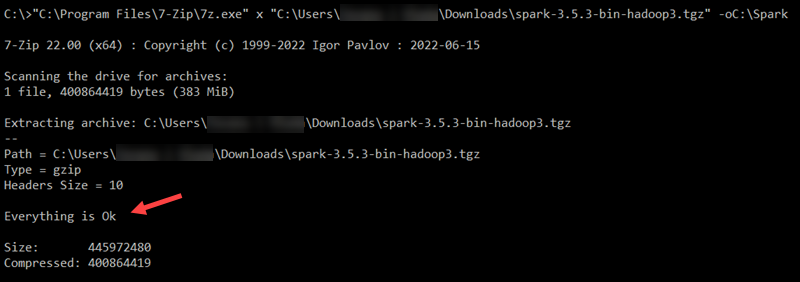
Replace username in the file path with your username.
Note: The file paths are wrapped in double quotes because the username and folder names contain spaces.
3. Extract the Spark binaries from the Spark .tar file:
"C:\Program Files\7-Zip\7z.exe" x "C:\Spark\spark-3.5.3-bin-hadoop3.tar" -oC:\Spark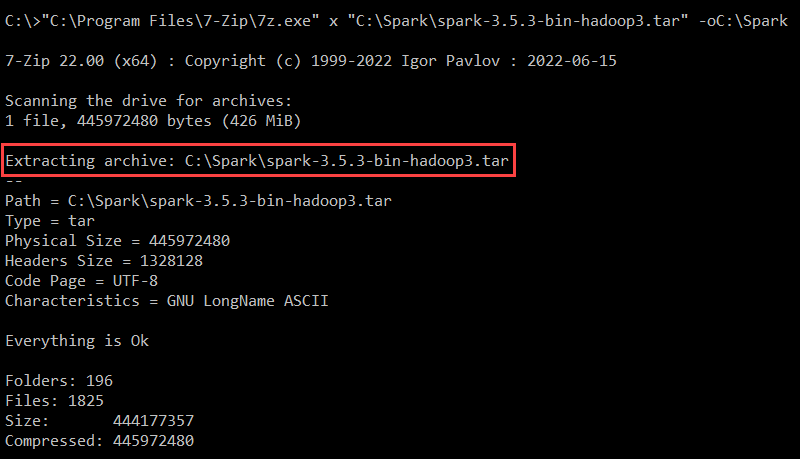
4. Use the dir command to list the contents of the Spark folder:
cd C:\Spark && dir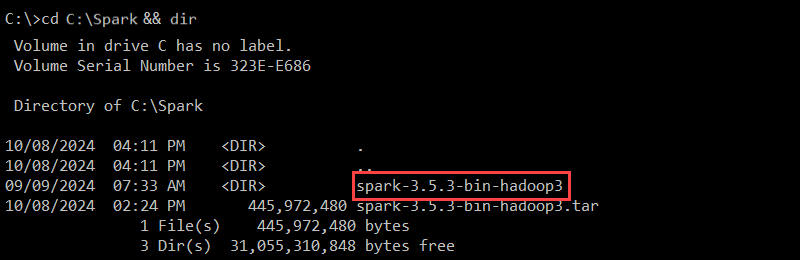
The spark-3.5.3-bin-hadoop3 folder contains the necessary files to run Spark.
Step 5: Add winutils.exe File
The winutils utility enables Apache Spark and other Hadoop-based tools to run on Windows. You need to download the winutils.exe file that matches the Hadoop version used by your Spark installation:
1. Create a hadoop\bin folder in the C: drive to store the winutils.exe file:
cd \ && mkdir C:\hadoop\bin2. Use the curl command to download the file from the winutils GitHub repository into the newly created folder:
curl --ssl-no-revoke -L -o C:\hadoop\bin\winutils.exe https://github.com/cdarlint/winutils/raw/master/hadoop-3.3.5/bin/winutils.exe
In this example, the Hadoop version is 3.3.5. If necessary, edit the command to correspond to the Hadoop version your Spark installation is using.
3. Verify that the file has been downloaded:
cd C:\hadoop\bin && dir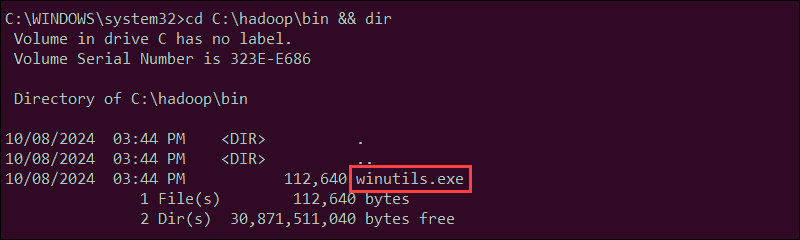
The winutils.exe file is listed in the folder.
Step 6: Configure Environment Variables
Add the Spark, Java, and Hadoop locations to your system’s Path environment variable to run the Spark shell directly from the CLI.
You can edit environment variables manually using the Windows UI. However, setting User Variables from Command Prompt can be faster and more efficient.
Use the setx command to set the SPARK_HOME User Variable:
setx SPARK_HOME "C:\Spark\spark-3.5.5-bin-hadoop3"To set HADOOP_HOME, enter:
setx HADOOP_HOME "C:\hadoop"To set JAVA_HOME, type:
setx JAVA_HOME "C:\Zulu\zulu-21"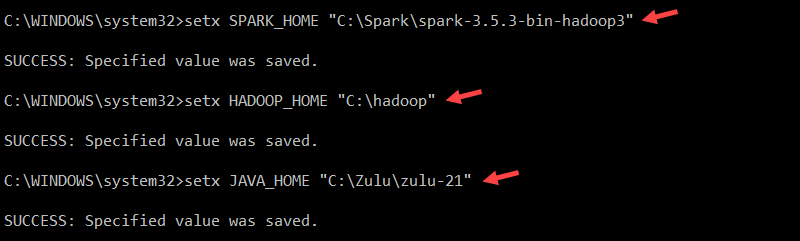
The paths in the commands are set based on the previous installation steps. If you used different versions and file paths, adjust the commands accordingly.
Enter the following command to retrieve the current Path from the registry and store it in the oldPath variable:
for /f "tokens=2*" %A in ('reg query "HKCU\Environment" /v Path') do set "oldPath=%B"Append the Spark, Hadoop, and Java paths to the Path variable without overwriting existing entries:
setx Path "%oldPath%;%SPARK_HOME%\bin;%HADOOP_HOME%\bin;%JAVA_HOME%\bin"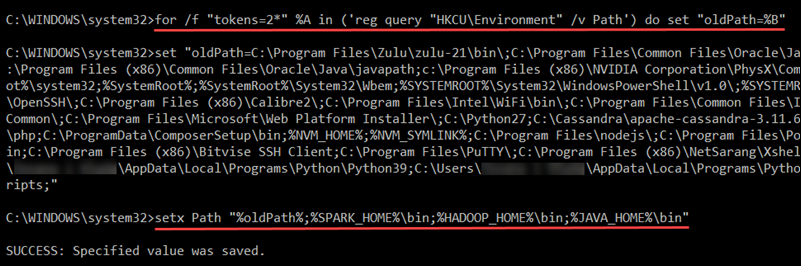
Restart Command Prompt to apply the changes. In rare instances, a full system reboot may be required.
Step 7: Launch Spark
To start the Spark Scala shell, enter the following:
spark-shellThis opens an interactive shell interface with Spark notifications and information. The output includes details about the Spark version, configuration, and available resources.
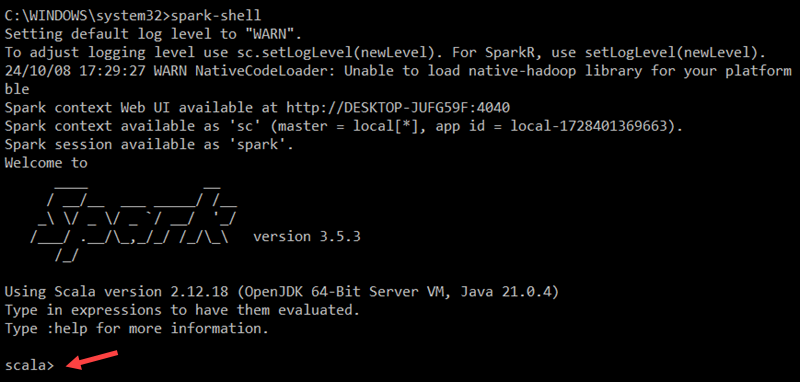
To access Spark’s Web UI, open a web browser and navigate to the following URL:
http://localhost:4040/You can replace localhost with the name or IP address of your system. The Spark Web UI provides details about running jobs, stages, and resource usage.
Use the following command to exit Spark and close the Scala shell:
:quitAlternatively, press CTRL+D while using the command prompt. Enter the following command to run Spark using Python:
pysparkThis launches the Spark shell with a Python interface.
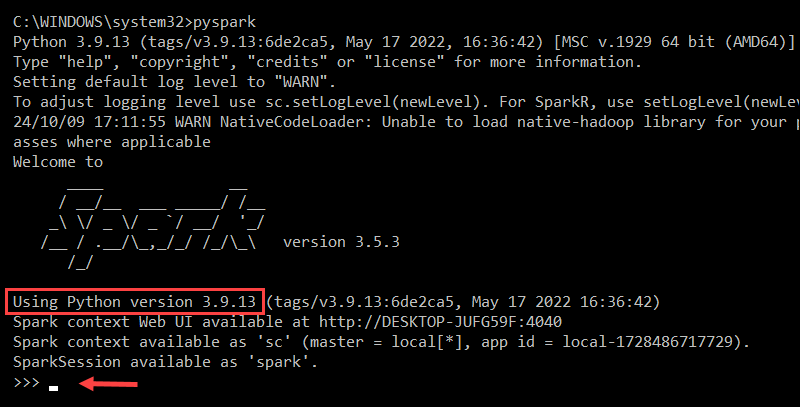
To exit pyspark, type:
quit()Test Spark
To test the Spark installation, use the Scala interface to read and manipulate a file. In this example, the name of the file is pnaptest.txt. Open Command Prompt and navigate to the folder with the file you want to use:
1. Launch the Spark shell:
spark-shell2. Load the file in the Spark context by defining a variable and specifying the file name (including its extension):
val x = sc.textFile("pnaptest.txt")The command loads the file into a Resilient Distributed Dataset (RDD), which allows you to perform actions and transformations on the data.
3. Enter the following command to perform an action on the RDD and view the contents of the file:
x.take(11).foreach(println)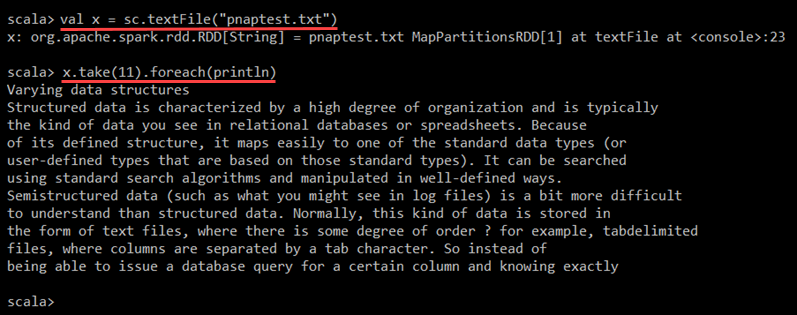
Spark displays the first 11 lines of the file. You can adjust the number of lines by changing the number in the take() method.
4. Use the map transformation to create a new RDD based on the existing one. For example, reverse each line of the file using the following command:
val y = x.map(_.reverse)This creates a new RDD (y), where each original RDD (x) line is reversed.
5. Enter the following command to display the first 11 lines of the transformed RDD:
y.take(11).foreach(println)
The output prints 11 lines of the pnaptest.txt file, with each line reversed.
When ready, enter the :quit command or press CTRL+D to exit the Spark shell.
Conclusion
You now have a working installation of Apache Spark on Windows 10 or 11. This local setup is ideal for running basic tests and getting familiar with Spark’s core features.
Read about Spark DataFrames and Spark Streaming to explore more advanced functionalities.
Was this article helpful?
YesNo
How to install Spark on Windows 11
Hello everyone, today we are going to install Spark on Windows.
Prerequisites
- Java 8 runtime environment (JRE)
- Apache Spark 3.3.0
Step 1 — Install Java 8 or Later
To install Apache Spark on windows, you would need Java 8 or the latest version hence download the Java version from Oracle and install it on your system. If you wanted OpenJDK you can download it from here.
You can install Java 8 from the following link here.
After finishing the file download we open a new command prompt, we should unpack the package
Because I am installing Java in folder Java of my C drive (C:\Java)
we create the the directory
then run the following command to unzip:
tar -xvzf jre-8u361-windows-x64.tar.gz -C C:\Java\
Note: This article explains Installing Apache Spark on Java 8, same steps will also work for Java 11 and 13 versions.
Step 2 — Download packages
Apache Spark comes in a compressed tar/zip files hence installation on windows is not much of a deal as you just need to download and untar the file.
For this tutorial we are going to install Apache Spark 3.3.2 with Pre-built Apache Hadoop 3.3
Download Apache spark by accessing the Spark Download page and select the link from “Download Spark ”.

We download the following file:
https://www.apache.org/dyn/closer.lua/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
After download, untar the binary using 7zip or any zip utility to extract the zip file and copy the extracted directory spark-3.3.2-bin-hadoop3.tgz to c:\Hadoop\spark-3.3.2-bin-hadoop3
Let us open a terminal and we create the the directory
then we go to the directory where was Downloaded the file
run the following command to unzip:
tar -xvzf spark-3.3.2-bin-hadoop3.tgz -C C:\Spark\
The extracted files are in the directory C:\Spark\spark-3.3.2-bin-hadoop3
cd C:\Spark\spark-3.3.2-bin-hadoop3
dir

Step 3 — Edit Spark Environment Variables
Now we’ve downloaded and unpacked all the artefacts we need to configure two important environment variables.
First you click the windows button and type environment
a) Configure Environment variables
We configure JAVA_HOME environment variable
by adding new environment variable:
Variable name : JAVA_HOME
Variable value: C:\Java\jre1.8.0_361
Follow the below steps if you are not aware of how to add or edit environment variables on windows.
- Open System Environment Variables window and select Environment Variables.
- On the following Environment variable screen, add
SPARK_HOME,HADOOP_HOME,JAVA_HOMEby selecting the New option. - This opens up the New User Variables window where you can enter the variable name and value

the same with SPARK_HOME environment variable:
Variable name : SPARK_HOME
Variable value: C:\Spark\spark-3.3.2-bin-hadoop3
and finally with HADOOP_HOME environment variable:
Variable name : HADOOP_HOME
Variable value: C:\Hadoop\hadoop-3.3.0
b) Configure PATH environment variable
Once we finish setting up the above two environment variables, we need to add the bin folders to the PATH environment variable. On Edit the PATH variable

If PATH environment exists in your system, you can also manually add the following two paths to it:
%JAVA_HOME%/bin
%SPARK_HOME%/bin
%HADOOP_HOME%/bin
Add Spark, Java, and Hadoop bin location by selecting New option.

Spark with winutils.exe on Windows
To run Apache Spark on windows, you need winutils.exe as it uses POSIX like file access operations in windows using windows API.
winutils.exe enables Spark to use Windows-specific services including running shell commands on a windows environment.
We create the folder
mkdir C:\Hadoop\hadoop-3.3.0\
Download winutils.exe for Hadoop 3.3 and copy it to %HADOOP_HOME%\bin folder.
cd Downloads
copy winutils.exe C:\Hadoop\hadoop-3.3.0\bin
Verification of Installation
Once you complete the installation, Close your terminal window and open a new one and please run the following command to verify:
you will have
java version "1.8.0_361"
Java(TM) SE Runtime Environment (build 1.8.0_361-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.361-b09, mixed mode)
You should also be able to run the following command:
Microsoft Windows [Version 10.0.22621.1555]
(c) Microsoft Corporation. All rights reserved.
C:\Users\ruslanmv>spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.1.207:4040
Spark context available as 'sc' (master = local[*], app id = local-1683488208402).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.2
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_361)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 23/05/07 21:37:04 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
spark-shell is a CLI utility that comes with Apache Spark distribution.
Spark-shell also creates a Spark context web UI and by default, it can access from http://localhost:4041.
Testing Spark
Open a new terminal and type
On spark-shell command line, you can run any Spark statements like creating an RDD, getting Spark version e.t.c
you will get
let us try type
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10))
you get
scala> val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:23
Congratulations! You have installed Apache Spark on Windows 11.
In the ever-expanding realm of massive data, the need for tools that can efficiently handle and process vast datasets is more crucial than ever. If you wish to unlock the transformative power of data analysis, set up Apache Spark on your Windows machine and embark on a data exploration journey.
Throughout this tutorial, you’ll discover the ropes of installing Apache Spark on your Windows system, positioning yourself to conquer the fascinating world of data analysis.
Transform your Windows environment into a data processing powerhouse!
Prerequisites
Before diving into the installation process, ensure you have all the necessary prerequisites in place.
- A Windows 7 system or later – This tutorial uses Windows 10 Pro 22H2.
- Java installed – This tutorial uses Java 1.8.0_391.
- Apache Subversion for Windows installed – This tutorial uses SlikSvn 1.14.2 (64-bit).
Installing Python for Apache Spark on Windows
As you ensure your Windows environment is primed for the upcoming Apache Spark installation, one essential step stands before you — installing Python.
Python serves as the glue that enhances the interoperability and extensibility of Spark. From handling data manipulations to running Spark scripts, Python acts as a powerful catalyst.
To install Python for Apache Spark on Windows, follow these steps:
1. Open your favorite web browser, visit the official Python download page, and download the latest Python Installer. At this time of writing, the latest version is Python 3.12.0.
2. Once downloaded, double-click on the installer to begin the installation process.
3. On the Setup window, tick the Add python.exe to PATH option, and click Install Now.
Enabling this option adds Python to your PATH environment variable, which eases the management of Python packages via package managers like pip or anaconda. As a result, you can install and manage Python libraries without additional configuration.
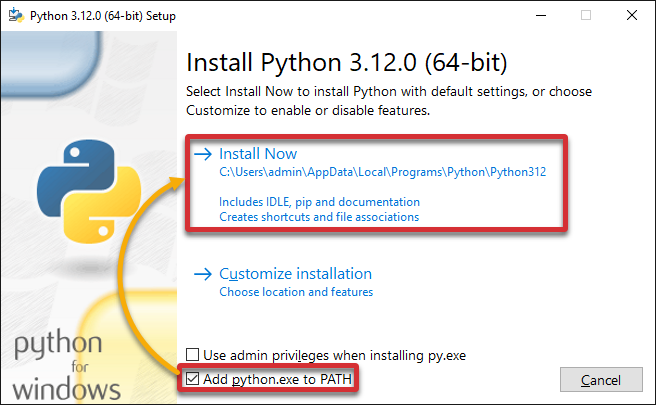
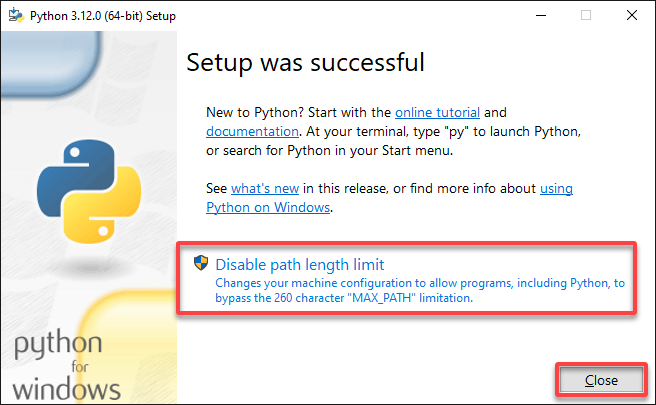
4. Now, select the Disable path length limit option, and click Close to close the Setup wizard.
This option allows Python to use the “Long Paths” feature to access paths longer than the traditional MAX_PATH limit (260 characters) on Windows. This feature is beneficial as some of the packages used by Apache Spark exceed the MAX_PATH limit.
5. Lastly, open PowerShell and run the below commands to verify your Python installation.
pip--version
python --version
Downloading and Installing Apache Spark
With Python installed, you can now lay the foundation for dynamic capabilities to flourish in your Windows environment. Installing Apache Spark opens a world of possibilities where data-driven insights are at your fingertips.
To install Apache Spark on Windows, proceed with the following:
1. Visit the official Apache Spark download page in another web browser tab.
2. Next, download the Apache Spark installation package as follows:
- Choose a Spark release – Select the latest release from the dropdown field (i.e., 3.5.0).
- Choose a package type – Pick a suitable one depending on whether you want to use Hadoop. Your version of Spark and Hadoop may slightly differ. For this example, choose Pre-built for Apache Hadoop 3.3 and later option, which is best if you use Spark with Hadoop. Otherwise, select the option without Hadoop.
- Download Spark – Click on the hyperlink, which opens a new tab (step three) to select your Apache Spark download location.
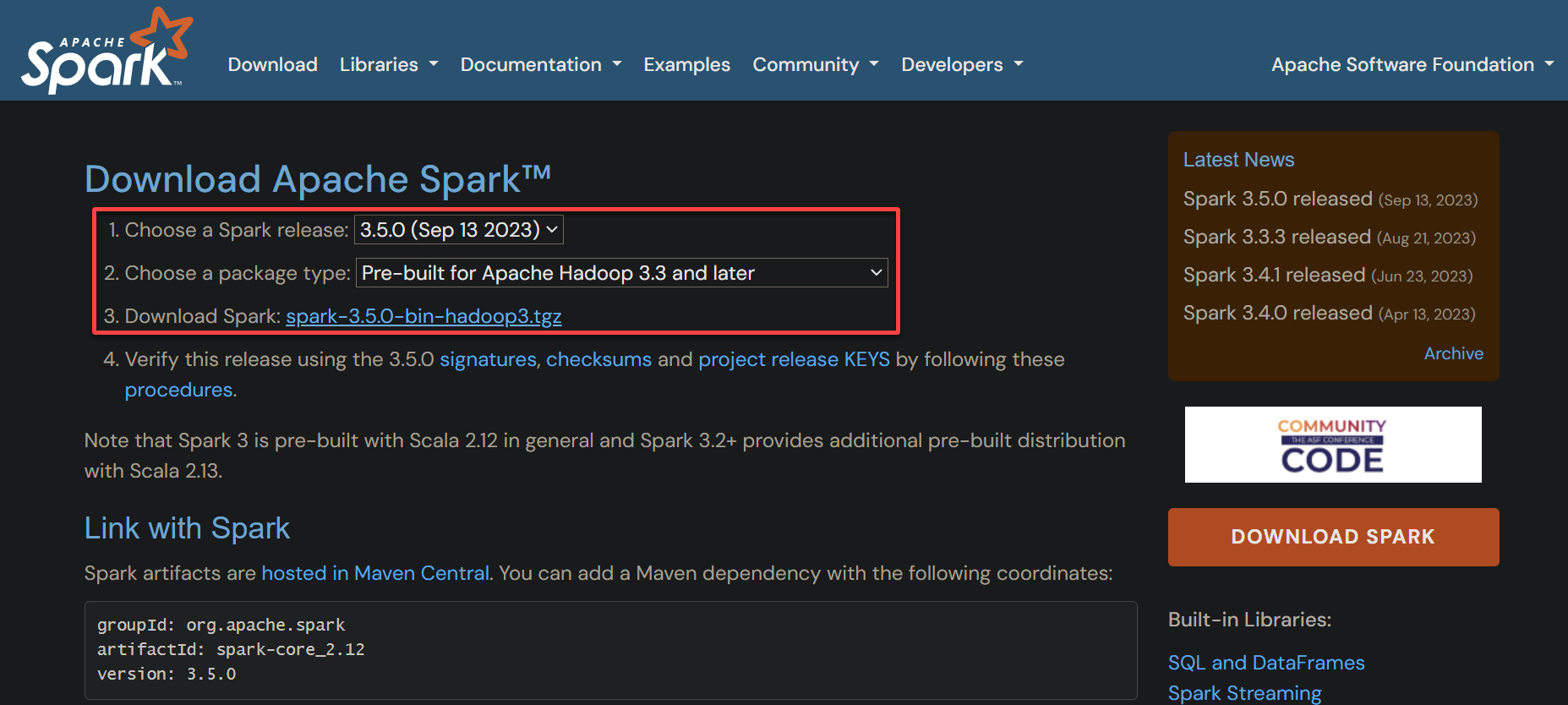
3. Click the first hyperlink or choose one from the alternate download locations to download the Apache Spark package.
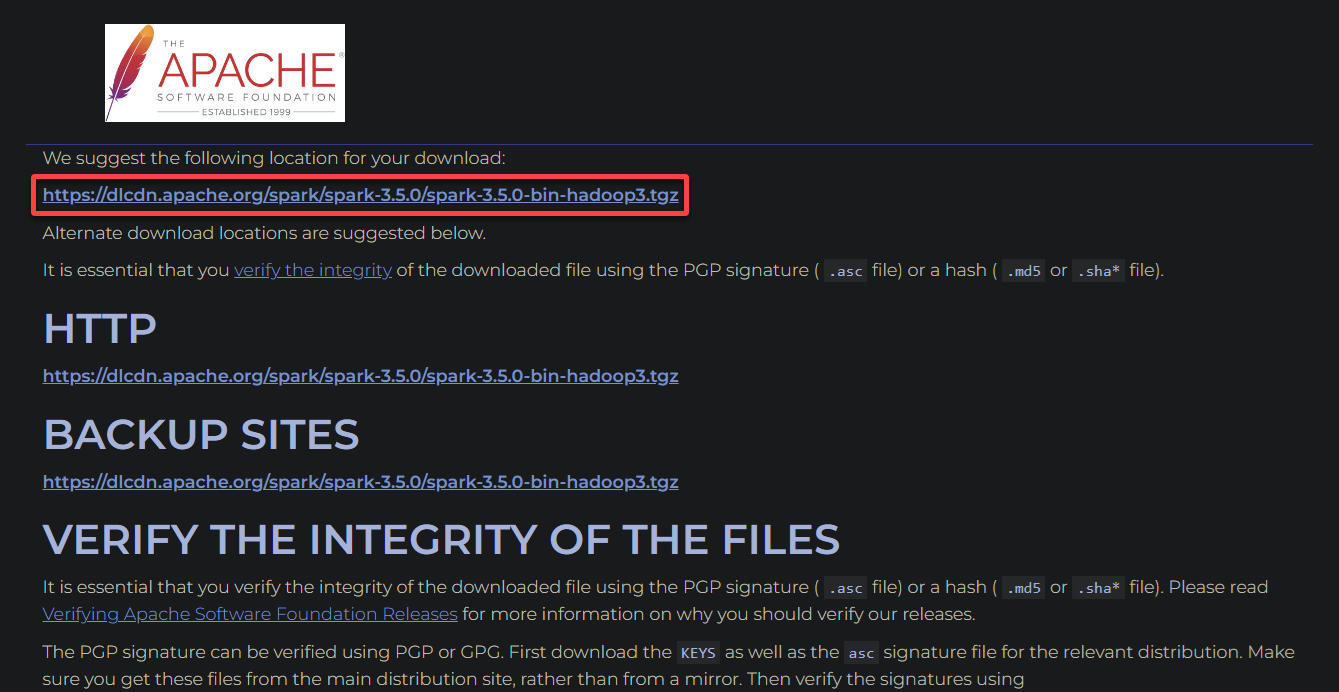
4. Once downloaded, execute the below command and generate a SHA512 hash of the downloaded file.
Ensure you replace spark-3.5.0-bin-hadoop3.tgz with the exact file name of the one you downloaded (or the full path).
certutil -hashfile .\spark-3.5.0-bin-hadoop3.tgz SHA512Note down the generated hash, as you will make a comparison later.

5. Switch back to the download page and click the checksum hyperlink. Doing so opens the hash file containing the expected SHA512 checksum for your chosen download (step six).
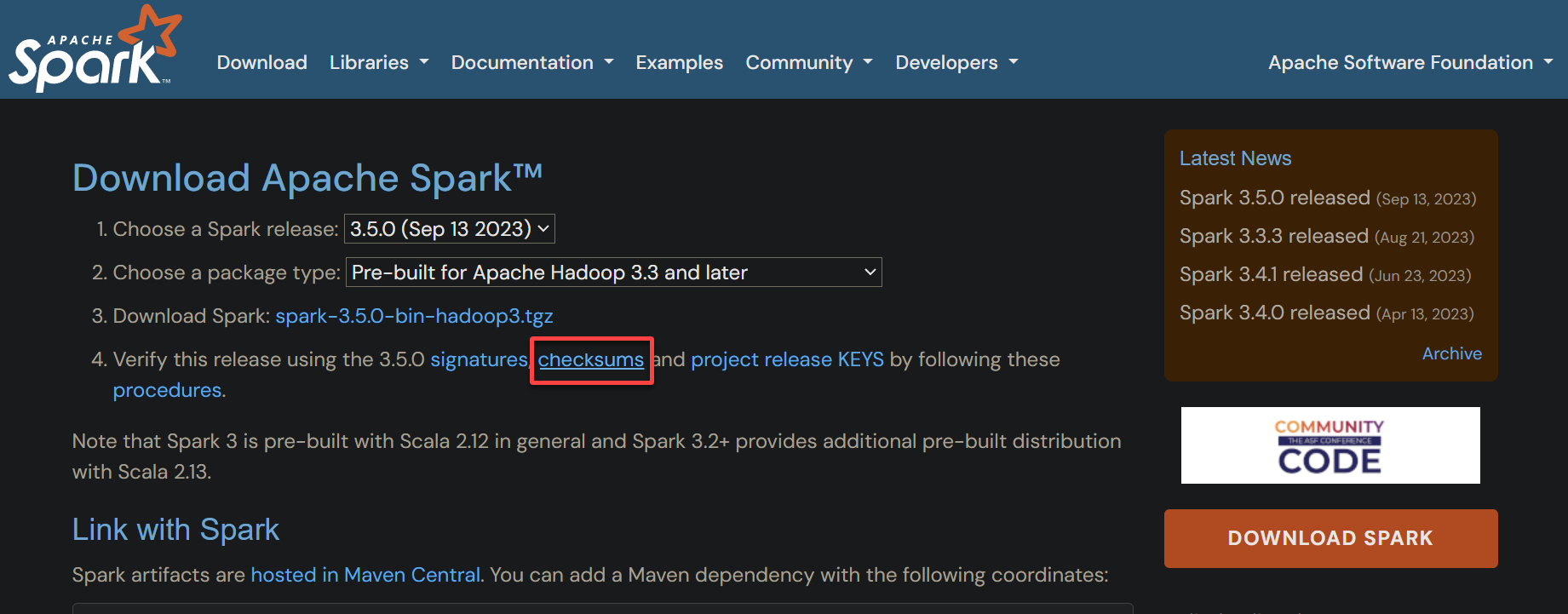
6. Compare the generated hash you noted in step four with the one in the checksum file.
Matching both hashes indicates your download was not corrupted or tampered with, and you can proceed with extracting the downloaded archive.
7. Lastly, unzip/extract the contents of the Apache Spark package using tools like 7-Zip or WinRAR to a directory of your choice.
For example, you can extract everything to the C:\spark folder, which effectively installs Apache Spark in your root directory.
After extraction, the Apache Spark installation directory structure should resemble the following:
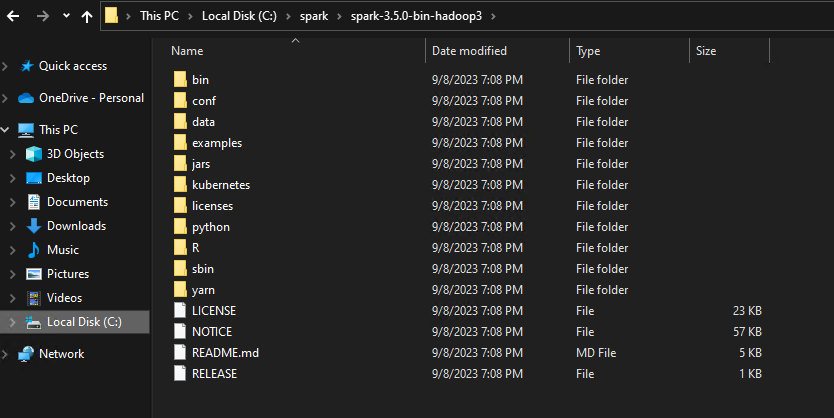
Installing the winutils.exe Utility for Required Functionalities
Now that Apache Spark has found its home on your Windows machine, the next step involves a nuanced touch — installing the winutils.exe utility. Apache Spark requires the winutils.exe utility to run smoothly on Windows.
This utility is essential for enabling the required file and directory operations functionality. The winutils.exe utility is crucial because these operations are typically available on Linux-based systems but need additional support on Windows.
To install the winutils.exe utility, complete the steps below:
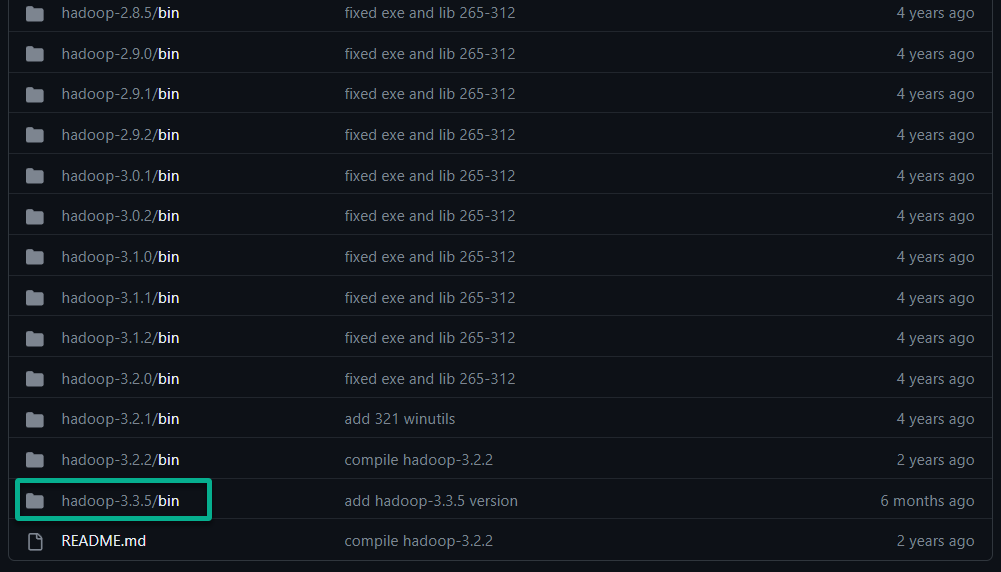
1. Visit the GitHub repository that provides the winutils.exe utility for Windows and look for the latest Hadoop version. Hadoop is an open-source framework designed for the distributed storage and processing of large data sets.
At this time of writing, the latest revision is hadoop-3.3.5, as shown below.
2. Next, run the following command to download the contents of the bin folder (hadoop-3.3.5/bin) to a folder called C:\hadoop\bin.
💡 If you see a newer version, change the folder name
hadoop-3.3.5and the revision number (r335) accordingly (i.e.,hadoop-3-3.6andr336).
This process effectively installs the winutils.exe utility on your Windows system.
svn export https://github.com/cdarlint/winutils/trunk/hadoop-3.3.5/bin@r335 "C:\hadoop\bin"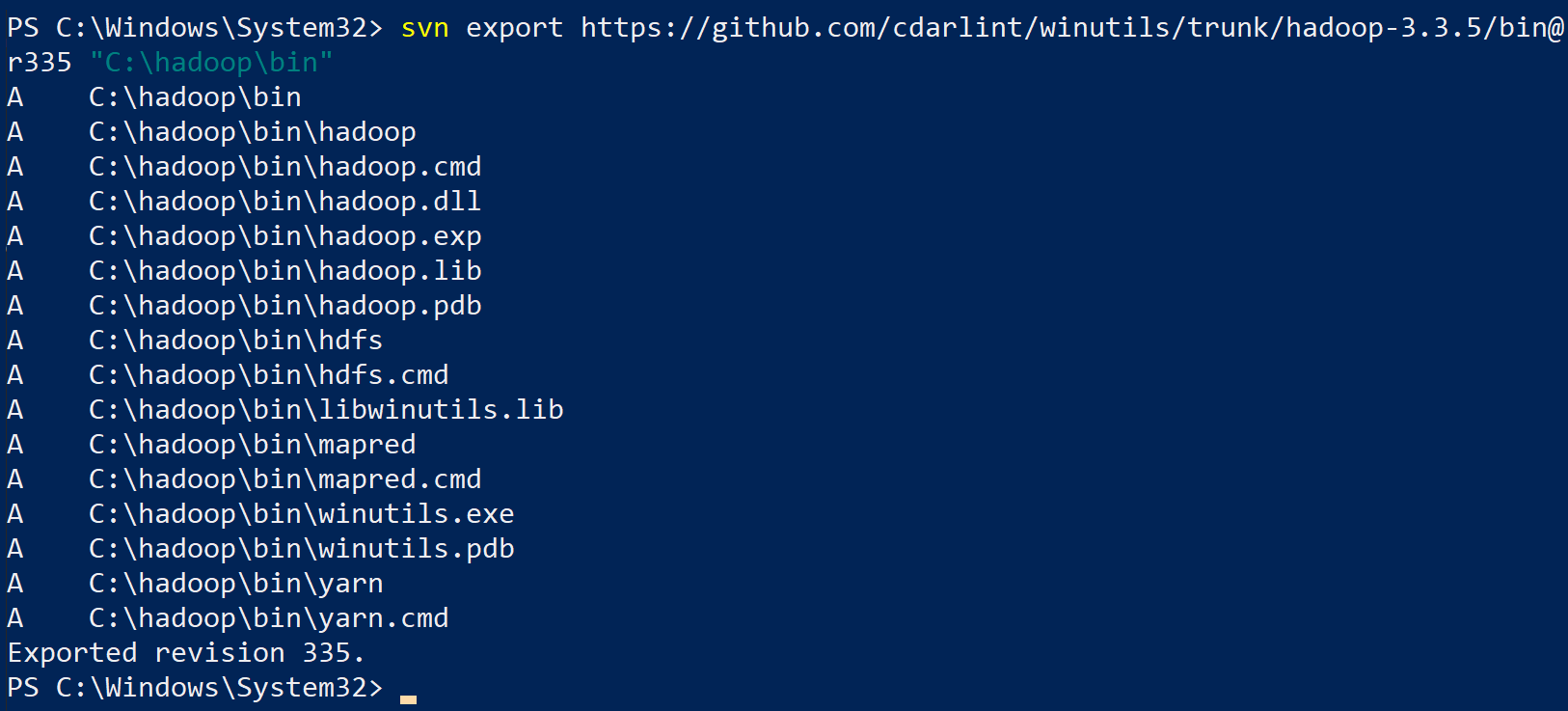
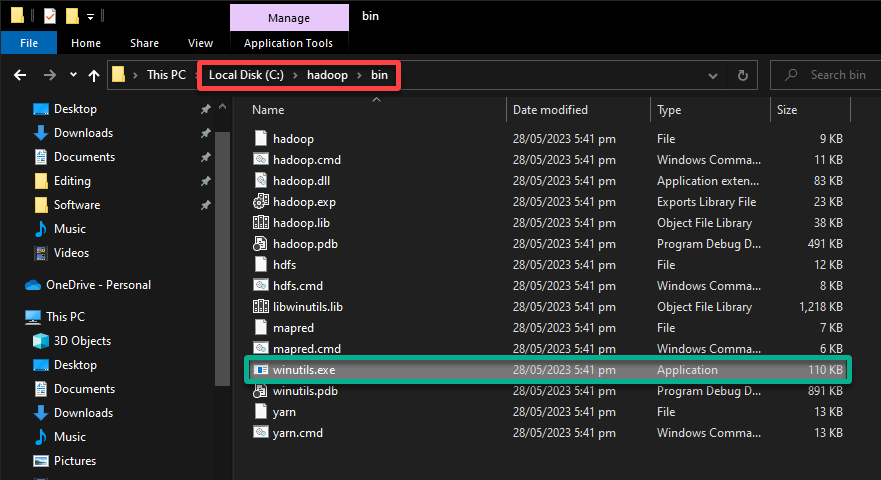
3. Once downloaded, navigate to the C:\hadoop\bin folder and confirm you have the following structure.
You’ll see files, including the winutils.exe utility, that are necessary to run Hadoop operations on Windows.
Setting an Environment Variable for Hadoop and Spark Integration
Having laid the groundwork by installing the winutils.exe utility, your journey now takes a turn into integration. You’ll set up the HADOOP_HOME environment variable to ensure Spark can locate and use the necessary Hadoop components.
To set the HADOOP_HOME environment variable, carry out the following:
Execute the below Set-Item command to create a new HADOOP_HOME environment variable and set its value to Hadoop’s install location (C:\hadoop).
When successful, this command does not provide output to the console, but you’ll verify the result in the following step.
Set-Item -Path "Env:\HADOOP_HOME" -Value 'C:\hadoop'Next, run the following command to verify the HADOOP_HOME environment variable.
The command returns the value of the HADOOP_HOME environment variable, which in this case is Hadoop’s install location (C:\hadoop).

HADOOP_HOME variableLaunching Spark Shells for Interactive Spark Programming
With a fine-tuned environment for seamless Hadoop and Spark integration, prepare yourself for interactive Spark programming. You’ll launch Spark Shells, an interactive command-line interface (CLI) provided by Apache Spark.
Spark Shells allow you to interactively work with Spark, where you can execute Spark jobs and explore your data via Spark’s APIs.
Below are the two main Spark Shells, depending on your preferred programming language:
| Spark Shell | Details |
|---|---|
| Scala Spark Shell | Scala is the default Spark Shell and is primarily used for writing Spark applications in the Scala programming language. |
| PySpark Shell | PySpark is the Python API for Apache Spark, and the PySpark Shell is used for writing Spark applications in Python. This Spark Shell is similar to the Scala Spark Shell but for Python developers. |
To launch Spark Shells, execute the following:
1. Run each Set-Item command below to set environment variables for Spark Shell and PySpark Shell (i.e., SPARK_SH and PY_SPARK). These commands have no output on the console but set environment variables to store the full paths of both shells, respectively.
Ensure you replace the full paths (C:\spark\spark-3.5.0-bin-hadoop3\bin\) with where you unzipped Spark, followed by the shells (spark-shell and pyspark).
This one-time process saves time and is convenient as you can quickly launch either of the shells without typing or specifying the full path each time.
Set-Item -Path "Env:\SPARK_SH" -Value 'C:\spark\spark-3.5.0-bin-hadoop3\bin\spark-shell'
Set-Item -Path "Env:\PY_SPARK" -Value 'C:\spark\spark-3.5.0-bin-hadoop3\bin\pyspark' 2. Next, execute the below Start-Process command to launch the Scala Spark Shell ($env:SPARK_SH).
You only need to call the environment variable that holds the Scala Spark Shell’s full path instead of manually typing everything.
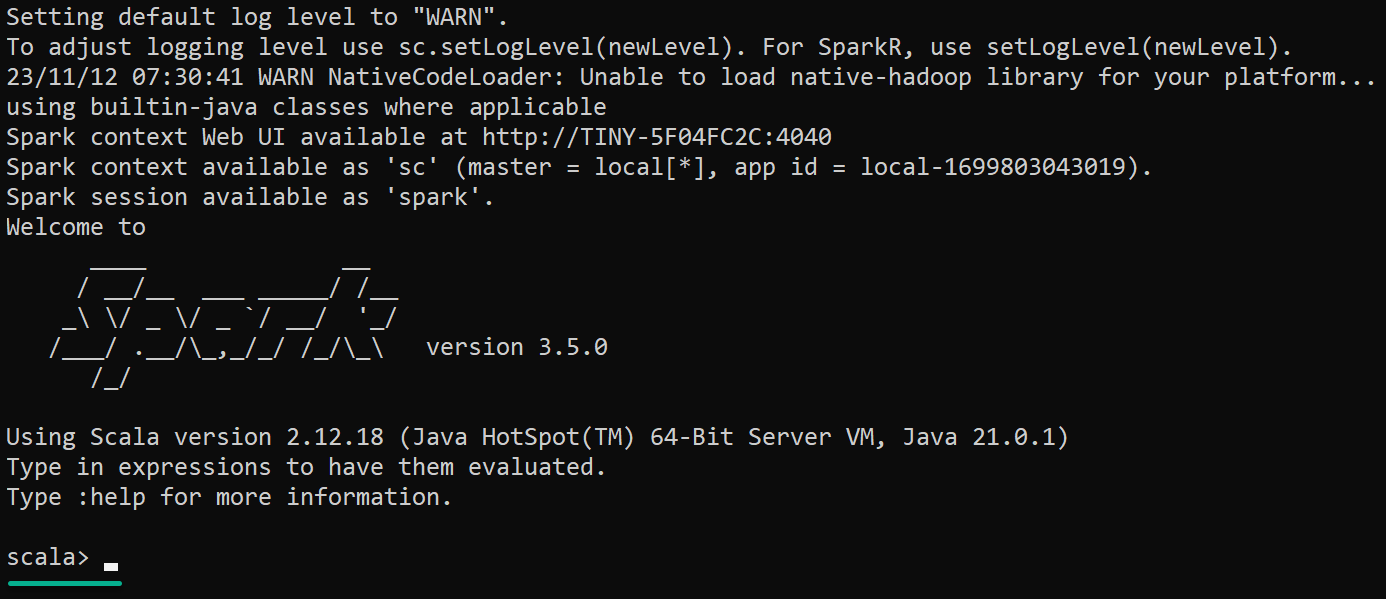
Start-Process $env:SPARK_SHAs you launch the Scala Spark Shell, a new console opens where you’ll see the Scala Read-Eval-Print Loop (REPL) prompt (scala>). This prompt lets you interactively enter and execute Scala code with access to Spark APIs.
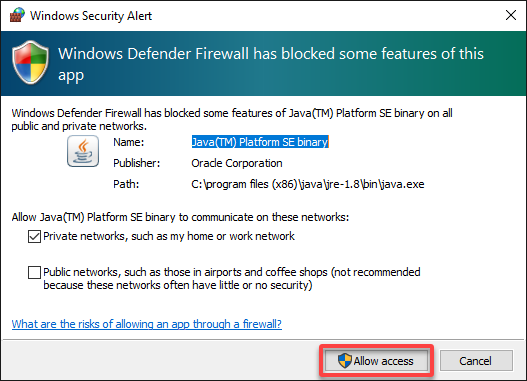
3. When prompted, click Allow access Java through Windows firewall, as shown below. Otherwise, you may encounter issues launching the Spark Shell.
This prompt appears since Apache Spark uses a Java-based web server, Jetty, to display its Web UIs.
4. Now, switch back to the previous PowerShell console and execute the following command to launch the PySpark Shell ($env:PY_SPARK).
Like with the Scala Spark Shell, you only need to call the environment variable that holds the full path of the PySpark Shell.
Start-Process $env:PY_SPARKThe PySpark Shell opens in another console, where you’ll see the Python REPL prompt (>>>). This prompt lets you interactively enter and execute Python code with access to Spark’s PySpark API.
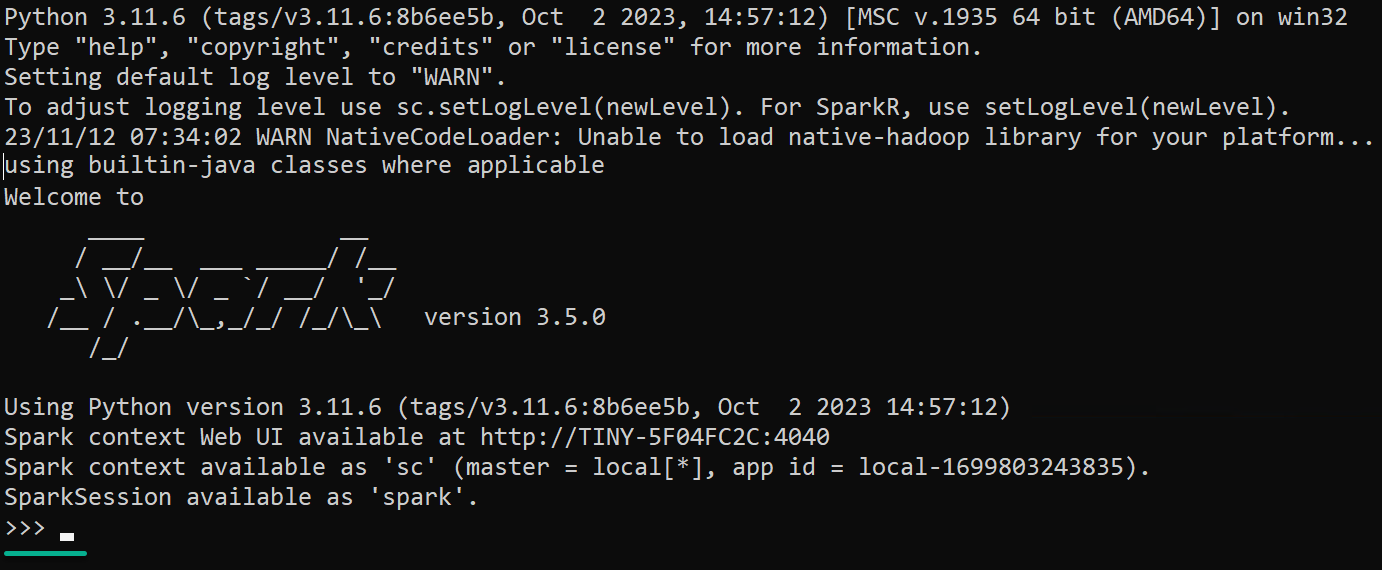
5. Press Ctrl+D, regardless of which shell you launched, to exit the shell, which also closes the console.
Testing Your Spark Setup with Real-world Examples
After venturing into the dynamic realm of launching Spark Shells for interactive programming, the time has come to put your Spark setup to the test.
In this example, you’ll perform a basic analysis of a CSV file containing information about movie ratings via PySpark’s DataFrame API.
To test your Spark setup, perform these steps:
1. Download the sample CSV file containing movie ratings to a directory of your choice (i.e., C:\logs\movie_ratings.csv). Remember the full path, as you will need it for the following step.
2. Next, launch the PySpark shell and run the following command, which has no output but loads the CSV data (movie_ratings.csv) into a DataFrame.
Replace the path (C:\\logs\\movie_ratings.csv) with the one where you saved the sample CSV file in step one.
df = spark.read.csv("C:\\logs\\movie_ratings.csv", header=True, inferSchema=True)3. Afterward, run the below commands to perform basic data exploration tasks.
# Show the first few rows of the DataFrame
df.show()
# Display the schema of the DataFrame
df.printSchema()
# Compute basic statistics of the "rating" column
df.describe("rating").show()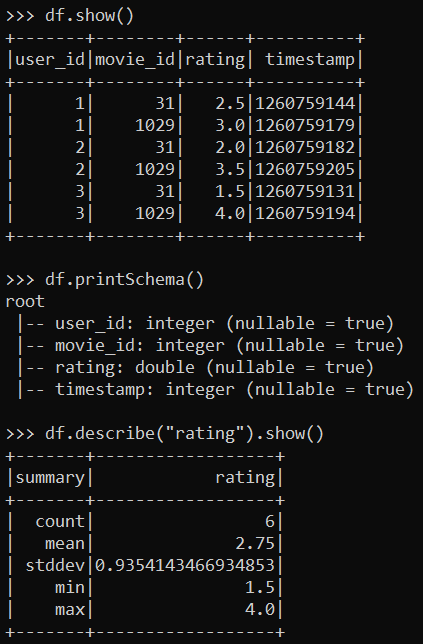
4. Lastly, run each command below to perform a basic data analysis task that calculates the average rating for each movie.
# Import necessary functions
from pyspark.sql.functions import avg
# Calculate the average rating for each movie
average_ratings = df.groupBy("movie_id").agg(avg("rating").alias("avg_rating"))
average_ratings.show()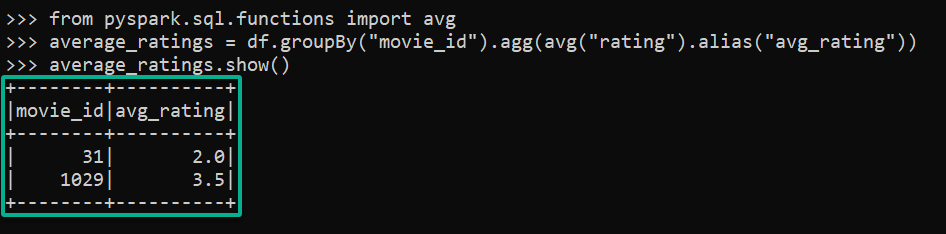
Conclusion
You’ve successfully navigated the twists and turns of setting up Apache Spark on your Windows machine. Moreover, you seamlessly integrated Spark with Hadoop, launched Spark Shells, and tested your Spark setup with real-world examples. Throughout this journey, here you stand, having conquered each step with resilience and determination.
Armed with a Windows environment primed for data analysis, consider this stage as just the beginning. Continue experimenting with diverse datasets to refine your skills. Now, why not consider exploring advanced Spark features, such as creating Resilient Distributed Datasets (RDDs), distributed processing, and parallel computing?
Spark has a rich set of APIs for various programming languages like Scala, Python, Java, R, and SQL. Use these APIs to develop robust data applications to process massive datasets in real-time!
Apache Spark is a powerful, open-source data processing framework that enables fast and efficient analysis of large datasets. It provides a unified engine for distributed data processing, supporting batch processing, real-time streaming, machine learning, and graph processing. Installing Apache Spark on Windows allows developers and data scientists to leverage its capabilities on their local machines, facilitating development, testing, and experimentation.
This guide presents a step-by-step approach to install Spark Windows, covering the necessary prerequisites, downloading and extracting the Spark distribution, setting up environment variables, configuring Spark, and running Spark applications. It also explores integrating Spark with popular IDEs and addresses common issues that may arise during the installation process.
By following this guide, you will gain the ability to harness the power of Apache Spark on your Windows machine, enabling you to process and analyze large datasets efficiently, build machine learning models, and develop data-driven applications.
Downloading and Installing Apache Spark on Windows
Apache Spark is a unified analytics engine for large-scale data processing, offering high-level APIs in Java, Python, and Scala. To begin working with Spark on your Windows machine, you need to download and install the appropriate Spark binary package. This section provides a detailed, step-by-step guide to downloading and installing Apache Spark on your Windows operating system.
Prerequisites
Before proceeding with the installation, ensure you have Java Development Kit (JDK) 8 or later installed. Spark relies on Java for execution, so a compatible JDK is essential. You can download the appropriate JDK installer from the Oracle website or adopt an open-source distribution like OpenJDK.
Once install Java on Windows, set the JAVA_HOME environment variable to your JDK installation path and add the JDK’s bin directory to your system’s PATH environment variable. This ensures that your system can locate and execute Java commands required by Spark.
Before Spark download for Windows, it’s essential to verify that Java is correctly installed and configured in your environment variables. Failing to do so may result in errors when attempting to run Spark commands. To verify your Java installation, open a new Command Prompt window and type:
java --version

If Java is installed and configured correctly, the command prompt will display the installed Java version.
Step 1: Download the Apache Spark Binary Package
To download the Apache Spark binary package, you need to open a web browser and navigate to the official Apache Spark download page.
On the downloads page, you’ll see a dropdown menu listing available Spark versions. Select the specific Spark version you want to install. For this tutorial, we’ll use Spark 3.5.1, the latest version at the time of writing. However, you can choose a different version based on your project requirements and compatibility needs.
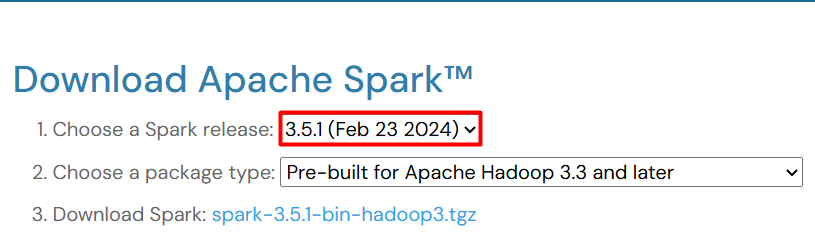
Under the chosen Spark version, locate the “Pre-built for Apache Hadoop” section. This section offers packages bundled with a specific Hadoop version. Select the Hadoop version that aligns with your environment or choose a “Hadoop free” option if you don’t require Hadoop integration. Here, we’ll proceed with “Pre-built for Apache Hadoop 3.3 and later” for demonstration purposes.
Click on the download link corresponding to your chosen Spark version, Hadoop distribution, and package format. This action will start downloading the Spark binary package to your computer.
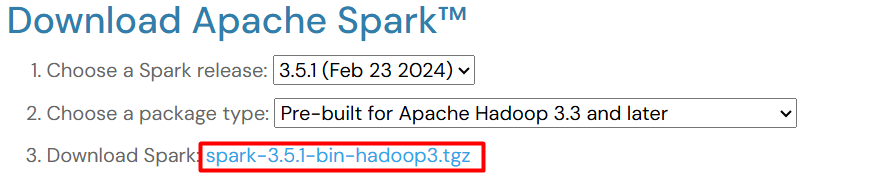
Step 2: Extract the Spark Binary Package
Once the Spark binary package download is complete, you need to extract its contents to a desired directory on your Windows system. Open File Explorer and navigate to the directory where you install Spark on Windows 10.
Right-click on the downloaded Spark package file and select “Extract All” or “Extract Here” from the context menu. This action will initiate the extraction process.
A dialog box will appear, prompting you to choose a destination folder for extracting the Spark files. Select a suitable directory on your system where you want to install Spark. Consider creating a dedicated folder, such as “spark” within your C:\ drive, for a structured installation.
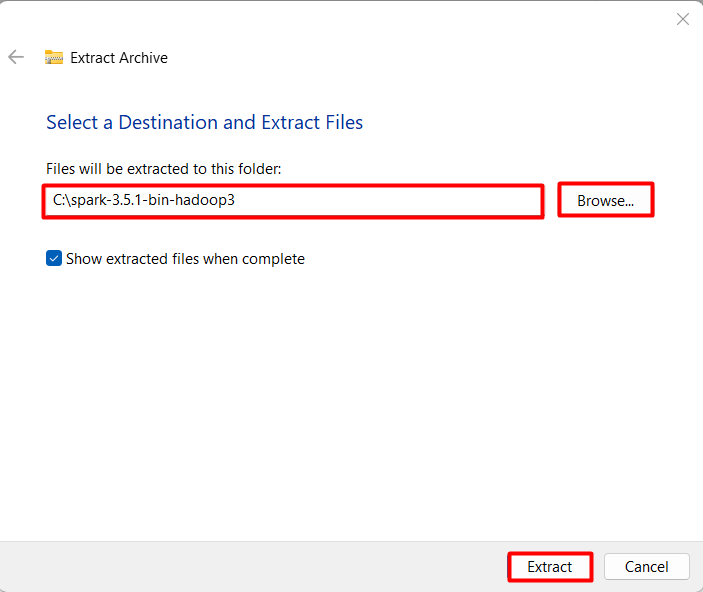
After selecting the destination folder, click the “Extract” button. The extraction process might take a few minutes, depending on your system’s processing speed and the chosen archive format. Larger archives and slower systems might take longer to extract.
Install Spark on Our Fast Windows VPS
With Ultahost, Hosting Windows VPS has never been easier or faster. Enjoy ultra-fast SSD NVMe speeds with no dropouts and slowdowns
Step 3: Set the Environment Variable
Setting the appropriate environment variable is crucial for your Windows system to locate and utilize the installed Spark distribution.
To do that first launch the environment variables settings by searching it on the start menu:
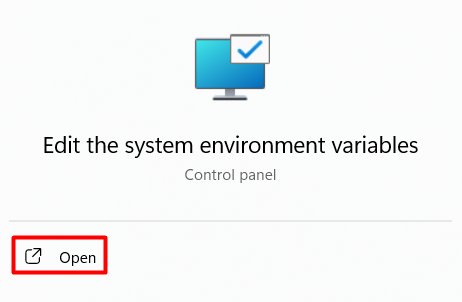
In the System Properties window, navigate to the “Advanced” tab and click on the “Environment Variables” button located at the bottom of the tab. This action opens the “Environment Variables” window, allowing you to manage user and system variables:
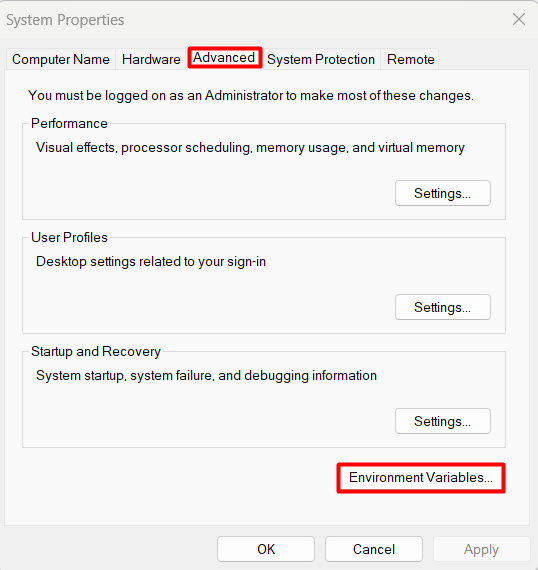
In the “Environment Variables” window, locate the “System variables” section and click the “New” button. This action will open the “New System Variable” window, where you can define a new system variable.
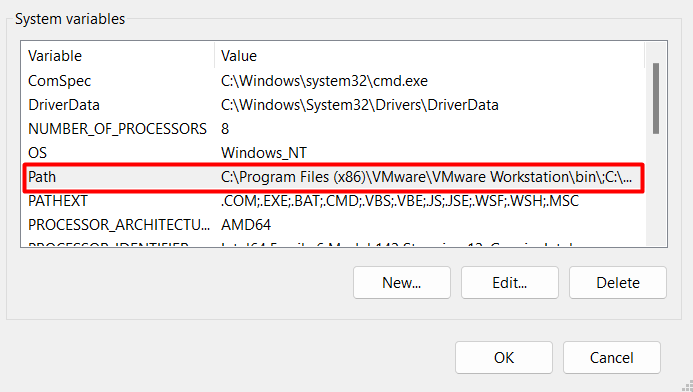
In the “Edit environment variable” window, click the “New” button and add the following path: %SPARK_HOME%\bin. This addition ensures that your system can locate and execute Spark’s executable files:
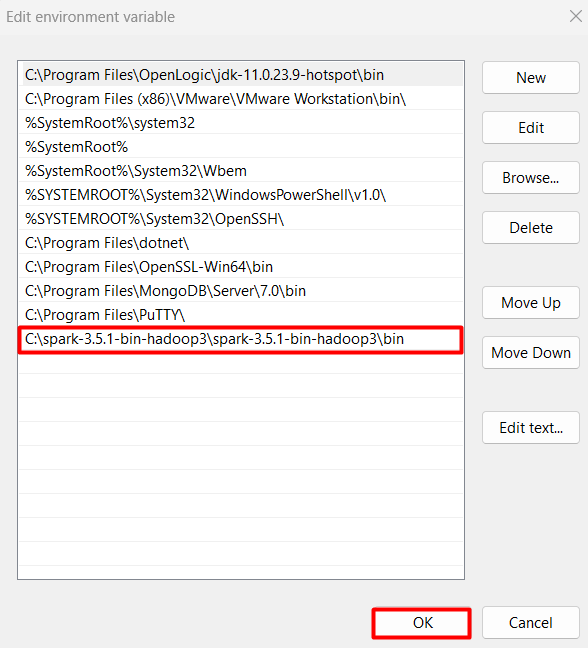
Click “OK” on all open windows to save the environment variable changes. Closing these windows without saving will discard any modifications made to the environment variables.
Step 4: Verify Apache Spark Installation
Before downloading Apache Spark on Windows you need to make sure that Java is installed and placed in the environment variables. Otherwise, you may get a similar error:

So, if you performed every step correctly and if Java is also properly installed then you should get this output. To run Spark on Windows:
spark-shell --version
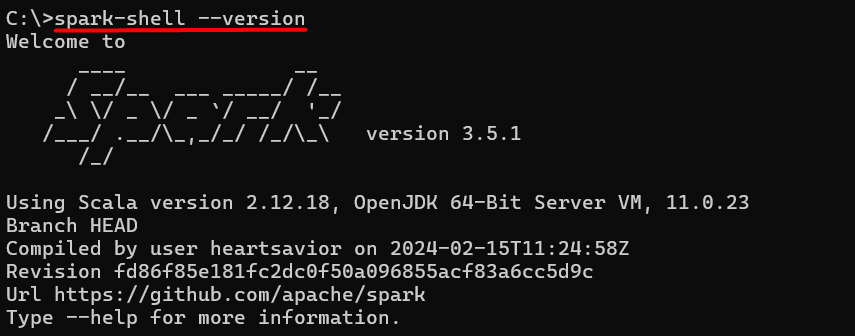
If Spark is installed and configured correctly, the command prompt will display the Spark version you downloaded and installed. This output confirms that your system recognizes the spark-shell command, indicating a successful installation.
Conclusion
Installing Apache Spark on Windows requires a systematic approach to ensure a successful setup. The process begins with downloading the Spark binary package from the official Apache Spark website, selecting the correct package type and download format, and extracting the package to a directory on the Windows system. Next, setting the Spark path in the environment variable is crucial to configure Spark correctly. This involves updating the system environment variables and verifying that the variable is set correctly.
By following these steps, users can successfully install Apache Spark on Windows. The key takeaways from this installation guide are to select the correct Spark version and package type, extract the package to a directory with sufficient disk space, set the Spark environment variable, and verify Java installation. With these steps, users can ensure a smooth installation process and start exploring the features and capabilities of Apache Spark.
If you are a developer or starting your journey consider that you ensure your current setup can handle the demands of your specific needs. This is where you need a powerful and reliable platform like Ultahost. We provide affordable VPS hosting which helps to manage your server and dedicated resources for guaranteed speed and stability to perform your required task.
FAQ
What are the prerequisites for installing Apache Spark on Windows?
- You need the following:
- Java Development Kit (JDK) installed and configured (version 8 or later).
- Hadoop installed and configured (for HDFS and YARN support, if needed).
- Python installed (if you plan to use PySpark).
- Scala installed (if you plan to use Spark with Scala).
How do I install the Java Development Kit (JDK) on Windows?
- Follow these steps:
- Download the JDK installer from the Oracle JDK website.
- Run the installer and follow the on-screen instructions.
- Set the JAVA_HOME environment variable to the JDK installation path.
Add JAVA_HOME\bin to the PATH environment variable.
How do I download and install Apache Spark on Windows?
- Here are the steps:
- Go to the Apache Spark download page.
- Choose a Spark release and package type (pre-built for Hadoop).
- Download the Spark binary and extract the files to a directory of your choice.
- Set the SPARK_HOME environment variable to the Spark directory.
- Add SPARK_HOME\bin to the PATH environment variable.
How do I configure Hadoop on Windows (optional)?
- Follow these steps if you need Hadoop support:
- Download the pre-built Hadoop binaries for Windows from a reliable source.
- Extract the files and set the HADOOP_HOME environment variable to the Hadoop directory.
- Add HADOOP_HOME\bin to the PATH environment variable.
Configure the winutils.exe file in the Hadoop bin directory
How do I install Python on Windows?
- Follow these steps:
- Download the Python installer from the official Python website.
- Run the installer and ensure to check the option “Add Python to PATH”.
- Verify the installation by running python –version in the command prompt.
Spark 3.0.0 was release on 18th June 2020 with many new features. The highlights of features include adaptive query execution, dynamic partition pruning, ANSI SQL compliance, significant improvements in pandas APIs, new UI for structured streaming, up to 40x speedups for calling R user-defined functions, accelerator-aware scheduler and SQL reference documentation.
This article summarizes the steps to install Spark 3.0 on your Windows 10 environment.
Tools and Environment
- GIT Bash
- Command Prompt
- Windows 10
- Python
- Java JDK
Install Git Bash
Download the latest Git Bash tool from this page: https://git-scm.com/downloads.
Run the installation wizard to complete the installation.
Install Java JDK
Spark 3.0 runs on Java 8/11. You can install Java JDK 8 based on the following section.
Step 4 — (Optional) Java JDK installation
If Java 8/11 is available in your system, you don’t need install it again.
Install Python
Python is required for using PySpark. Follow these steps to install Python.
1) Download and install python from this web page: https://www.python.org/downloads/.
2) Verify installation by running the following command in Command Prompt or PowerShell:
python --version
The output looks like the following:

If python command cannot be directly invoked, please check PATH environment variable to make sure Python installation path is added:
For example, in my environment Python is installed at the following location:
Thus path C:\Users\Raymond\AppData\Local\Programs\Python\Python38-32 is added to PATH variable.
Hadoop installation (optional)
To work with Hadoop, you can configure a Hadoop single node cluster following this article:
Install Hadoop 3.3.0 on Windows 10 Step by Step Guide
Download binary package
Go to the following site:
https://spark.apache.org/downloads.html
Select the package type accordingly. I already have Hadoop 3.3.0 installed in my system, thus I selected the following:
You can choose the package with pre-built for Hadoop 3.2 or later.
Save the latest binary to your local drive. In my case, I am saving the file to folder: F:\big-data. If you are saving the file into a different location, remember to change the path in the following steps accordingly.
Unpack binary package
Open Git Bash, and change directory (cd) to the folder where you save the binary package and then unzip using the following commands:
$ mkdir spark-3.0.0 $ tar -C spark-3.0.0 -xvzf spark-3.0.0-bin-without-hadoop.tgz --strip 1
The first command creates a sub folder named spark-3.0.0; the second command unzip the downloaded package to that folder.
warning Your file name might be different from spark-3.0.0-bin-without-hadoop.tgz if you chose a package with pre-built Hadoop libs.
Spark 3.0 files are now extracted to F:\big-data\spark-3.0.0.
Setup environment variables
1) Setup JAVA_HOME variable.
Setup environment variable JAVA_HOME if it is not done yet. The variable value points to your Java JDK location.
2) Setup SPARK_HOME variable.
Setup SPARK_HOME environment variable with value of your spark installation directory.
3) Update PATH variable.
Added ‘%SPARK_HOME%\bin’ to your PATH environment variable.
4) Configure Spark variable SPARK_DIST_CLASSPATH.
This is only required if you configure Spark with an existing Hadoop. If your package type already includes pre-built Hadoop libraries, you don’t need to do this.
Run the following command in Command Prompt to find out existing Hadoop classpath:
F:\big-data>hadoop classpath F:\big-data\hadoop-3.3.0\etc\hadoop;F:\big-data\hadoop-3.3.0\share\hadoop\common;F:\big-data\hadoop-3.3.0\share\hadoop\common\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\common\*;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs\*;F:\big-data\hadoop-3.3.0\share\hadoop\yarn;F:\big-data\hadoop-3.3.0\share\hadoop\yarn\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\yarn\*;F:\big-data\hadoop-3.3.0\share\hadoop\mapreduce\*
Setup an environment variable SPARK_DIST_CLASSPATH accordingly using the output:
Config Spark default variables
Run the following command to create a default configuration file:
cp %SPARK_HOME%/conf/spark-defaults.conf.template %SPARK_HOME%/conf/spark-defaults.conf
Open spark-defaults.conf file and add the following entries:
spark.driver.host localhost
Now Spark is available to use.
Verify the installation
Let’s run some verification to ensure the installation is completed without errors.
Verify spark-shell command
Run the following command in Command Prompt to verify the installation.
spark-shell
The screen should be similar to the following screenshot:
You can use Scala in this interactive window.
Run examples
Execute the following command in Command Prompt to run one example provided as part of Spark installation (class SparkPi with param 10).
https://spark.apache.org/docs/latest/
%SPARK_HOME%\bin\run-example.cmd SparkPi 10
The output looks like the following:
PySpark interactive window
Run the following command to try PySpark:
pyspark
Python in my environment is 3.8.2.
Try Spark SQL
Spark SQL interactive window can be run through this command:
spark-sql
As I have not configured Hive in my system, thus there will be error when I run the above command.
Spark context UI
When a Spark session is running, you can view the details through UI portal. As printed out in the interactive session window, Spark context Web UI available at http://localhost:4040. The URL is based on the Spark default configurations. The port number can change if the default port is used.
The following is a screenshot of the UI:
References
Spark developer tools
Refer to the following page if you are interested in any Spark developer tools.
https://spark.apache.org/developer-tools.html
Spark 3.0.0 overview
Refer to the official documentation about Spark 3.0.0 overview: http://spark.apache.org/docs/3.0.0/.
Spark 3.0.0 release notes
https://spark.apache.org/releases/spark-release-3-0-0.html
check Congratulations! You have successfully configured Spark in your Windows environment. Have fun with Spark 3.0.0.